PowerEdge: AMD Rome — архітектура та початкова продуктивність HPC
Summary: У сучасному світі HPC — це знайомство з процесором останнього покоління AMD EPYC під кодовою назвою Rome.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. Лабораторія інновацій у сфері HPC та ШІ, жовтень 2019 року
У сучасному світі HPC процесор AMD EPYC останнього покоління з кодовою назвою Rome навряд чи потребує представлення. Останні кілька місяців ми оцінювали системи на базі Rome у HPC та AI Innovation Lab
, а Dell Technologies нещодавно оголосила
про сервери, які підтримують цю архітектуру процесорів. Цей перший блог серії Rome розглядає архітектуру процесора Rome, як її можна налаштувати для продуктивності HPC і презентує початкову мікробенчмаркову продуктивність. Наступні блоги описують продуктивність застосувань у сферах CFD, CAE, молекулярної динаміки, моделювання погоди та інших застосувань.
Архітектура
Rome — це процесор другого покоління EPYC від AMD, який оновлює їхній Naples першого покоління.
Однією з найбільших архітектурних відмінностей між Неаполем і Римом, яка вигідна HPC, є новий кристал IO у Римі. У Римі кожен процесор є багаточиповим пакетом, що складається з до дев'яти чіплетів , як показано на рисунку 1. Є один центральний 14-нм IO кристал, який містить усі функції виводу та пам'яті — наприклад, контролери пам'яті, лінки Infinity Fabric у сокеті та міжсокетних з'єднаннях, а також PCI-e. У кожному сокеті вісім контролерів пам'яті, які підтримують вісім каналів пам'яті з DDR4 зі швидкістю 3200 MT/s. Односокетний сервер може підтримувати до 130 ліній PCIe Gen4. Система з двома сокетами може підтримувати до 160 ліній PCIe Gen4.
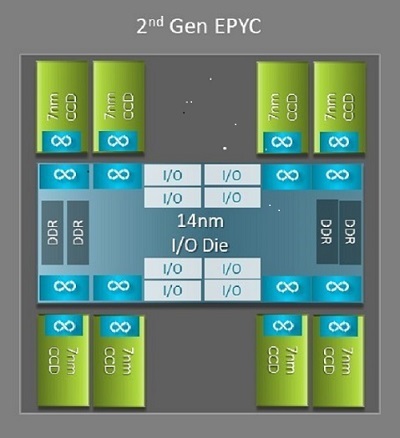
(Рисунок 1: Мультичиповий пакет Rome з одним центральним кристалом введення та до восьмиядерних кристалів)
Навколо центрального кристала IO розташовано до восьми 7-нм ядерних чиплетів. Основний чиплет називається кристалом Core Cache або CCD. Кожен CCD має процесорні ядра на основі мікроархітектури Zen2, кеш L2 та кеш L3 об'ємом 32MB. Сам CCD має два комплекси кешу Core Cache (CCX), кожен CCX має до чотирьох ядер і 16 МБ кешу L3. На рисунку 2 показано CCX.

(Рисунок 2 : CCX з чотирма ядрами та спільним кешом L3 об'ємом 16 МБ)
Різні моделі процесорів Rome мають різну кількість ядер
, але всі мають один центральний кристал виводу.
На верхньому рівні — модель процесора з 64 ядрами, наприклад, EPYC 7702. Вихід Lstopo показує, що цей процесор має 16 CCX на сокет, кожен CCX має чотири ядра, як показано на рисунках 3 і 4, що дає 64 ядра на сокет. 16 МБ L3 на CCX, тобто 32 МБ L3 на CCD, дає процесору 256 МБ кешу L3. Зверніть увагу, що загальний кеш L3 у Rome не поділяється всіма ядрами. Кеш L3 об'ємом 16 МБ у кожному CCX є незалежним і використовується лише між ядрами CCX, як показано на рисунку 2.
24-ядерний процесор, як EPYC 7402, має кеш L3 об'ємом 128 МБ. Вихід Lstopo на рисунках 3 і 4 показує, що ця модель має три ядра на CCX і вісім CCX на сокет.
