Kod zdarzenia Openshift: 1030WĘZEŁ0001
Zusammenfassung: Utrzymujące się wysokie wykorzystanie procesora CPU w jednym węźle płaszczyzny sterowania, większe obciążenie procesora CPU może spowodować przejście w tryb failover; zwiększyć dostępny procesor. ...
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Ekstremalne obciążenie procesora CPU może powodować powolną serializację i słabą wydajność z kube-apiserver i etcd. W takim przypadku istnieje ryzyko, że klienci zobaczą nieodpowiadające żądania interfejsu API, które są wystawiane ponownie, powodując jeszcze większe obciążenie procesora.
Może to również powodować niepowodzenie sond na żywo z powodu powolnej reakcji etcd na zapleczu. Jeśli jeden kube-apiserver ulegnie awarii w tym stanie, istnieje prawdopodobieństwo, że wystąpi kaskada, ponieważ pozostałe kube-apiservers są również niedostatecznie aprowizowane.
Może to również powodować niepowodzenie sond na żywo z powodu powolnej reakcji etcd na zapleczu. Jeśli jeden kube-apiserver ulegnie awarii w tym stanie, istnieje prawdopodobieństwo, że wystąpi kaskada, ponieważ pozostałe kube-apiservers są również niedostatecznie aprowizowane.
Ursache
Ten alert jest wyzwalany w przypadku utrzymującego się wysokiego wykorzystania procesora CPU w jednym węźle płaszczyzny sterowania.
Pilność tego alertu zależy od tego, jak długo węzeł utrzymuje wysokie użycie procesora CPU:
Pilność tego alertu zależy od tego, jak długo wykorzystanie procesora CPU we wszystkich trzech węzłach płaszczyzny sterowania jest większe niż dwa węzły płaszczyzny sterowania mogą wytrzymać.
Pilność tego alertu zależy od tego, jak długo węzeł utrzymuje wysokie użycie procesora CPU:
- Krytyczny
- gdy użycie procesora w pojedynczym węźle płaszczyzny sterowania jest większe niż 90% przez ponad 1 godzinę.
- Ostrzeżenie
- gdy użycie procesora w pojedynczym węźle płaszczyzny sterowania jest większe niż 90% przez ponad 5 m.
Pilność tego alertu zależy od tego, jak długo wykorzystanie procesora CPU we wszystkich trzech węzłach płaszczyzny sterowania jest większe niż dwa węzły płaszczyzny sterowania mogą wytrzymać.
- Ostrzeżenie
- gdy wykorzystanie procesora we wszystkich trzech węzłach płaszczyzny sterowania jest wyższe niż dwa węzły płaszczyzny sterowania mogą utrzymać się przez ponad 10 m.
Lösung
Diagnoza:
Wykonaj następujące zapytania PromQL w konsoli internetowej OCP, aby uzyskać pomoc w diagnostyce (Obserwuj metryki → → Uruchamiaj zapytania).Top 5 kontenerów z największym wykorzystaniem procesora CPU w danym węźle:
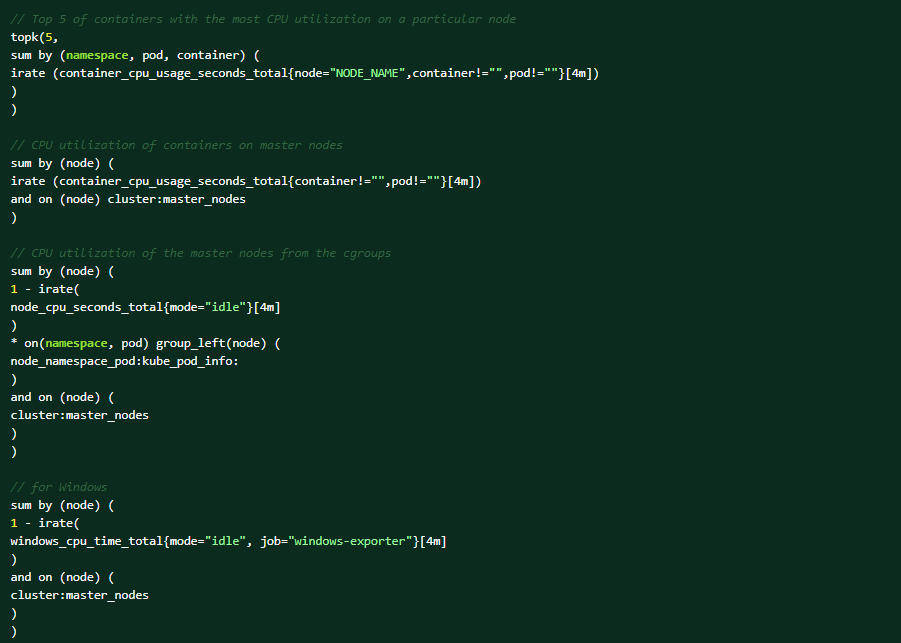
Oto warunki, które mogą wyzwolić alert:
- istnieje nowe obciążenie, które generuje więcej wywołań do serwera apiserver i powoduje wysokie użycie procesora CPU. W takim przypadku zwiększ procesor CPU i pamięć w węzłach płaszczyzny sterowania.
