Openshift-hændelseskode: 1030NODE0001
Zusammenfassung: Vedvarende høj CPU-udnyttelse på en enkelt kontrolplanknude vil mere CPU-tryk sandsynligvis forårsage en failover; øge tilgængelig CPU.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Ekstremt CPU-tryk kan forårsage langsom serialisering og dårlig ydeevne fra kube-apiserver og etcd. Når dette sker, er der risiko for, at klienter ser ikke-responsive API-anmodninger, der udstedes igen, hvilket forårsager endnu mere CPU-tryk.
Det kan også forårsage svigtende liveness-sonder på grund af langsom ætset lydhørhed på backend. Hvis en kube-apiserver fejler under denne tilstand, vil du sandsynligvis opleve en kaskade, da de resterende kube-api-servere også er underklargjort.
Det kan også forårsage svigtende liveness-sonder på grund af langsom ætset lydhørhed på backend. Hvis en kube-apiserver fejler under denne tilstand, vil du sandsynligvis opleve en kaskade, da de resterende kube-api-servere også er underklargjort.
Ursache
Denne advarsel udløses, når der er en vedvarende høj CPU-udnyttelse på en enkelt kontrolplannode.
Hvor meget denne advarsel haster, afgøres af, hvor længe noden opretholder et højt CPU-forbrug:
Hvor hastende denne advarsel er, afgøres af, hvor længe CPU-udnyttelsen på tværs af alle tre kontrolplannoder er højere, end to kontrolplannoder kan opretholde.
Hvor meget denne advarsel haster, afgøres af, hvor længe noden opretholder et højt CPU-forbrug:
- Kritiske
- når CPU-forbruget på en individuel kontrolplannode er større end 90 % i mere end 1 time.
- Advarsel
- når CPU-forbruget på en individuel kontrolplannode er større end 90 % i mere end 5 m.
Hvor hastende denne advarsel er, afgøres af, hvor længe CPU-udnyttelsen på tværs af alle tre kontrolplannoder er højere, end to kontrolplannoder kan opretholde.
- Advarsel
- når CPU-udnyttelsen på tværs af alle tre kontrolplannoder er højere, end to kontrolplannoder kan opretholde i mere end 10 m.
Lösung
Diagnose:
Udfør følgende PromQL-forespørgsler på OCP-webkonsollen ved hjælp af diagnosticering (Overhold → målinger → Run-forespørgsler).Top 5 over containere med mest CPU-udnyttelse på en bestemt node:
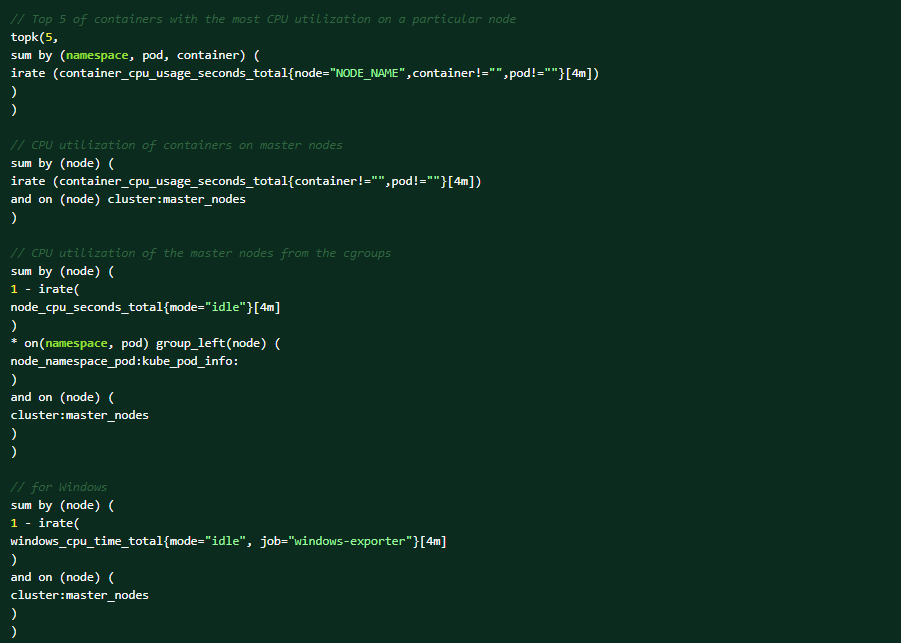
Dette er de forhold, der kan udløse advarslen:
- der er en ny arbejdsbyrde, der genererer flere opkald til apiserveren og forårsager høj CPU-brug. I dette tilfælde skal du øge CPU'en og hukommelsen på dine kontrolplannoder.
- advarslen udløses baseret på nodemålingerne, så det kan være, at en komponent på noden forårsager det høje CPU-forbrug.
- APISERVER/ETCD behandler flere anmodninger på grund af klientforsøg, der skyldes en underliggende tilstand.
- ujævn fordeling af anmodninger til apiserver-instansen (e) på grund af http2 (det multiplexer anmodninger over en enkelt TCP-forbindelse). Belastningsbalancerne er ikke på applikationslaget og forstår derfor ikke http2.
Afbødning:
- Hvis en arbejdsbelastning genererer belastning til API-serveren, der forårsager højt CPU-forbrug, skal du øge CPU'en og hukommelsen på dine kontrolplannoder.
- Hvis det vedvarende høje CPU-forbrug skyldes en klyngeforringelse:
- Find ud af årsagen til nedbrydningen, og bestem derefter de næste trin i overensstemmelse hermed.
Support:
Hvis alle ovenstående trin ikke kan løse problemet, skal du kontakte Dell EMC s tekniske support for yderligere undersøgelse.
Weitere Informationen
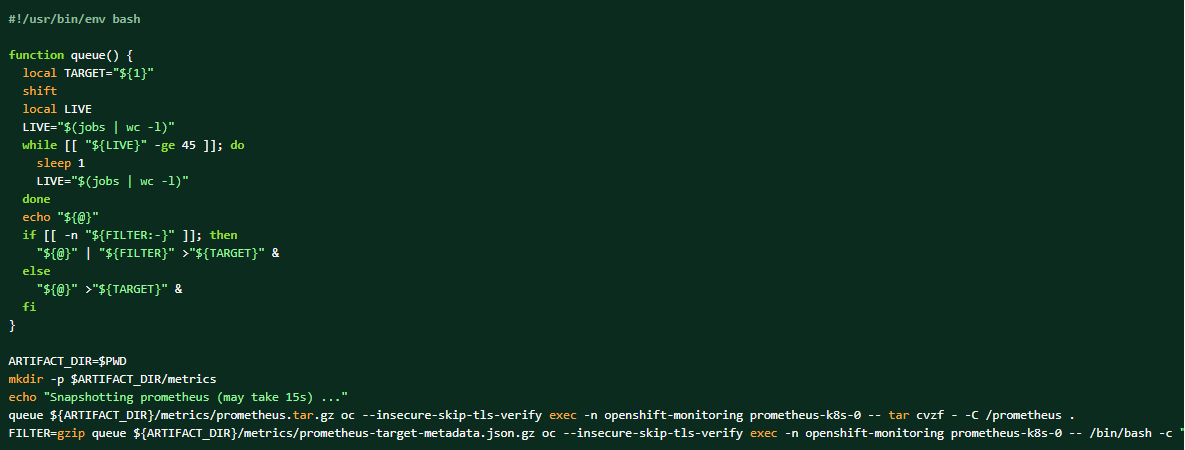
Hvis logbundtet indsamles, kan Prometheus-dataene også dumpes som supplerende materialer.
Sådan tager du et dump af klyngeprometheusdataene:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.