Kód události Openshift: 1030NODE0001 řekl:
Zusammenfassung: Trvalé vysoké využití procesoru na jednom uzlu řídicí roviny, větší tlak na procesor pravděpodobně způsobí převzetí služeb při selhání. zvýšení dostupného procesoru.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Extrémní tlak na procesor může způsobit pomalou serializaci a špatný výkon z kube-apiserver a etcd. Když k tomu dojde, existuje riziko, že klienti uvidí nereagující požadavky rozhraní API, které se znovu vydají, což způsobí ještě větší tlak na procesor.
Může také způsobit selhání sond živého provozu kvůli pomalé odezvě etcd na back-endu. Pokud jeden kube-apiserver za této podmínky selže, je pravděpodobné, že dojde ke kaskádě, protože zbývající kube-apiservers jsou také nedostatečně zřízené.
Může také způsobit selhání sond živého provozu kvůli pomalé odezvě etcd na back-endu. Pokud jeden kube-apiserver za této podmínky selže, je pravděpodobné, že dojde ke kaskádě, protože zbývající kube-apiservers jsou také nedostatečně zřízené.
Ursache
Tato výstraha se aktivuje v případě, že na jednom uzlu řídicí roviny dochází k trvalému vysokému využití procesoru.
Naléhavost této výstrahy je určena tím, jak dlouho uzel udržuje vysoké využití procesoru:
Naléhavost této výstrahy je určena tím, jak dlouho je využití procesoru ve všech třech uzlech řídicí roviny vyšší, než mohou dva uzly řídicí roviny vydržet.
Naléhavost této výstrahy je určena tím, jak dlouho uzel udržuje vysoké využití procesoru:
- Kritická
- když je využití procesoru na uzlu jednotlivé řídicí roviny větší než 90 % po dobu delší než 1 hodina.
- Warning
- když je využití procesoru na uzlu jednotlivé řídicí roviny větší než 90 % na více než 5 m.
Naléhavost této výstrahy je určena tím, jak dlouho je využití procesoru ve všech třech uzlech řídicí roviny vyšší, než mohou dva uzly řídicí roviny vydržet.
- Warning
- když je využití procesoru ve všech třech uzlech řídicí roviny vyšší než dva uzly řídicí roviny mohou vydržet déle než 10 m.
Lösung
Diagnóza:
Spusťte ve webové konzoli OCP následující dotazy PromQL, které vám pomohou s diagnostikou (sledujte → metriky → spouštění dotazů).Prvních 5 kontejnerů s největším využitím procesoru na konkrétním uzlu:
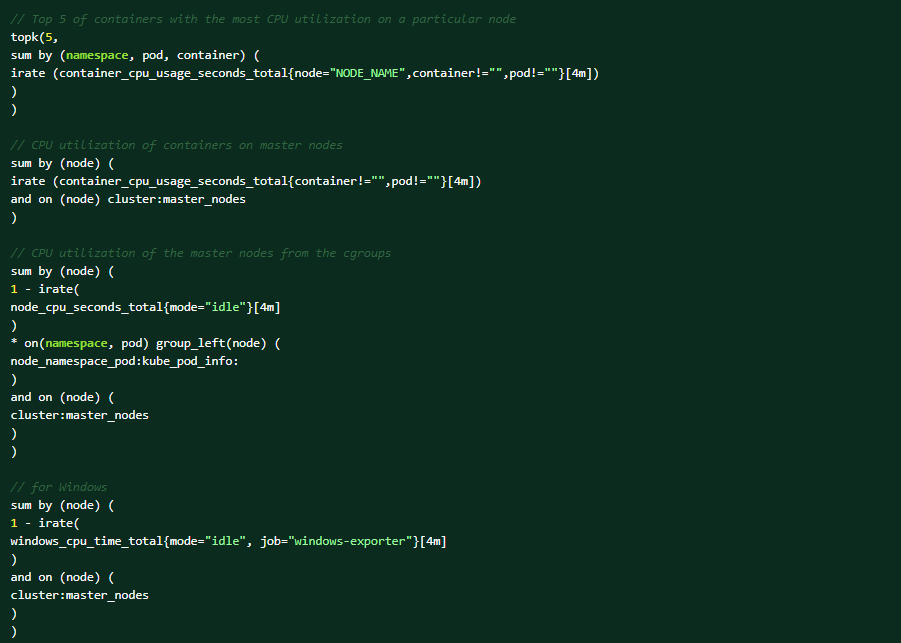
Toto jsou podmínky, které mohou aktivovat výstrahu:
- Existuje nová úloha, která generuje více volání apiserveru a způsobuje vysoké využití procesoru. V takovém případě zvyšte procesor a paměť na uzlech řídicí roviny.
