OpenShift 事件代碼:1030節點0001
Zusammenfassung: 單個控制平面節點CPU利用率持續偏高,較大的CPU壓力可能導致故障轉移;增加可用的 CPU。
Dieser Artikel gilt für
Dieser Artikel gilt nicht für
Dieser Artikel ist nicht an ein bestimmtes Produkt gebunden.
In diesem Artikel werden nicht alle Produktversionen aufgeführt.
Symptome
極端的 CPU 壓力會導致 kube-apiserver 和 etcd 的序列化速度和性能不佳。發生這種情況時,用戶端有可能看到沒有回應的 API 請求,這些請求再次發出,從而導致更多的 CPU 壓力。
它還可能導致活動探測失敗,因為後端的etcd回應速度很慢。如果一個 kube-apiserver 在這種情況下失敗,您可能會遇到級聯,因為剩餘的 kube-apiserver 也配置不足。
它還可能導致活動探測失敗,因為後端的etcd回應速度很慢。如果一個 kube-apiserver 在這種情況下失敗,您可能會遇到級聯,因為剩餘的 kube-apiserver 也配置不足。
Ursache
當單個控制平面節點上的 CPU 使用率持續偏高時,將觸發此警報。
此警示的緊急性取決於節點維持高 CPU 使用率的時間長度:
此警報的緊急性取決於所有三個控制平面節點的CPU利用率高於兩個控制平面節點可以承受的時間。
此警示的緊急性取決於節點維持高 CPU 使用率的時間長度:
- 嚴重
- 當單個控制平面節點上的 CPU 使用率大於 90% 且超過 1 小時時。
- Warning
- 當單個控制平面節點上的 CPU 使用率超過 90% 且超過 5m 時。
此警報的緊急性取決於所有三個控制平面節點的CPU利用率高於兩個控制平面節點可以承受的時間。
- Warning
- 當所有三個控制平面節點的 CPU 利用率高於兩個控制平面節點可以維持超過 10m 時。
Lösung
診斷:
在 OCP Web 控制臺上執行以下 PromQL 查詢以幫助診斷(觀察→指標→運行查詢)。在特定節點上 CPU 使用率最高的前 5 大容器:
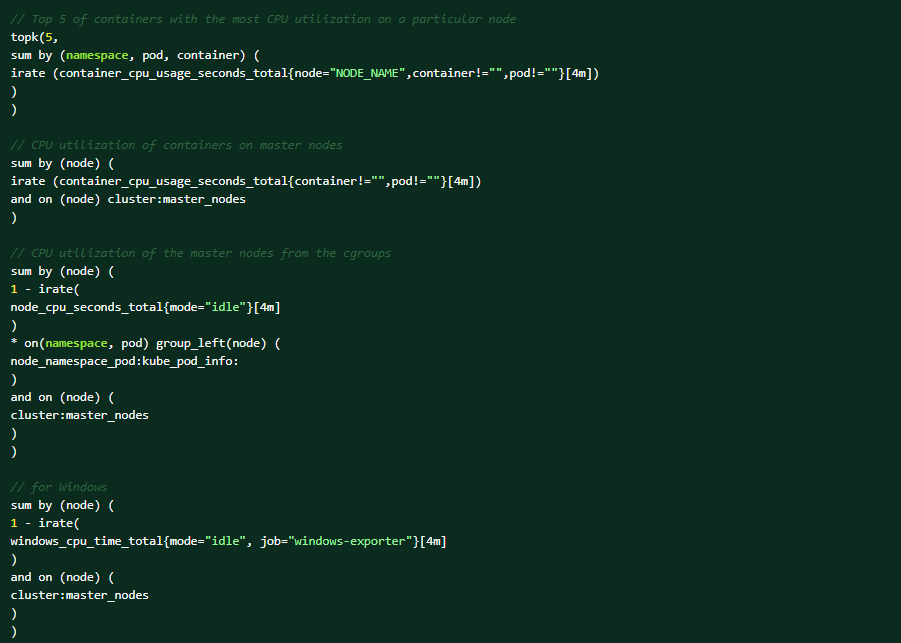
以下是可能觸發警示的情況:
- 有一個新的工作負載會生成更多對 API 伺服器的調用,並導致 CPU 使用率較高。在這種情況下,請增加控制平面節點上的CPU和記憶體。
- 警示是根據節點指標觸發,因此可能是節點上的某個元件造成 CPU 使用率過高。
- APISERVER/etcd 正在處理更多要求,因為用戶端重試是由基礎條件所造成。
- 由於 HTTP2,對 APISERVER 實例的請求分佈不均勻(它通過單個 TCP 連接多路複用請求)。負載均衡器不在應用程式層,因此不理解 HTTP2。
緩解:
- 如果工作負載正在向 API 伺服器生成負載,導致 CPU 使用率較高,請增加控制平面節點上的 CPU 和記憶體。
- 如果 CPU 使用率持續偏高是由於叢集效能降低所導致:
- 找出退化的根本原因,然後相應地確定後續步驟。
支援:
如果上述所有步驟都無法解決問題,請聯絡 Dell EMC 技術支援部門以進一步調查。
Weitere Informationen
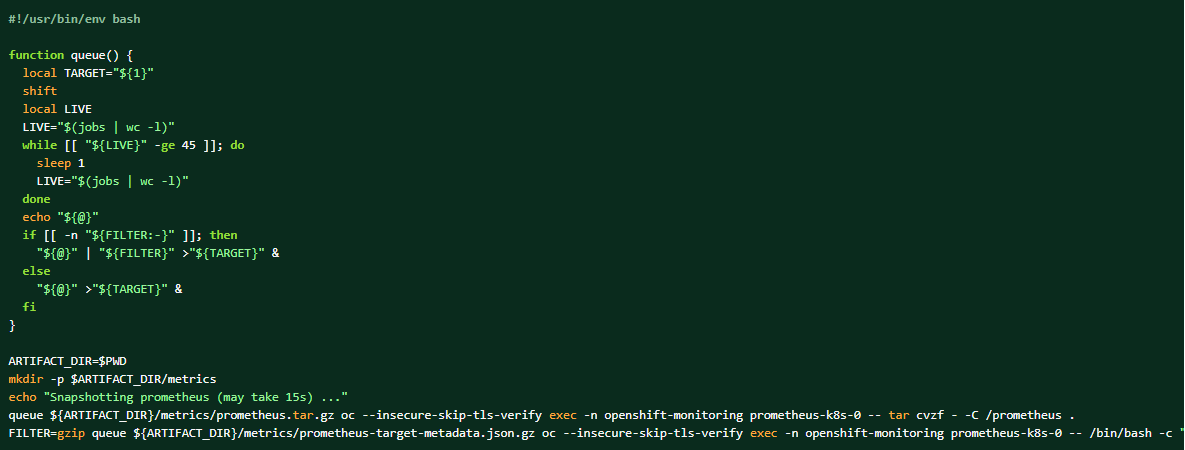
如果收集了日誌包,也可以轉儲普羅米修斯數據作為補充材料。
如何傾印叢集 Prometheus 資料:
Betroffene Produkte
APEX Cloud Platform for Red Hat OpenShiftArtikeleigenschaften
Artikelnummer: 000217405
Artikeltyp: Solution
Zuletzt geändert: 13 Feb. 2026
Version: 3
Antworten auf Ihre Fragen erhalten Sie von anderen Dell NutzerInnen
Support Services
Prüfen Sie, ob Ihr Gerät durch Support Services abgedeckt ist.