Código do evento Openshift: 1030NODE0001
Zusammenfassung: Com alta utilização sustentada da CPU em um único nó de plano de controle, mais pressão da CPU provavelmente causará um failover; aumentar a CPU disponível.
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
A pressão extrema da CPU pode causar serialização lenta e baixo desempenho do kube-apiserver e etcd. Quando isso acontece, há o risco de os clientes verem solicitações de API sem resposta, que são emitidas novamente, causando ainda mais pressão da CPU.
Isso também pode causar falhas nas sondas de vivacidade devido à lentidão da capacidade de resposta etcd no back-end. Se um kube-apiserver falhar nessa condição, é provável que você experimente uma cascata, pois os kube-apiservers restantes também têm provisionamento insuficiente.
Isso também pode causar falhas nas sondas de vivacidade devido à lentidão da capacidade de resposta etcd no back-end. Se um kube-apiserver falhar nessa condição, é provável que você experimente uma cascata, pois os kube-apiservers restantes também têm provisionamento insuficiente.
Ursache
Esse alerta é acionado quando há uma alta utilização sustentada da CPU em um único nó de plano de controle.
A urgência desse alerta é determinada por quanto tempo o nó está sustentando alto uso da CPU:
A urgência desse alerta é determinada por quanto tempo a utilização da CPU em todos os três nós do plano de controle é maior do que dois nós do plano de controle podem suportar.
A urgência desse alerta é determinada por quanto tempo o nó está sustentando alto uso da CPU:
- Crítica
- quando o uso da CPU em um nó de plano de controle individual for maior que 90% por mais de 1h.
- Warning
- quando o uso da CPU em um nó de plano de controle individual for maior que 90% por mais de 5 m.
A urgência desse alerta é determinada por quanto tempo a utilização da CPU em todos os três nós do plano de controle é maior do que dois nós do plano de controle podem suportar.
- Warning
- quando a utilização da CPU em todos os três nós do plano de controle é maior do que dois nós do plano de controle, eles podem se sustentar por mais de 10 m.
Lösung
Diagnóstico:
Execute as seguintes consultas PromQL no console da Web do OCP para obter ajuda no diagnóstico (Observe → Metrics → Run queries).Os cinco principais contêineres com maior utilização de CPU em um nó específico:
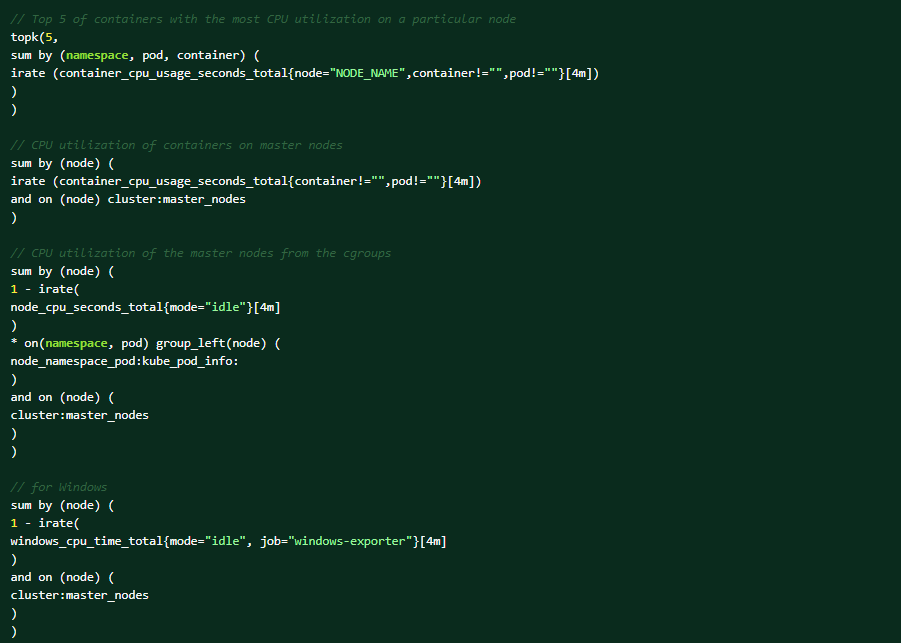
Estas são as condições que podem acionar o alerta:
- há uma nova carga de trabalho que está gerando mais chamadas para o apiserver e causando alto uso da CPU. Nesse caso, aumente a CPU e a memória nos nós do plano de controle.
- o alerta é acionado com base nas métricas do nó, portanto, pode ser que um componente no nó esteja causando o alto uso da CPU.
- O apiserver/etcd está processando mais solicitações devido a repetições de client causadas por uma condição subjacente.
- distribuição desigual de solicitações para as instâncias do apiserver devido ao http2 (ele multiplexa solicitações em uma única conexão TCP). Os balanceadores de carga não estão na camada de aplicativo e, portanto, não entendem http2.
Redução:
- Se uma carga de trabalho estiver gerando carga para o servidor de API que está causando alto uso da CPU, aumente a CPU e a memória nos nós do plano de controle.
- Se o alto uso sustentado da CPU for devido a uma degradação do cluster:
- Descubra a causa raiz da degradação e, em seguida, determine as próximas etapas de acordo.
Suporte:
Se todas as etapas acima não puderem resolver o problema, entre em contato com o suporte técnico da Dell EMC para investigar mais.
Weitere Informationen
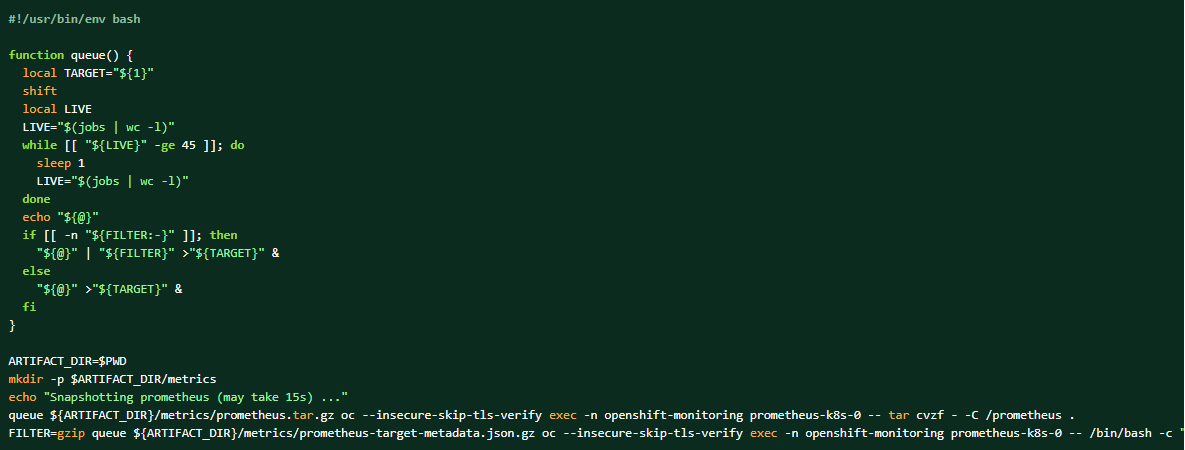
Se o pacote de logs for coletado, os dados do Prometheus também poderão ser despejados como materiais complementares.
Como fazer um dump dos dados do inventário do cluster:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.