Bereitstellen von Oracle 12c Release 2 Grid und RAC-Datenbank unter RHEL 7.x
Summary: Schritte und Bilder zum Bereitstellen von Oracle 12c Release 2 Grid und RAC-Datenbank unter RHEL 7.x
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
1. Software- und Hardwareanforderungen
1.1. Hardwareanforderungen
- Oracle benötigt mindestens 8 GB physischen Speicher
- Der Auslagerungsspeicher ist proportional zur Menge des RAM, die dem System zugewiesen ist.
| RAM | Auslagerungsspeicher |
| Zwischen 1,5 GB und 16 GB | Entspricht der Größe des RAM |
| Mehr als 16 GB | 16 GB |
 Wenn Sie HugePages aktivieren, sollten Sie den HugePages zugewiesenen Speicher vom verfügbaren RAM abziehen, bevor Sie den Auslagerungsspeicher berechnen.
Wenn Sie HugePages aktivieren, sollten Sie den HugePages zugewiesenen Speicher vom verfügbaren RAM abziehen, bevor Sie den Auslagerungsspeicher berechnen.
- Die folgende Tabelle beschreibt den Speicherplatz, der für eine Oracle-Installation erforderlich ist.
| Speicherort der Softwareinstallation | Mindestanforderungen an den Festplattenspeicher |
| Netzinfrastruktur-Startseite | Mindestens 8 GB Festplattenspeicher |
| Oracle-Datenbank-Startseite | Mindestens 6,4 GB Festplattenspeicher |
| Freigegebener Speicherplatz auf der Festplatte | Größen des Datenbank- und Flashback-Wiederherstellungsbereichs |
- Der temporäre Speicherplatz von Oracle (/tmp) muss mindestens 1 GB betragen.
- Ein Monitor, der die Auflösung von 1024 x 768 unterstützt, um das Oracle Universal-Installationsprogramm (OUI) korrekt anzuzeigen
1.2 Netzwerkanforderungen
- Es wird empfohlen, dass jeder Node mindestens drei Netzwerkschnittstellenkarten (NICs) enthält. Eine NIC für das öffentliche Netzwerk, zwei NICs für das private Netzwerk, um eine hohe Verfügbarkeit des Oracle RAC-Clusters zu gewährleisten. Wenn Sie die automatische Speicherverwaltung (ASM) im Cluster verwenden möchten, benötigen Sie mindestens ein Oracle ASM-Netzwerk. Das ASM-Netzwerk kann die Netzwerkschnittstelle mit einem privaten Netzwerk teilen.
- Öffentliche, private und ASM-Schnittstellennamen müssen auf allen Nodes identisch sein. Beispiel: Wenn em1 als öffentliche Schnittstelle auf Node 1 verwendet wird, müssen alle anderen Nodes em1 als öffentliche Schnittstelle verwenden.
- Alle öffentlichen Schnittstellen für jeden Node müssen in der Lage sein, mit allen Nodes im Cluster zu kommunizieren.
- Alle privaten und ASM-Schnittstellen für jeden Node müssen in der Lage sein, mit allen Nodes im Cluster zu kommunizieren.
- Der Hostname jedes Knotens muss dem RFC 952 Standard (www.ietf.org/rfc/rfc952.txt) entsprechen. Hostnamen mit Unterstrich ("_") sind nicht zulässig.
1.3. Betriebssystemanforderungen
- Red Hat Enterprise Linux (RHEL) 7.x (Kernel 3.10.0-693. el7.x86_64 oder höher)
1.3.1. Betriebssystem-Festplattenpartition
Im Folgenden finden Sie die empfohlenen Einträge für das Datenträgerpartitionierungsschema bei der Installation von RHEL 7 mit einer Schnellstartdatei auf den lokalen Festplatten mit mindestens 1,2 TB verfügbarem Speicherplatz.
part /boot --asprimary --fstype="xfs" --ondisk=sda --size=1024
part pv.1 --size=1 --grow --ondisk=sda --asprimary
volgroup rhel7 pv.1
logvol / --name=root --fstype=xfs --vgname=rhel7 --size=51200
logvol swap --fstype swap --name=swap --vgname=rhel7 --size=17408
logvol /home --name=home --fstype=xfs --vgname=rhel7 --size=51200
logvol /var --name=var --fstype=xfs --vgname=rhel7 --size=20480
logvol /opt --name=opt --fstype=xfs --vgname=rhel7 --size=20480
logvol /tmp --name=tmp --fstype=xfs --vgname=rhel7 --size=5120
logvol /u01 --name=u01 --fstype=xfs --vgname=rhel7 --size=1 --grow
2. Vorbereiten der Server für die Installation von Oracle
Stellen Sie vor der Installation von Grid und Datenbank sicher, dass Sie die folgenden Bereitstellungsskripte von Dell EMC installieren, um die Umgebung für die
Oracle-Datenbankinstallation festzulegen.