- Alert jest wyzwalany na podstawie metryk węzła, więc może się zdarzyć, że składnik w węźle powoduje wysokie użycie procesora.
- apiserver/etcd przetwarza więcej żądań z powodu ponownych prób klienta, które są spowodowane przez warunek podstawowy.
- Nierównomierna dystrybucja żądań do instancji apiserver z powodu protokołu http2 (multipleksuje żądania za pośrednictwem jednego połączenia TCP). Moduły równoważenia obciążenia nie znajdują się w warstwie aplikacji, a więc nie rozumieją protokołu http2.
Łagodzenie:
- Jeśli obciążenie generuje obciążenie serwera interfejsu API, które powoduje wysokie użycie procesora CPU, zwiększ procesor CPU i pamięć w węzłach płaszczyzny sterowania.
- Jeśli utrzymujące się wysokie użycie procesora jest spowodowane degradacją klastra:
- Znajdź pierwotną przyczynę degradacji, a następnie określ odpowiednie kolejne kroki.
Wsparcie:
Jeśli wszystkie powyższe czynności nie rozwiążą problemu, skontaktuj się z działem pomocy technicznej firmy Dell EMC w celu dokładniejszego zbadania problemu.
Weitere Informationen
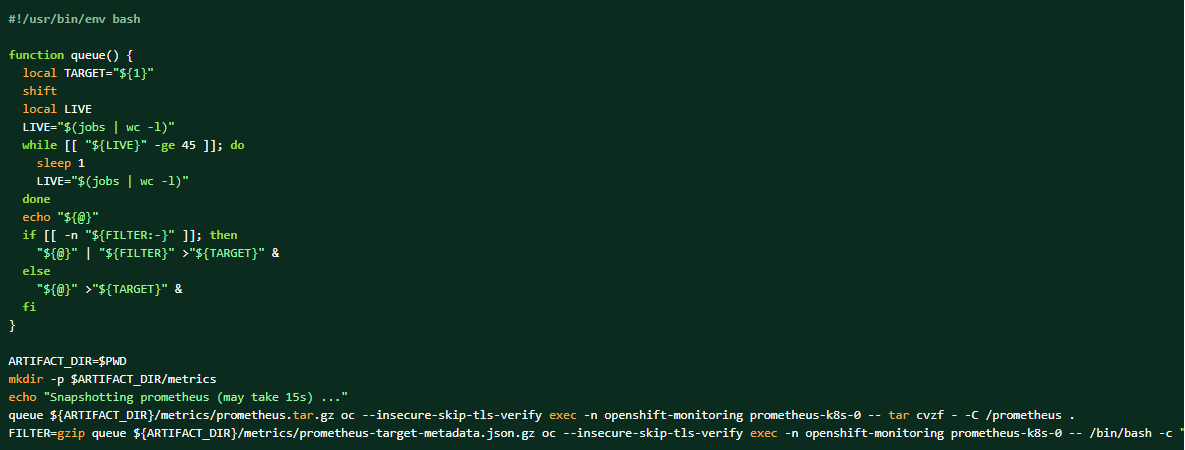
Jeśli pakiet dzienników jest zbierany, dane Prometheus mogą być również zrzucane jako materiały uzupełniające.
Jak wykonać zrzut danych prometeusza klastra:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.