Yep thats right whats been identified by the lazy writer is invalidated when the SQL server service stopped.
When the SQL Server service is started is goes through a recovery process and there are two types of recovery both having the aim of making sure the logs and data agree.
Restart Recovery (also known as Crash Recovery): Occurs every time SQL Server is restarted. The process runs on each database as each DB has its own transaction log (SQL Server 2008 uses multiple threads to process the recovery operations on the different databases simultaneously to speed recovery)
Restore Recovery: Occurs when a restore operation is executed. This process makes sure all the committed transactions in the backup of the transaction log are reflected in the data and any tranactions that did not commit do not show up in the data.
We have three recovery models for database, Full, Bulk-logged and simple.
Recovery model
Description
Work loss exposure
Recover to point in time?
Simple
No log backups.
Automatically reclaims log space to keep space requirements small, essentially eliminating the need to manage the transaction log space.
Changes since the most recent backup are unprotected. In the event of a disaster, those changes must be redone.
Can recover only to the end of a backup.
Full
Requires log backups.
No work is lost due to a lost or damaged data file.
Can recover to an arbitrary point in time (for example, prior to application or user error).
Normally none.
If the tail of the log is damaged, changes since the most recent log backup must be redone. For more information, see Tail-Log Backups.
If the log is damaged or bulk-logged operations occurred since the most recent log backup, changes since that last backup must be redone.
Otherwise, no work is lost.
Can recover to the end of any backup. Point-in-time recovery is not supported.
Phases of recovery
the recovery algorithm has 3 phases based around the last checkpoint in the transaction log.
Phase 1: Analysis. Starts at the last checkpoint in transaction log. This pass determines and constructs a dirty page table (DPT) consisting of pages that might be dirty at the time SQL Server stopped. An active transaction table is built of the uncommitted transactions at the time of the SQL Server stopped also.
Phase 2: Redo. This phase returns teh database to the state at the time the SQL service stopped. Starting point for this forward passbeing the oldest uncommitted transaction. The mininum Log Sequence name (each log record is labelled with an LSN) in the DPT is the first time SQL Server expects to have to redo an operation on a page, redoing the logged operations starting right back at the oldest open transaction so that the neccessary locks can be aquired.
Phase 3: Undo: Here the list of active transaction (uncommitted at the time SQL Server stoopped) which where indentified in Phase 1 are rolled back individually. SQL Server follows the links between entries in the transaction log for each transaction. Any transaction that was not committed at the time SQL Server stopped is undone.
What is important to understand is the relationships between many of these features. But it all starts with a transaction.
When a change occurs within a SQL Server environment, this will always occur within the context of a transaction - either explicitly in code or implicitly. Changes to pages will obviously occur and when the transaction commit occurs, then you get a synchronous write to the transaction log. All the information with respect to the transaction is now persisted in the log. The data represnting the change to the data file may not be immediately written to disk. If the system failed at this point, the correct data would be reconstructed from information in the transaction log (roll forward/roll back recovery at restart)
Lazy writers are simply responsible for writing out the dirty pages for the data files. These may be changes that resulted from a commited transaction where the data was not previously written out. The Lazy Writer is only trying to free up SQL Server buffer pool space, so that it can be used for other transactions. It does not really have anything to do with transactional consistency.
Then there's the CheckPoint. This is a point of syncronization between the transaction log AND the data files. When a checkpoint happens, the goal is to write every change out to the data files (remember the log is synchronous, so it's always up to date). The fact that a checkpoint has completed is also written to the log. Checkpoints occur when the system needs to get to a consistent point in time for both data and log files - classic example is prior to attempting to make a disk mirror split operation (VDI/VSS). Checkpoints also happen based on configurations settings in the SQL Server environment (recovery time interval). The Checkpoint is the last point in time that the restart recovery process would need to go back to, to do the rollback/rollforward recovery.
The important part here is that it's the data in the transaction log that is used to resolve any changes to the data files, and this is not necessairly affected by the lazy writer or Checkpoint. The combination of data files and transaction log gets the DB back to a consistent point in time.