2.1. Anfügen von Systemen an Red Hat Network (RHN)/Unbreakable Linux Network (ULN) Repository
Alle notwendigen RPMs wurden installiert, bevor eine Grid/DB-Installation durchgeführt wird.
Schritt 1:
- rhel-7-server-optional-rpms
- rhel-7.x
Schritt 2:
Die meisten Voraussetzungen für die Installation von Oracle GRID/DB sind als Teil des Basis-ISO verfügbar. Allerdings gibt es einige wenige RPMs wie compat-libstdc++., die nicht in der ISO-Datei (RH) verfügbar sind und vor der Installation der von Dell für Red Hat bereitgestellten Vorinstallations-RPMs heruntergeladen und manuell installiert werden.
Einrichten eines lokalen yum-Repository zur automatischen Installation der restlichen Abhängigkeits-RPMs für die Durchführung einer GRID/DB-Installation
- Die empfohlene Konfiguration besteht darin, die Dateien über HTTP mit einem Apache-Server (Paketname: httpd) zu bedienen. In diesem Abschnitt wird das Hosten der Repository-Dateien von einem lokalen Dateisystemspeicher aus erläutert. Während andere Optionen für die Host-Repository-Dateien vorhanden sind, werden sie nicht in diesem Dokument beschrieben. Es wird dringend empfohlen, den lokalen Dateisystemspeicher für schnelle und einfache Wartung zu verwenden.
mkdir /media/myISO
mount -o loop myISO.iso /media/myISO
- Um den HTTP-Daemon zu installieren und zu konfigurieren, konfigurieren Sie den Computer, der das Repository für alle anderen Computer hosten soll, um das DVD-Image lokal zu verwenden. Erstellen Sie die Datei /etc/yum.repos.d/local.repo und geben Sie Folgendes ein:
[local]
name=Local Repository
baseurl=file:///media/myISO
gpgcheck=0
enabled=0
- Nun installieren wir den Apache Dienst-Daemon mit dem folgenden Befehl, der auch vorübergehend das lokale Repository für die Abhängigkeitsauflösung aktivieren wird:
yum -y install httpd --enablerepo=local
systemctl start httpd; systemctl enable httpd in RH/OL 7
- Kopieren Sie den Inhalt der DVD in ein veröffentlichtes Web-Verzeichnis, um das Repository mithilfe von Apache zu bedienen. Führen Sie die folgenden Befehle als Root-Benutzer aus und stellen Sie sicher, dass Sie myISO durch den Namen Ihrer ISO-Datei ersetzen:
mkdir /var/www/html/myISO
cp -R /media/myISO/* /var/www/html/myISO
cp -R /media/myISO/* /var/www/html/myISO
- Dieser Schritt ist nur erforderlich, wenn Sie SELinux auf dem Server ausführen, der das Repository hostet. Der folgende Befehl sollte als Root-Benutzer ausgeführt werden und stellt den entsprechenden SELinux-Kontext für die kopierten Dateien wieder her:
restorecon -Rvv /var/www/html/
- Der letzte Schritt besteht darin, den DNS-Namen oder die IP-Adresse des Servers, der das Repository hostet, zu erfassen. Der DNS-Name oder die IP-Adresse des Hostservers wird verwendet, um Ihre yum-Repository-Repo-Datei auf dem Client-Server zu konfigurieren. Nachfolgend wird eine Beispielkonfiguration mit dem RHEL 7.x Server-Medium aufgeführt, die in der Konfigurationsdatei gespeichert ist: /etc/yum.repos.d/myRepo.repo
[myRepo]
name=RHEL 7.x Base ISO DVD
baseurl= http://reposerver.mydomain.com/myISO
enabled=1
gpgcheck=0
Ersetzen Sie reposerver.mydomain.com durch den DNS-Namen oder die IP-Adresse Ihres Servers. Kopieren Sie die Datei nach /etc/yum.repos.d auf allen erforderlichen Servern, auf denen GRID/DB installiert werden soll.
- Installieren Sie die RPM-Datei compat-libstdc++ manuell mit RPM- oder yum-Befehl in das Verzeichnis, in das die RPMs kopiert wurden.
Beispiel: rpm -ivh
yum localinstall -y
Schritt 3:
Überspringen Sie 1 in Schritt 3, wenn Schritt 2 durchgeführt wurde.
