OpenShift-händelsekod: 1030NOD0001
Zusammenfassung: Ihållande hög CPU-användning på en enda kontrollplansnod kommer mer CPU-tryck sannolikt att orsaka en redundansväxling. öka tillgänglig CPU.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Extremt CPU-tryck kan orsaka långsam serialisering och dåliga prestanda från kube-apiserver och etcd. När detta inträffar finns det en risk för att klienter ser icke-responsiva API-begäranden som utfärdas igen, vilket orsakar ännu mer CPU-tryck.
Det kan också orsaka misslyckade liveness-avsökningar på grund av långsam etcd-svarstid på serverdelen. Om en kube-apiserver misslyckas under det här villkoret är risken stor att du får en kaskad eftersom de återstående kube-apiservers också är underetablerade.
Det kan också orsaka misslyckade liveness-avsökningar på grund av långsam etcd-svarstid på serverdelen. Om en kube-apiserver misslyckas under det här villkoret är risken stor att du får en kaskad eftersom de återstående kube-apiservers också är underetablerade.
Ursache
Den här aviseringen utlöses när det finns en ihållande hög CPU-användning på en enda kontrollplansnod.
Hur brådskande den här aviseringen är bestäms av hur länge noden upprätthåller hög CPU-användning:
Hur brådskande den här aviseringen är bestäms av hur länge CPU-användningen för alla tre kontrollplansnoderna är högre än vad två kontrollplansnoder kan upprätthålla.
Hur brådskande den här aviseringen är bestäms av hur länge noden upprätthåller hög CPU-användning:
- Kritisk
- när CPU-användningen på en enskild kontrollplansnod är större än 90 % i mer än 1 timme.
- Varning
- när CPU-användningen på en enskild kontrollplansnod är större än 90 % i mer än 5 m.
Hur brådskande den här aviseringen är bestäms av hur länge CPU-användningen för alla tre kontrollplansnoderna är högre än vad två kontrollplansnoder kan upprätthålla.
- Varning
- när CPU-användningen för alla tre kontrollplansnoderna är högre än två kontrollplansnoder kan upprätthållas i mer än 10 m.
Lösung
Diagnos:
Kör följande PromQL-frågor på OCP-webbkonsolen för att få hjälp med diagnos (Observera → Metrics → Kör frågor).De 5 främsta containrarna med mest CPU-användning på en viss nod:
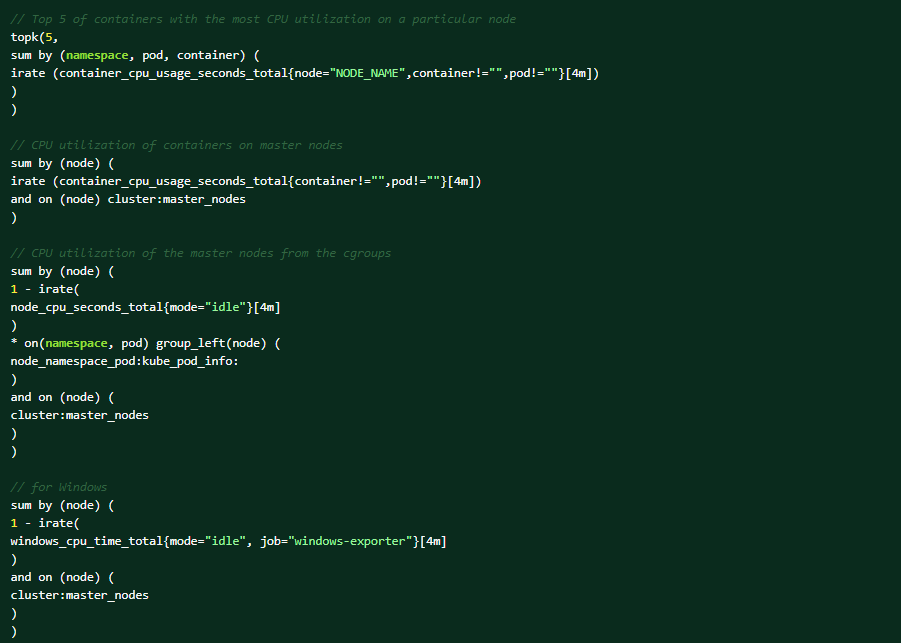
Det här är de villkor som kan utlösa aviseringen:
- det finns en ny arbetsbelastning som genererar fler anrop till apiserver och orsakar hög CPU-användning. I det här fallet ökar du processorn och minnet på kontrollplansnoderna.
- aviseringen utlöses baserat på nodmåtten, så det kan vara så att en komponent på noden orsakar den höga CPU-användningen.
- apiserver/etcd bearbetar fler begäranden på grund av klientåterförsök som orsakas av ett underliggande villkor.
- ojämn fördelning av begäranden till apiserver-instanserna på grund av http2 (den multiplexerar begäranden över en enda TCP-anslutning). Lastbalanserarna finns inte på programnivån och förstår därför inte http2.
Lindring:
- Om en arbetsbelastning genererar belastning till apiserver som orsakar hög CPU-användning ökar du processorn och minnet på kontrollplansnoderna.
- Om den ihållande höga CPU-användningen beror på en klusterförsämring:
- Ta reda på grundorsaken till försämringen och bestäm sedan nästa steg därefter.
Support:
Om inget av stegen ovan kan lösa problemet kontaktar du Dell EMC:s tekniska support för vidare undersökning.
Weitere Informationen
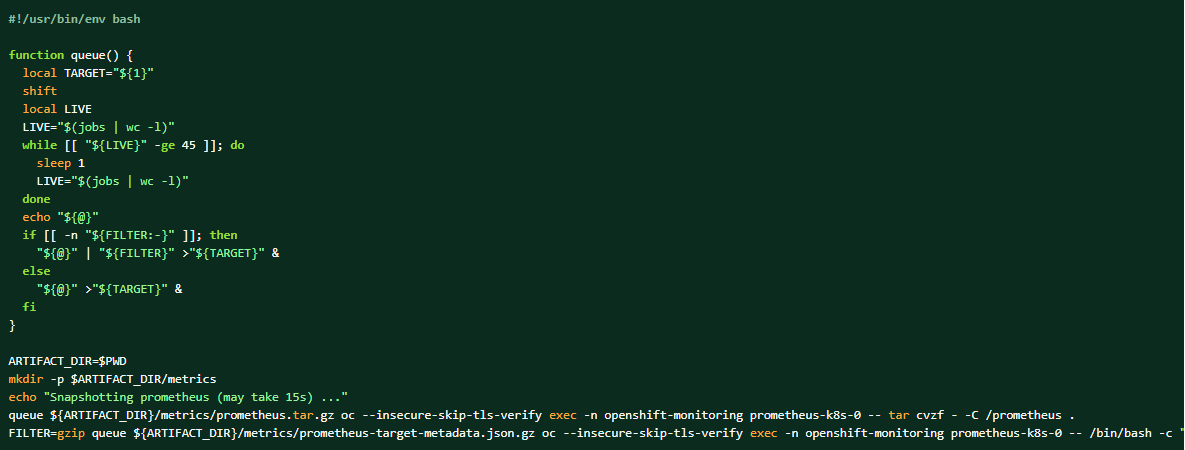
Om loggpaketet samlas in kan Prometheus-data också dumpas som kompletterande material.
Så här tar du en dump av klustrets prometheus-data:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.