Tx has posted a great answer, the lazy writer is reallty invalidated during recovery, I was in middle of replying so wont repeat but here are some useful links
There is a good presentation stepping through the process available on the web, will try and dig out, had a look but couldnt find but will try again tomorrow.
The lazywriter thread sleeps for a specific interval of time. When it is restarted, it examines the size of the free buffer list. If the free buffer list is below a certain point, dependent on the size of the cache, the lazywriter thread scans the buffer cache to reclaim unused pages. The difference between lazy write and checkpoint is below:
Thanks all for your attendtion and experties! Lazy writer is actually not a role in recovery. Please refer to the below link for detail on difference between Checkpoint and Lazy Write.



Michael_Morris
18 Posts
0
January 12th, 2012 05:00
Hi Zhao
Yep thats right whats been identified by the lazy writer is invalidated when the SQL server service stopped.
When the SQL Server service is started is goes through a recovery process and there are two types of recovery both having the aim of making sure the logs and data agree.
Restart Recovery (also known as Crash Recovery): Occurs every time SQL Server is restarted. The process runs on each database as each DB has its own transaction log (SQL Server 2008 uses multiple threads to process the recovery operations on the different databases simultaneously to speed recovery)
Restore Recovery: Occurs when a restore operation is executed. This process makes sure all the committed transactions in the backup of the transaction log are reflected in the data and any tranactions that did not commit do not show up in the data.
We have three recovery models for database, Full, Bulk-logged and simple.
Recovery model
Description
Work loss exposure
Recover to point in time?
Simple
No log backups.
Automatically reclaims log space to keep space requirements small, essentially eliminating the need to manage the transaction log space.
Changes since the most recent backup are unprotected. In the event of a disaster, those changes must be redone.
Can recover only to the end of a backup.
Full
Requires log backups.
No work is lost due to a lost or damaged data file.
Can recover to an arbitrary point in time (for example, prior to application or user error).
Normally none.
If the tail of the log is damaged, changes since the most recent log backup must be redone. For more information, see Tail-Log Backups.
Can recover to a specific point in time, assuming that your backups are complete up to that point in time. For more information, see Restoring a Database to a Point Within a Backup.
Bulk logged
Requires log backups.
An adjunct of the full recovery model that permits high-performance bulk copy operations.
Reduces log space usage by using minimal logging for most bulk operations. For more information, see Operations That Can Be Minimally Logged.
If the log is damaged or bulk-logged operations occurred since the most recent log backup, changes since that last backup must be redone.
Otherwise, no work is lost.
Can recover to the end of any backup. Point-in-time recovery is not supported.
Phases of recovery
the recovery algorithm has 3 phases based around the last checkpoint in the transaction log.
Phase 1: Analysis. Starts at the last checkpoint in transaction log. This pass determines and constructs a dirty page table (DPT) consisting of pages that might be dirty at the time SQL Server stopped. An active transaction table is built of the uncommitted transactions at the time of the SQL Server stopped also.
Phase 2: Redo. This phase returns teh database to the state at the time the SQL service stopped. Starting point for this forward passbeing the oldest uncommitted transaction. The mininum Log Sequence name (each log record is labelled with an LSN) in the DPT is the first time SQL Server expects to have to redo an operation on a page, redoing the logged operations starting right back at the oldest open transaction so that the neccessary locks can be aquired.
Phase 3: Undo: Here the list of active transaction (uncommitted at the time SQL Server stoopped) which where indentified in Phase 1 are rolled back individually. SQL Server follows the links between entries in the transaction log for each transaction. Any transaction that was not committed at the time SQL Server stopped is undone.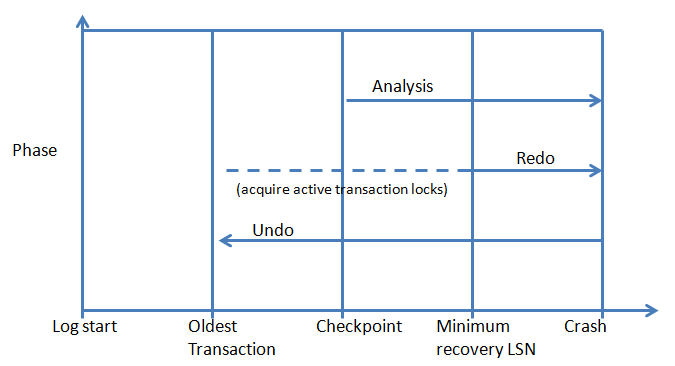
Tx1_f906d5
21 Posts
2
January 11th, 2012 06:00
What is important to understand is the relationships between many of these features. But it all starts with a transaction.