- Installieren Sie die RPMs von compat-libstdcc++, indem Sie den folgenden Befehl ausführen:
yum install –y compat-libstdc++.i686
yum install –y compat-libstdc++.x86_64
- Laden/kopieren Sie die von Dell bereitgestellten RPMs, indem Sie zu Dell Oracle Deployment RPMs für Oracle 12cR2 auf RHEL7.x für RH zu den Servern navigieren, auf denen Netz-/DB-Installationen durchgeführt werden. Die Liste der RPMs sieht wie folgt aus, laden Sie nur die erforderlichen RPMs herunter
dell-redhat-rdbms-12cR2-preinstall-2018.06-1.el7.noarch.rpm
dell-redhat-rdbms-utilities-2018.06-1.el7.noarch.rpm
dell-redhat-rdbms-12cR2-preinstall-2018.06-1.el7.noarch.rpm wurde für Folgendes entwickelt:
- Deaktivieren von transparent_hugepages in grub2.cfg
- Deaktivieren von numa in grub2.cfg
- Erstellen der Oracle-Benutzer und -Gruppen oinstall und dba
- Festlegen der Parameter für sysctl kernel
- Festlegen von Benutzerbeschränkungen (NoFile, NPROC, Stack) für Oracle-Benutzer
- Festlegen der Datei NOZEROCONF=yes in /etc/sysconfig/network
dell-redhat-rdbms-utilities-2018.06-1.el7.noarch.rpm wurde für folgende Zwecke entwickelt:
- Erstellen des Grids und der Benutzer und Gruppen asmadmin, asmdba, asmoper, backupdba, dgdba, kmdba
- Festlegen von Benutzerbeschränkungen (NoFile, NPROC, Stack) für Grid-Benutzer
- Festlegen der Parameter für sysctl kernel
- Festlegen von RemoveIPC=no, um sicherzustellen, dass die für Benutzer festgelegten Semaphore nach dem Abmelden des Benutzers nicht verloren gehen
- Installieren Sie die beiden RPMs
yum localinstall –y dell-redhat-rdbms-12cR2-preinstall-2018.06-1.el7.noarch.rpm
Alle Abhängigkeits-RPMs werden installiert, wenn YUM-Repository korrekt eingerichtet ist.
yum localinstall –y dell-redhat-rdbms-utilities-2018.06-1.el7.noarch.rpm
2.2. Netzwerk einrichten
2.2.1. Öffentliches Netzwerk
Stellen Sie sicher, dass es sich bei der öffentlichen IP-Adresse um eine gültige und routingfähige IP-Adresse handelt.
So konfigurieren Sie das öffentliche Netzwerk auf jedem Node
- Melden Sie sich als root-Nutzer an.
- Navigieren Sie zu /etc/sysconfig/network-scripts und bearbeiten Sie die Datei ifcfg-em#, wobei # für die Nummer des Netzwerkgeräts steht.
NAME="Oracle Public"
DEVICE= "em1"
ONBOOT=yes
TYPE= Ethernet
BOOTPROTO=static
IPADDR=<routable IP address>
NETMASK=<netmask>
GATEWAY=<gateway_IP_address>
- Legen Sie den Hostnamen über den folgenden Befehl fest.
hostnamectl set-hostname <Hostname>
wobei < Hostname > der Hostname ist, den wir für die Installation verwenden.
- Geben Sie „service network restart“ ein, um den Netzwerkdienst neu zu starten.
- Geben Sie ifconfig ein, um sicherzustellen, dass die IP-Adressen richtig eingestellt sind.
- Um Ihre Netzwerkkonfiguration zu überprüfen, senden Sie einen Ping-Befehl an alle öffentlichen IP-Adressen eines Clients im LAN, der nicht Teil des Clusters ist.
- Verbinden Sie sich mit jedem Node, um zu überprüfen, ob das öffentliche Netzwerk funktioniert. Geben Sie „ssh“ ein, um zu überprüfen, ob der Secure Shell (SSH)-Befehl funktioniert.
2.2.2. Privates Netzwerk
Die private Netzwerkkonfiguration besteht aus zwei Netzwerkschnittstellen em2 und em3. Das private Netzwerk wird verwendet, um die Verbindung zwischen allen Nodes im Cluster herzustellen. Dies erfolgt über Oracle Redundant Interconnect, auch bekannt als Highly Available Internet Protocol (HAIP), mit dem die Oracle Grid Infrastructure den Datenverkehr auf bis zu vier Ethernet-Geräten für die Kommunikation zwischen privaten Verbindungen aktivieren und einen Lastausgleich vornehmen kann.