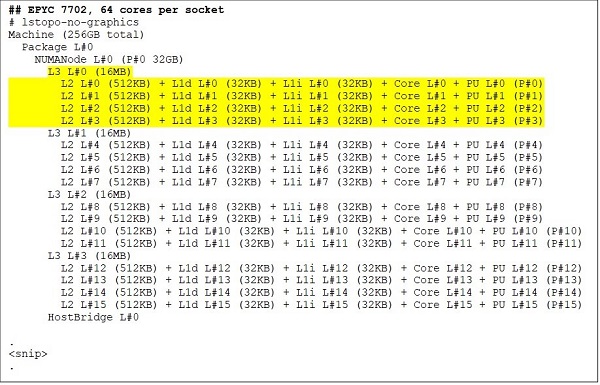
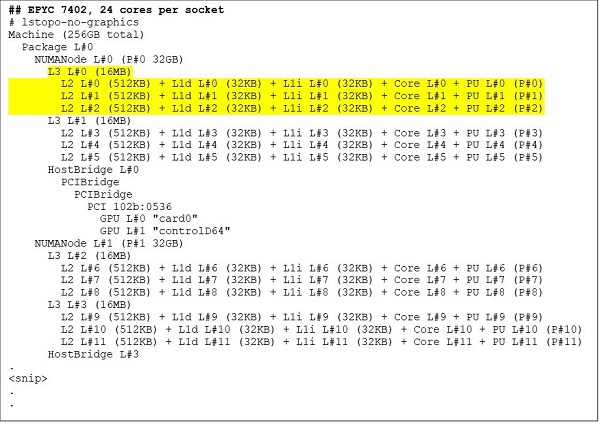
(Рисунок 3 і 4: Вихід Lstopo для 64- та 24-ядерних процесорів)
Незалежно від кількості CCD, кожен процесор Rome логічно поділений на чотири квадранти , при цьому CCD розподілені якомога рівномірніше по квадрантах і два канали пам'яті в кожному квадранті. Центральний кристал IO можна розглядати як логічну підтримку чотирьох квадрантів розетки.
Опції BIOS на основі архітектури Rome
Центральний кристал IO у Римі допомагає покращити затримки пам'яті порівняно з тими, що виміряються в Неаполі. Також це дозволяє налаштувати процесор як єдиний домен NUMA, забезпечуючи рівномірний доступ до пам'яті для всіх ядер у сокеті. Це пояснюється нижче.
Чотири логічні квадранти в процесорі Rome дозволяють розділити процесор на різні домени NUMA. Це налаштування називається NUMA per socket або NPS.
- NPS1 означає, що процесор Rome — це один домен NUMA, з усіма ядрами в сокеті та всією пам'яттю в цьому одному домені NUMA. Пам'ять чергується між восьми каналами пам'яті. Усі пристрої PCIe на сокеті належать цьому єдиному домену NUMA
- NPS2 розділяє процесор на два домени NUMA, причіпляючи половину ядер і половину каналів пам'яті на сокеті в кожному домені NUMA. Пам'ять чергується між чотирма каналами пам'яті в кожному домені NUMA
- NPS4 поділяє процесор на чотири домени NUMA. Кожен квадрант тут є доменом NUMA, і пам'ять чергується між двома каналами пам'яті в кожному квадранті. PCIe-пристрої розташовані локально для одного з чотирьох доменів NUMA на сокеті залежно від того, який квадрант кристала IO має PCIe-корінь для цього пристрою
- Не всі процесори можуть підтримувати всі налаштування NPS
За наявності NPS4 рекомендується для HPC, оскільки очікується забезпечення найкращої пропускної здатності пам'яті, найменших затримок пам'яті, а наші застосунки зазвичай обізнані з NUMA. Якщо NPS4 недоступний, ми рекомендуємо використовувати найвищий NPS, підтримуваний моделлю процесора — NPS2 або навіть NPS1.
Враховуючи велику кількість варіантів NUMA на платформах Риму, BIOS PowerEdge дозволяє використовувати два різні методи перерахунку ядер у рамках MADT перерахування. Лінійне перерахування номерує ядра по порядку, заповнюючи один роз'єм CCX, CCD, перед переходом до наступного. На процесорі 32c ядра з 0 по 31 знаходяться на першому сокеце, а ядра 32-63 — на другому. Круговий перепис нумерує ядра в регіонах NUMA. У цьому випадку парні ядра знаходяться на першому роз'ємі, непарні — на другому. Для простоти ми рекомендуємо лінійний перелік для HPC. Дивіться Рисунок 5 для прикладу лінійного підрахунку ядер на сервері з двома сокетами 64c, налаштованому в NPS4. На рисунку кожна коробка з чотирма ядрами є CCX, кожен набір із восьми суміжних ядер — CCD.
