Code d’événement Openshift : 1030NODE0001
Zusammenfassung: En cas d’utilisation élevée et soutenue du processeur sur un seul nœud de plan de contrôle, une pression plus importante sur le processeur est susceptible de provoquer un basculement ; Augmentez le nombre de processeurs disponibles. ...
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Une sollicitation extrême du processeur peut ralentir la sérialisation et nuire aux performances de kube-apiserver, etcd. Lorsque cela se produit, les clients risquent de voir des demandes d’API non répondues émises à nouveau, ce qui accentue encore la pression sur le processeur.
Cela peut également entraîner l’échec des explorations de dynamique en raison de la lenteur de la réactivité etcd sur le back-end. Si un kube-apiserver échoue dans cette condition, il y a de fortes chances que vous rencontriez une cascade, car les autres kube-apiservers sont également sous-provisionnés.
Cela peut également entraîner l’échec des explorations de dynamique en raison de la lenteur de la réactivité etcd sur le back-end. Si un kube-apiserver échoue dans cette condition, il y a de fortes chances que vous rencontriez une cascade, car les autres kube-apiservers sont également sous-provisionnés.
Ursache
Cette alerte est déclenchée en cas d’utilisation élevée et soutenue du processeur sur un nœud de plan de contrôle unique.
L’urgence de cette alerte est déterminée par la durée pendant laquelle le nœud maintient une utilisation élevée du processeur :
L’urgence de cette alerte est déterminée par la durée pendant laquelle l’utilisation du processeur sur les trois nœuds du plan de contrôle est supérieure à la capacité de deux nœuds du plan de contrôle.
L’urgence de cette alerte est déterminée par la durée pendant laquelle le nœud maintient une utilisation élevée du processeur :
- Critique
- lorsque l’utilisation du processeur sur un nœud de plan de contrôle individuel est supérieure à 90 % pendant plus d’une heure.
- Warning
- lorsque l’utilisation du processeur sur un nœud de plan de contrôle individuel est supérieure à 90 % pendant plus de 5 m.
L’urgence de cette alerte est déterminée par la durée pendant laquelle l’utilisation du processeur sur les trois nœuds du plan de contrôle est supérieure à la capacité de deux nœuds du plan de contrôle.
- Warning
- Lorsque l’utilisation du processeur sur les trois nœuds du plan de contrôle est supérieure à deux nœuds du plan de contrôle, les nœuds peuvent tenir plus de 10 m.
Lösung
Diagnostic:
Exécutez les requêtes PromQL suivantes sur la console Web OCP à des fins de diagnostic (Observer → Metrics → Exécuter des requêtes).Top 5 des conteneurs avec le plus d’utilisation du processeur sur un nœud particulier :
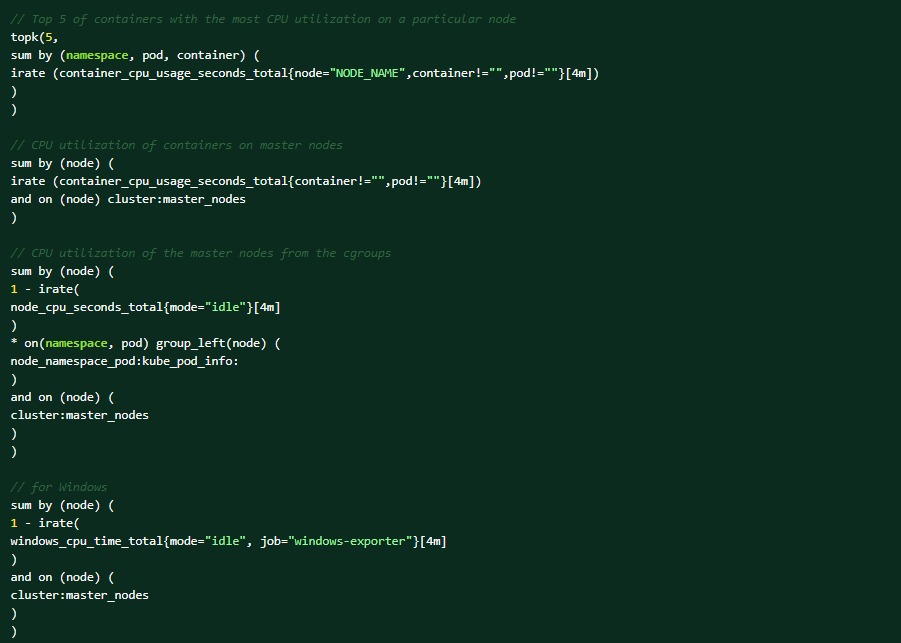
Voici les conditions susceptibles de déclencher l’alerte :
- Une nouvelle charge applicative génère davantage d’appels à l’API Server et entraîne une utilisation élevée du processeur. Dans ce cas, augmentez le processeur et la mémoire sur vos nœuds de plan de contrôle.