When a change occurs within a SQL Server environment, this will always occur within the context of a transaction - either explicitly in code or implicitly. Changes to pages will obviously occur and when the transaction commit occurs, then you get a synchronous write to the transaction log. All the information with respect to the transaction is now persisted in the log. The data represnting the change to the data file may not be immediately written to disk. If the system failed at this point, the correct data would be reconstructed from information in the transaction log (roll forward/roll back recovery at restart)
Lazy writers are simply responsible for writing out the dirty pages for the data files. These may be changes that resulted from a commited transaction where the data was not previously written out. The Lazy Writer is only trying to free up SQL Server buffer pool space, so that it can be used for other transactions. It does not really have anything to do with transactional consistency.
Then there's the CheckPoint. This is a point of syncronization between the transaction log AND the data files. When a checkpoint happens, the goal is to write every change out to the data files (remember the log is synchronous, so it's always up to date). The fact that a checkpoint has completed is also written to the log. Checkpoints occur when the system needs to get to a consistent point in time for both data and log files - classic example is prior to attempting to make a disk mirror split operation (VDI/VSS). Checkpoints also happen based on configurations settings in the SQL Server environment (recovery time interval). The Checkpoint is the last point in time that the restart recovery process would need to go back to, to do the rollback/rollforward recovery.
The important part here is that it's the data in the transaction log that is used to resolve any changes to the data files, and this is not necessairly affected by the lazy writer or Checkpoint. The combination of data files and transaction log gets the DB back to a consistent point in time.
Michael_Morris
18 Posts
2
January 11th, 2012 09:00
Hi Zhao
Tx has posted a great answer, the lazy writer is reallty invalidated during recovery, I was in middle of replying so wont repeat but here are some useful links
Writing Pages
http://msdn.microsoft.com/en-us/library/aa337560(v=SQL.105).aspx
Lazy Writer and the Checkpoint
http://sqlinthewild.co.za/index.php/2009/06/26/the-lazy-writer-and-the-checkpoint/
Recovery Model Overview
http://msdn.microsoft.com/en-us/library/ms189275.aspx
Restore and Recovery Overview (SQL Server)
http://msdn.microsoft.com/en-us/library/ms191253.aspx
Understanding How Restore and Recovery of Backups Work in SQL Server
http://msdn.microsoft.com/en-us/library/ms191455.aspx
There is a good presentation stepping through the process available on the web, will try and dig out, had a look but couldnt find but will try again tomorrow.
LouisLu
161 Posts
2
January 11th, 2012 18:00
Simon,
The lazywriter thread sleeps for a specific interval of time. When it is restarted, it examines the size of the free buffer list. If the free buffer list is below a certain point, dependent on the size of the cache, the lazywriter thread scans the buffer cache to reclaim unused pages. The difference between lazy write and checkpoint is below:
http://madhuottapalam.blogspot.com/2008/06/faq-what-is-difference-between.html
Lu
zhaos2
2 Intern
•
643 Posts
0
January 11th, 2012 21:00
Thanks all for your attendtion and experties! Lazy writer is actually not a role in recovery. Please refer to the below link for detail on difference between Checkpoint and Lazy Write.
http://thakurvinay.wordpress.com/2011/06/20/difference-between-checkpoint-and-lazywritter/
zhaos2
2 Intern
•
643 Posts
0
January 12th, 2012 21:00
Thank you very much Michael for your effort to clarify my question, your information in very helpful!