Jeder der beiden NIC-Ports für das private Netzwerk muss sich auf einem separaten PCI-Bus befinden.
Das folgende Beispiel enthält schrittweise Anweisungen zum Aktivieren der redundanten Verbindung mithilfe von HAIP in einer neuen Oracle 12c Grid Infrastructure-Installation.
- Bearbeiten Sie die Datei /etc/sysconfig/network-scripts/ifcfg-emX, wobei X die Nummer des em-Geräts ist. Bearbeiten Sie die ifcfg-emX-Konfigurationsdateien der Netzwerkadapter, die für Ihre private Verbindung verwendet werden sollen.
DEVICE=em2
BOOTPROTO=static
HWADDR=
ONBOOT=yes
NM_CONTROLLED=yes
IPADDR=192.168.1.140
NETMASK=255.255.255.0
DEVICE=em3
HWADDR=
BOOTPROTO=static
ONBOOT=yes
NM_CONTROLLED=yes
IPADDR=192.168.1.141
NETMASK=255.255.255.0
- Nachdem Sie beide Konfigurationsdateien gespeichert haben, starten Sie den Netzwerkdienst mit den folgenden Befehlen neu
nmcli connection reload
nmcli device disconnect em2
nmcli connection up em2
- Wiederholen Sie die Schritte für jede Schnittstelle, die geändert wurde.
- Nach Abschluss der obigen Schritte haben Sie jetzt Ihr System zur Aktivierung von HAIP unter Verwendung des Installationsprogramms für die Oracle-Grid-Infrastruktur vorbereitet. Wenn Sie alle Oracle Voraussetzungen erfüllt haben und bereit sind, Oracle zu installieren, müssen Sie em2 und em3 als „private“ Schnittstellen auf dem Bildschirm „Network Interface Usage“ auswählen.
- Dieser Schritt ermöglicht redundante Konnektivität, sobald Ihre Oracle-Grid-Infrastruktur erfolgreich fertiggestellt wurde und ausgeführt wird.
2.2.3. Oracle Flex ASM-Netzwerk
Oracle Flex ASM kann entweder dieselben privaten Netzwerke wie Oracle Clusterware oder seine eigenen dedizierten privaten Netzwerke verwenden. Jedes Netzwerk kann als PUBLIC oder PRIVATE + ASM oder PRIVATE oder ASM klassifiziert werden.
2.2.4. Anforderungen an die IP-Adresse und Namensauflösung
Wir können die IP-Adresse der Cluster-Nodes mit einer der folgenden Optionen konfigurieren.
- Domain Name Server (DNS)
2.2.4.1. Domain Name Server (DNS)
So richten Sie einen Oracle 12c-RAC mithilfe von Oracle (ohne GNS) ein:
Ein SCAN NAME muss im DNS für die Auflösung im Rundlaufverfahren auf drei Adressen (empfohlen) oder mindestens eine Adresse konfiguriert werden. Die SCAN-Adressen müssen sich im selben Subnetz befinden wie die virtuellen IP-Adressen und öffentlichen IP-Adressen.
Für eine hohe Verfügbarkeit und Skalierbarkeit wird empfohlen, den SCAN so zu konfigurieren, dass die Auflösung im Rundlaufverfahren mit drei IP-Adressen verwendet wird. Der Name für den SCAN darf nicht mit einer Ziffer beginnen. Damit die Installation erfolgreich ist, muss der SCAN in mindestens eine Adresse aufgelöst werden.
In der folgenden Tabelle werden die verschiedenen Schnittstellen, IP-Adresseinstellungen und die Auflösungen in einem Cluster beschrieben.
|
Schnittstelle
|
Typ
|
Lösung
|
|
Öffentlich
|
Störgeräusch
|
DNS
|
|
Privat
|
Störgeräusch
|
Nicht erforderlich
|
|
ASM
|
Störgeräusch
|
Nicht erforderlich
|
|
Virtuelle Node-IP
|
Störgeräusch
|
Nicht erforderlich
|
|
Virtuelle IP-Adresse scannen
|
Störgeräusch
|
Nicht erforderlich
|
Konfigurieren eines DNS Servers
So konfigurieren Sie Änderungen auf einem DNS-Server für ein Oracle 12C-Cluster mithilfe von DNS (ohne GNS):
Konfigurieren Sie die Auflösung „SCAN NAME“ auf dem DNS-Server. Ein SCAN NAME, der auf dem DNS-Server mithilfe des Rundlaufverfahrens konfiguriert wurde, sollte in drei öffentliche IP-Adressen aufgelöst werden (empfohlen). die minimale Anforderung ist jedoch eine öffentliche IP-Adresse.