- L’alerte étant déclenchée en fonction des mesures du nœud, il se peut donc qu’un composant du nœud soit à l’origine de l’utilisation élevée du processeur.
- ApiServer/etcd traite plus de demandes en raison de nouvelles tentatives client qui sont causées par une condition sous-jacente.
- distribution inégale des requêtes vers la ou les instance(s) ApiServer en raison de http2 (il multiplexe les requêtes sur une seule connexion TCP). Les équilibreurs de charge ne sont pas au niveau de la couche d’application et ne comprennent donc pas http2.
Solution d'atténuation :
- si une charge applicative génère une charge sur l’APIserver et entraîne une utilisation élevée du processeur, augmentez le processeur et la mémoire sur vos nœuds de plan de contrôle.
- Si l’utilisation élevée et soutenue du processeur est due à une dégradation du cluster :
- Déterminez la cause première de la dégradation, puis déterminez les étapes suivantes en conséquence.
Support :
Si toutes les étapes ci-dessus ne permettent pas de résoudre le problème, contactez le support technique Dell EMC pour une procédure d’enquête plus approfondie.
Weitere Informationen
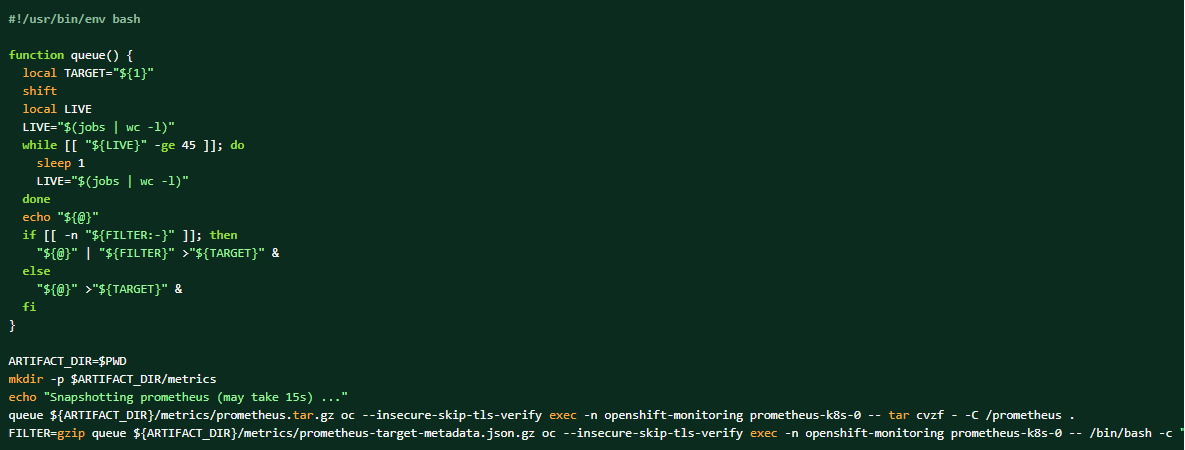
Si le bundle de logs est collecté, les données Prometheus peuvent également être vidées en tant que ressources complémentaires.
Comment effectuer un vidage des données Prometheus du cluster :
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.