Openshift 事件代码:1030NODE0001
Zusammenfassung: 单个控制平面节点上的 CPU 利用率持续较高,更大的 CPU 压力可能会导致故障转移;增加可用 CPU。
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
过高的 CPU 压力会导致 kube-apiserver 和 etcd 序列化速度缓慢,性能不佳。发生这种情况时,存在客户端看到无响应的 API 请求的风险,这些请求再次发出,从而导致更大的 CPU 压力。
由于后端的 etcd 响应缓慢,它还可能导致存活探测失败。如果一个 kube-apiserver 在这种情况下出现故障,您很可能会遇到级联,因为其余的 kube-apiserver 也配置不足。
由于后端的 etcd 响应缓慢,它还可能导致存活探测失败。如果一个 kube-apiserver 在这种情况下出现故障,您很可能会遇到级联,因为其余的 kube-apiserver 也配置不足。
Ursache
当单个控制平面节点上出现持续的高 CPU 利用率时,会触发此警报。
此警报的紧急程度取决于节点保持高 CPU 使用率的时间长度:
此警报的紧急程度取决于所有三个控制平面节点的 CPU 利用率高于两个控制平面节点可以维持的时间长度。
此警报的紧急程度取决于节点保持高 CPU 使用率的时间长度:
- 严重
- 单个控制平面节点上的 CPU 使用率超过 90% 且超过 1 小时。
- Warning
- 当单个控制平面节点上的 CPU 使用率超过 90% 且超过 5m 时。
此警报的紧急程度取决于所有三个控制平面节点的 CPU 利用率高于两个控制平面节点可以维持的时间长度。
- Warning
- 当所有三个控制平面节点的 CPU 利用率都高于两个控制平面节点时,控制平面节点可以维持超过 10m。
Lösung
诊断:
在 OCP Web 控制台上执行以下 PromQL 查询,以帮助进行诊断(观察→指标→运行查询)。特定节点上 CPU 利用率最高的前 5 个容器:
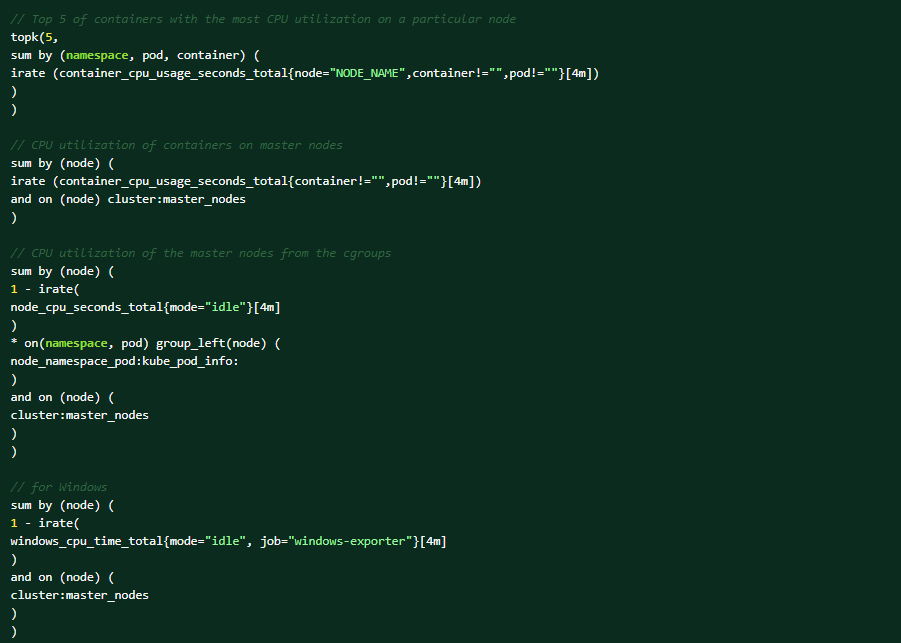
以下是可能触发警报的条件:
- 有一个新的工作负载正在生成对 APIServer 的更多调用,并导致 CPU 使用率过高。在这种情况下,请增加控制平面节点上的 CPU 和内存。
- 该警报是根据节点指标触发的,因此可能是节点上的某个组件导致了高 CPU 使用率。
- 由于底层条件导致的客户端重试,apiserver/etcd 正在处理更多请求。
- 由于 HTTP2(它通过单个 TCP 连接多路复用请求),请求分发到 APIServer 实例不均匀。负载均衡器不在应用程序层,因此不理解 http2。
缓解措施:
- 如果工作负载正在向 APIServer 生成负载,导致 CPU 使用率过高,请增加控制平面节点上的 CPU 和内存。
- 如果持续的高 CPU 使用率是由于群集降级所致:
- 找出降级的根本原因,然后相应地确定后续步骤。
支持:
如果上述所有步骤都无法解决问题,请联系 Dell EMC 技术支持以进行进一步调查。
Weitere Informationen
如果收集了日志包,Prometheus 数据也可以作为补充材料进行转储。
如何转储群集 prometheus 数据:
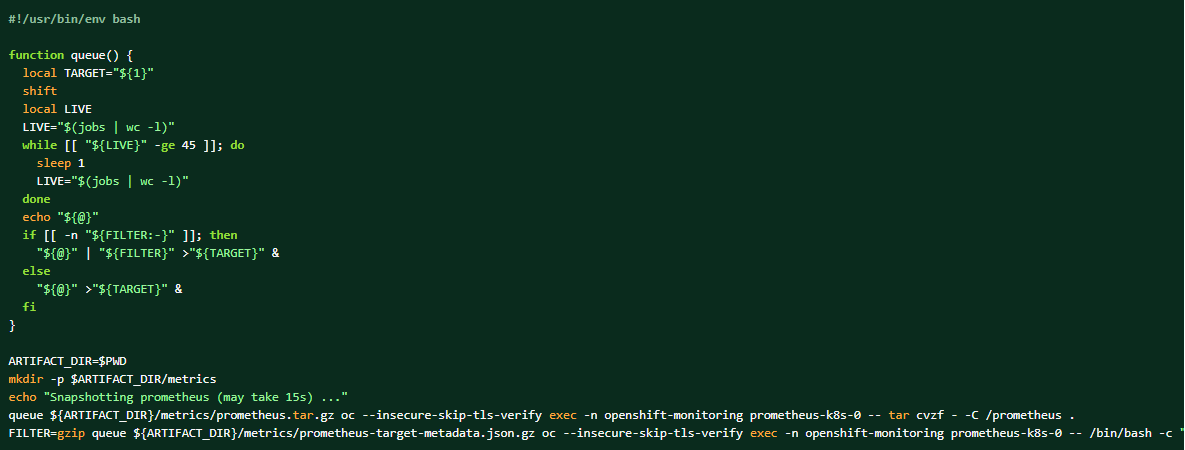
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.