- Výstraha se aktivuje na základě metrik uzlu, takže je možné, že vysoké využití procesoru způsobuje komponenta na uzlu.
- APISERVER/etcd zpracovává více požadavků kvůli opakovaným pokusům klienta, které jsou způsobeny základní podmínkou.
- nerovnoměrné rozdělení požadavků na instanci(y) apiserveru kvůli http2 (multiplexuje požadavky přes jedno TCP spojení). Nástroje pro vyrovnávání zatížení nejsou na aplikační vrstvě, a proto nerozumí http2.
Zmírnění problému:
- Pokud úloha generuje zatížení apiserveru, který způsobuje vysoké využití procesoru, zvyšte procesor a paměť na uzlech řídicí roviny.
- Pokud je trvale vysoké využití procesoru způsobeno degradací clusteru:
- Zjistěte hlavní příčinu degradace a podle toho určete další kroky.
Podpora:
Pokud ani jeden z výše uvedených kroků nevyřeší problém, obraťte se na technickou podporu společnosti Dell EMC s žádostí o další šetření.
Weitere Informationen
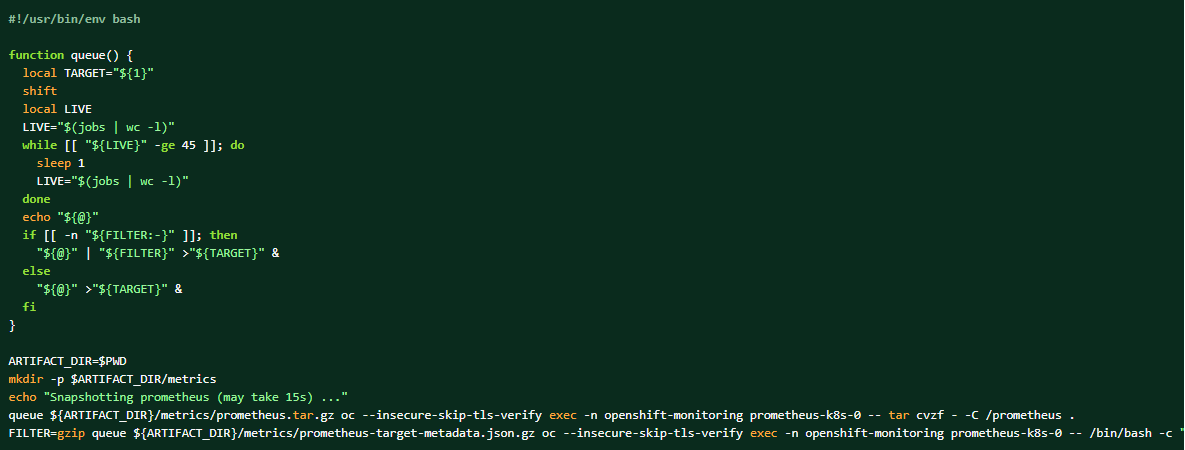
Pokud je shromážděn balíček protokolů, mohou být data Prometheus také vypsána jako doplňující materiály.
Jak získat výpis dat clusteru prometheus:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.