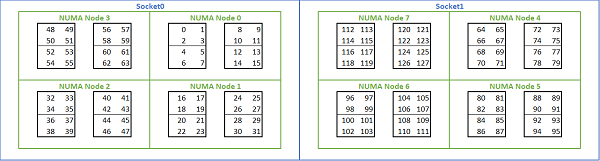
(Рисунок 5 Лінійне перелічення ядер на системі з двома сокетами, 64c на сокет, конфігурація NPS4 на восьми CCD-процесорах)
Ще один специфічний для Rome варіант BIOS називається Preferred IO Device. Це важлива ручка налаштування для пропускної здатності та швидкості повідомлення InfiniBand. Це дозволяє платформі пріоритезувати трафік для одного пристрою виводу. Ця опція доступна на платформах Rome з одним і двома сокетами, і пристрій InfiniBand на платформі має бути обраний як пріоритетний пристрій у меню BIOS, щоб досягти повної швидкості повідомлення, коли всі ядра процесора активні.
Подібно до Неаполя, Rome також підтримує гіперпотоковеабо логічний процесор. Для HPC ми залишаємо це вимкненим, але деякі додатки можуть отримати користь від увімкнення логічного процесора. Очікуйте наші наступні блоги про дослідження молекулярної динаміки.
Подібно до Неаполя, Рим також дозволяє CCX як домен NUMA. Ця опція відкриває кожен CCX як вузол NUMA. У системі з двосокетними процесорами та 16 CCX на процесор це налаштування відкриває 32 домени NUMA. У цьому прикладі кожне роз'єм має вісім CCD, тобто 16 CCX. Кожен CCX може бути активований як окремий домен NUMA, що дає 16 вузлів NUMA на сокет, а в системі з двома сокетами — 32. Для HPC ми рекомендуємо залишати CCX як домен NUMA за замовчуванням — вимкнено. Очікується, що ввімкнення цієї опції допоможе у віртуалізованих середовищах.
Подібно до Неаполя, Рим дозволяє встановлювати систему в режимі детермінізму перформансу або детермінізму сили . У детермінізмі продуктивності система працює на очікуваній частоті для моделі процесора, зменшуючи варіабельність між кількома серверами. У Power Determinism система працює на максимальному доступному TDP моделі процесора. Це підсилює варіативність у виробничому процесі, дозволяючи деяким серверам працювати швидше за інші. Усі сервери можуть споживати максимальну номінальну потужність процесора, що робить енергоспоживання детермінованим, але дозволяє певну варіацію продуктивності між кількома серверами.
Як і слід очікувати від платформ PowerEdge, у BIOS є мета-опція під назвою System Profile. Вибір профілю системи Performance-Optimized дозволяє режим турбонаддуву, вимикає C-стани та встановлює повзунок детермінізму на Power Determinism, оптимізуючи для продуктивності.
Результати продуктивності — мікробенчмарки STREAM, HPL, InfiniBand
Багато наших читачів, можливо, одразу перейшли до цього розділу, тож ми одразу занурюємося в роботу.
У Лабораторії інновацій HPC та AI ми створили кластер із 64 серверів у Римі, який називаємо Minerva. Окрім однорідного кластера Minerva, у нас є ще кілька зразків процесорів Rome, які ми могли б оцінити. Наша тестова платформа описана в Таблиці 1 та Таблиці 2.
(Таблиця 1 Rome CPU моделей, оцінених у цьому дослідженні)
| CPU | Ядра на розетку | Конфігурація | Базовий годинник | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4 центи за CCX | 2.0 ГГц | 200W |
| 7502 | 32c | 4 центи за CCX | 2,5 ГГц | 180W |
| 7452 | 32c | 4 центи за CCX | 2,35 ГГц | 155W |
| 7402 | 24c | 3 центи за CCX | 2,8 ГГц | 180W |
(Table.2 Тестовий стенд)
| Компонент | Деталі |
|---|---|
| Сервер | PowerEdge C6525 |
| Процесор | Як показано у Таблиці 1, двосокетний |
| Пам'ять | 256 ГБ, 16x16 ГБ 3200 МТ/с DDR4 |
| Інтерконект | ConnectX-6 Mellanox Infini Band HDR100 |
| Операційна система | Red Hat Enterprise Linux 7.6 |
| Ядро | 3.10.0.957.27.2.e17.x86_64 |
| Диск | 240 GB МОДУЛЬ SATA SSD M.2 |
ПОТІК
Тести пропускної здатності пам'яті на Rome представлені на рисунку 6, ці тести проводилися в режимі NPS4. Ми виміряли пропускну здатність пам'яті ~270-300 ГБ/с на нашому двосокетному PowerEdge C6525, використовуючи всі ядра сервера на чотирьох моделях процесорів, наведених у таблиці 1. Коли на CCX використовується лише одне ядро, пропускна здатність системи пам'яті становить ~9-17% вищу, ніж виміряна з усіма ядрами.
