Код события Openshift: 1030УЗЕЛ0001
Zusammenfassung: При устойчивом высоком коэффициенте использования ЦП на одном узле плоскости управления повышенная нагрузка на ЦП с большой вероятностью приведет к переключению при отказе; увеличить доступный процессор. ...
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
Чрезмерное давление на процессор может привести к медленной сериализации и низкой производительности kube-apiserver и etcd. В этом случае существует риск того, что клиенты увидят не отвечающие запросы API, которые будут выполнены снова, что приведет к еще большей нагрузке на ЦП.
Это также может привести к сбою проб liveness из-за медленного реагирования etcd в серверной части. Если один из kube-apiserver выйдет из строя при этом условии, есть вероятность, что вы столкнетесь с каскадом, так как остальные kube-apiservers также недостаточно подготовлены.
Это также может привести к сбою проб liveness из-за медленного реагирования etcd в серверной части. Если один из kube-apiserver выйдет из строя при этом условии, есть вероятность, что вы столкнетесь с каскадом, так как остальные kube-apiservers также недостаточно подготовлены.
Ursache
Это оповещение появляется при устойчиво высокой загрузке ЦП на одном узле плоскости управления.
Срочность этого оповещения определяется тем, как долго узел поддерживает высокую загрузку ЦП:
Срочность этого оповещения определяется тем, насколько загрузка ЦП на всех трех узлах плоскости управления превышает возможности двух узлов уровня управления.
Срочность этого оповещения определяется тем, как долго узел поддерживает высокую загрузку ЦП:
- Критический
- если загрузка ЦП на отдельном узле плоскости управления превышает 90% в течение более 1 часа.
- Предупреждение
- если загрузка ЦП на отдельном узле плоскости управления превышает 90% на протяжении более 5 мес.
Срочность этого оповещения определяется тем, насколько загрузка ЦП на всех трех узлах плоскости управления превышает возможности двух узлов уровня управления.
- Предупреждение
- Если загрузка ЦП на всех трех узлах плоскости управления выше, два узла плоскости управления могут работать более 10 млн об/мин.
Lösung
Диагноз:
Выполните следующие запросы PromQL в веб-консоли OCP для помощи в диагностике (Наблюдение за метриками → Выполнение запросов→).Топ-5 контейнеров с наибольшей загрузкой ЦП на определенном узле:
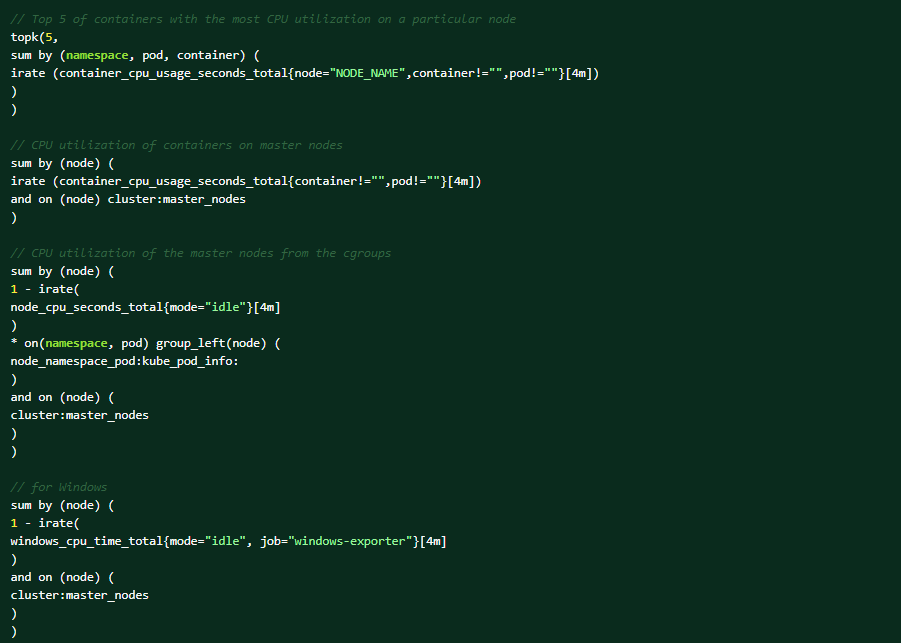
Оповещения могут вызвать следующие условия:
- Появилась новая рабочая нагрузка, которая генерирует больше вызовов к API-серверу и приводит к высокой загрузке ЦП. В этом случае увеличьте ЦП и память на узлах плоскости управления.
- Оповещение запускается на основе метрик узла, поэтому может быть причиной высокой загрузки ЦП компонент на узле.
- APISERVER/etcd обрабатывает больше запросов из-за повторных попыток клиента, вызванных базовым условием.
- неравномерное распределение запросов к инстансу (инстансам) API-сервера из-за http2 (мультиплексирует запросы через одно TCP-соединение). Подсистемы балансировки нагрузки не находятся на уровне приложения и поэтому не понимают http2.
Меры по устранению
- Если рабочая нагрузка создает нагрузку на API-сервер, которая приводит к высокой загрузке ЦП, увеличьте ЦП и память на узлах плоскости управления.
- Если стабильно высокая загрузка ЦП обусловлена ухудшением работы кластера:
- Выясните первопричину ухудшения и определите соответствующие дальнейшие действия.
Поддержка:
Если все вышеперечисленные действия не помогли решить проблему, обратитесь в службу технической поддержки Dell EMC для дальнейшего изучения.
Weitere Informationen
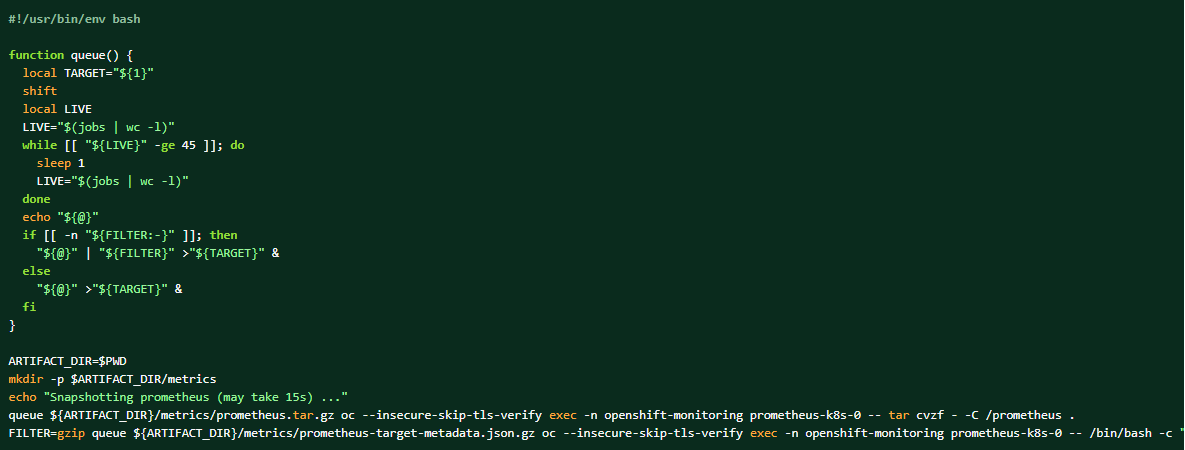
Если пакет журналов собран, данные Prometheus также могут быть выгружены в качестве дополнительных материалов.
Как сделать дамп данных кластера prometheus:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.