Більшість HPC-навантажень або повністю підписуються на всі ядра системи, або HPC-центри працюють у режимі високої пропускної здатності з кількома завданнями на кожному сервері. Отже, пропускна здатність усіх ядер пам'яті є більш точним відображенням пропускної здатності пам'яті та пропускної здатності пам'яті на ядро системи.
На рисунку 6 також показана пропускна здатність пам'яті, виміряна на платформі попереднього покоління EPYC Naples , яка також підтримувала вісім каналів пам'яті на сокет, але працювала зі швидкістю 2667 MT/s. Платформа Rome забезпечує на 5–19% кращу загальну пропускну здатність пам'яті, ніж Naples, і це здебільшого завдяки швидшій пам'яті 3200 MT/s. Навіть при 64c на сокет, система Rome може забезпечувати понад 2 GB/s на ядро.
Порівнюючи різну конфігурацію NPS, з NPS4 було виміряно ~13% вищу пропускну здатність пам'яті порівняно з NPS1, як показано на рисунку 7.
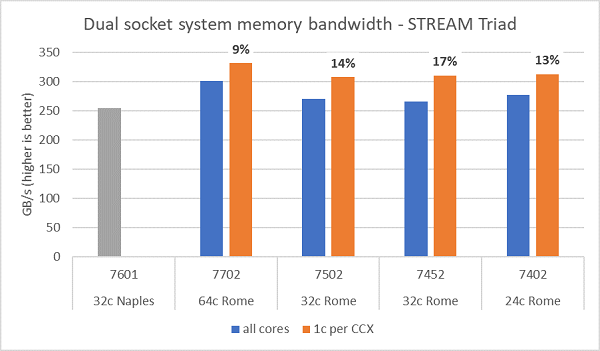
(Рисунок 6 Пропускна здатність пам'яті NPS4 STREAM Triad з двосокетним двигуном)
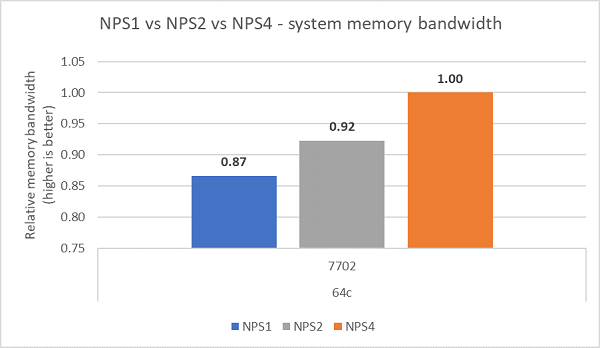
(Рисунок 7 NPS1 проти NPS2 проти NPS 4 Пропускна здатність пам'яті)
Пропускна здатність InfiniBand та швидкість повідомлень
Рисунок 8 показує пропускну здатність одноядерного InfiniBand для односторонніх і двонаправлених тестів. Тестовий стенд використовував HDR100 зі швидкістю 100 Гбіт/с, а графік показує очікувану продуктивність лінійної швидкості для цих тестів.
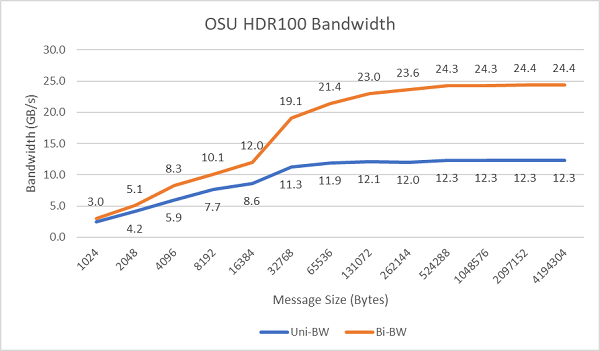
Рисунок 8 Пропускна здатність InfiniBand (одноядерний))
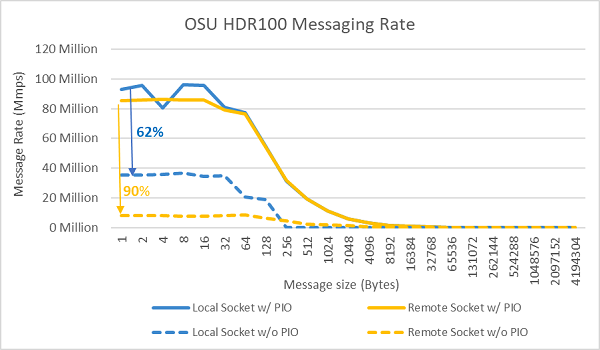
Рисунок 9 Швидкість повідомлень InfiniBand (усі ядра))
Далі проводилися тести швидкості повідомлень, використовуючи всі ядра на сокеті двох серверів, що тестувалися. Коли Preferred IO увімкнено в BIOS і адаптер ConnectX-6 HDR100 налаштований як бажаний пристрій, швидкість повідомлень для всіх ядер вища, ніж коли Preferred IO не увімкнений, як показано на рисунку 9. Це ілюструє важливість цієї опції BIOS при налаштуванні для HPC, особливо для масштабованості багатовузлових додатків.
HPL
Мікроархітектура Rome може вивести з експлуатації 16 DP FLOP/цикл, що вдвічі більше, ніж у Неаполя, яке було 8 FLOPS/цикл. Це дає Rome у 4 рази більше теоретичного піку FLOPS порівняно з Неаполем, у 2 рази завдяки покращеній здатності з плаваючою комою та 2x від подвоєної кількості ядер (64c проти 32c). На рисунку 10 показані виміряні результати HPL для чотирьох моделей процесорів Rome, які ми протестували, разом із нашими попередніми результатами системи з Неаполя. Ефективність Rome HPL позначена як відсоткове значення вище смуг на графіку і вища для моделей процесорів з нижчим TDP.
Тести проводилися в режимі детермінізму потужності, і на 64 ідентично налаштованих серверах вимірювали ~5% дельта продуктивності, отже результати тут знаходяться в цьому діапазоні.
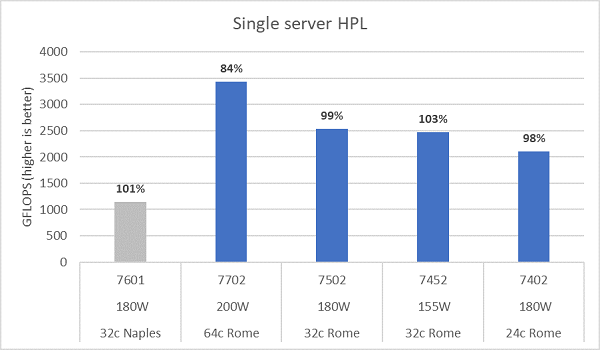
(Рисунок 10 Односерверний HPL у NPS4)
Далі були проведені багатовузлові HPL-тести, які наведені на рисунку 11. Ефективність HPL для EPYC 7452 залишається вище 90% на шкалі з 64 вузлами, але падіння ефективності з 102% до 97% і знову до 99% потребують подальшої оцінки.
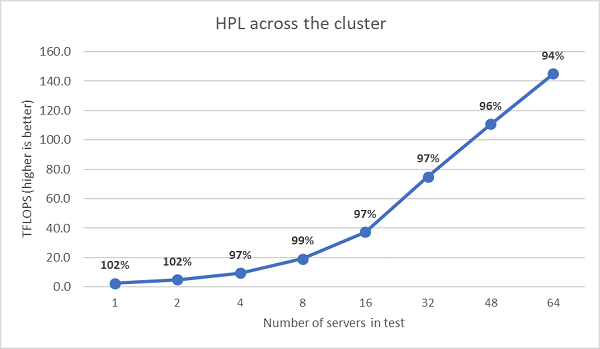
(Рисунок 11 : Багатовузловий HPL, двосокетний EPYC 7452 над HDR100 InfiniBand)
Резюме та що буде далі:
Початкові дослідження продуктивності серверів у Римі показують очікувану продуктивність нашого першого набору бенчмарків HPC. Налаштування BIOS важливе при налаштуваннях для найкращої продуктивності, а опції налаштування доступні в нашому профілі навантаження BIOS HPC, які можна налаштувати до заводських налаштувань або встановити за допомогою утиліт управління системами Dell EMC.
Лабораторія інновацій у сфері HPC та AI має новий кластер PowerEdge Minerva, що базується на 64 сервери в Римі. Слідкуйте за наступними блогами, які описують дослідження продуктивності додатків у нашому новому кластері Minerva.