Zum Beispiel:
scancluster IN A 192.0.2.1
IN A 192.0.2.2
IN A 192.0.2.3
Wobei scancluster der bei der Installation des Oracle-Grid bereitgestellte SCAN NAME ist.
Die SCAN IP muss routingfähig sein und sich im öffentlichen Bereich befinden.
Konfigurieren eines DNS-Clients
So konfigurieren Sie die erforderlichen Änderungen auf den Cluster-Nodes für die Namensauflösung:
- Sie müssen die Datei resolv.conf auf den Knoten im Cluster so konfigurieren, dass sie Nameservereinträge enthält, die auf einen DNS-Server aufgelöst werden können.
nmcli connection modify ipv4.dns ipv4.dns-search
- Überprüfen Sie, ob die Sortierkonfiguration /etc/nsswitch.conf den Namen der Servicereihenfolge steuert. In einigen Konfigurationen kann der NIS Probleme mit der Auflösung der Oracle SCAN-Adresse auslösen. Es wird empfohlen, dass Sie den NIS-Eintrag am Ende der Suchliste platzieren.
Beispiel: hosts: dns files nis
3. Vorbereiten von Shared Storage für die Installation von Oracle RAC
In diesem Abschnitt sind die Bezeichnungen Festplatten, Volumes, virtuelle Laufwerke, LUN(s) gleichbedeutend und werden austauschbar verwendet, sofern nicht anders angegeben. In ähnlicher Weise können die Begriffe Streifenelementgröße und Segmentgröße austauschbar verwendet werden.
Oracle RAC erfordert LUNs für die Speicherung Ihrer Oracle Cluster Registry (OCR), Voting Disks, Oracle-Datenbankdateien und Flash Recovery Area (FRA). In der folgenden Tabelle wird das typische, empfohlene Speichervolume-Design für die Oracle 12c-Datenbank aufgeführt.
| Datenbank-Volume-Typ/Zweck | Anzahl der Volumes | Volume-Größe |
| OCR/VOTE | 3 | jeweils 50 GB |
| DATEN | 4 | jeweils 250 GB1 |
| REDO2 | 2 | jeweils mindestens 50 GB |
| FRA | 1 | 100 GB3 |
| TEMP | 1 | 100 GB |
1. Passen Sie die einzelnen Volume-Größen je nach Datenbank an. 2. Es werden mindestens zwei REDO-ASM-Datenträgergruppen empfohlen, jeweils mit mindestens einem Speicher-Volume; 3. Idealerweise sollte die Größe das 1,5-fache der Größe der Datenbank betragen, wenn die nutzbare Speicherkapazität das zulässt.
Die Verwendung von Device Mapper Multipath wird für eine optimale Leistung und
eine dauerhafte Namensbindung über Nodes innerhalb des Clusters empfohlen.
eine dauerhafte Namensbindung über Nodes innerhalb des Clusters empfohlen.
3.1. Einrichten von Device Mapper Multipath für XtremIO-Speicher
Der Gerätezuordnungs-Multipfad dient dazu, mehrere E/A-Pfade zu aktivieren, um die Leistung zu verbessern und eine konsistente Benennung zu gewährleisten. Multipathing erreicht dies durch die Kombination von E/A-Pfaden in einem Gerätezuordnungspfad und die korrekte Lastverteilung der E/A. In diesem Abschnitt finden Sie die Best Practices für die Einrichtung des Gerätezuordnungs-Multipathing in Ihrem Dell PowerEdge-Server. Vergewissern Sie sich, dass Ihr Device Mapper und Ihr Multipfad-Treiber mindestens der unten gezeigten Version oder höher entsprechen:
- rpm -qa | grep device-mapper-multipath
device-mapper-multipath
- Aktivieren Sie Multipath über mpathconf –enable
- Konfigurieren Sie XtremIO Multipath, indem Sie/etc/multipath.conf mit folgendem ändern:
device {
vendor XtremIO
product XtremApp
path_grouping_policy multibus
path_checker tur
path_selector "queue-length 0"
rr_min_io_rq 1
user_friendly_names yes
fast_io_fail_tmo 15
failback immediate
}
- Fügen Sie jedem Volume mit der entsprechenden scsi_id die entsprechenden benutzerfreundlichen Namen hinzu. Wir können scsi_ids mit dem folgenden Befehl abfragen:
/usr/lib/udev/scsi_id -g -u -d /dev/sdX
- Suchen Sie den Multipfad-Abschnitt in der Datei /etc/multipath.conf. In diesem Abschnitt stellen Sie die scsi_id jedes Volumes bereit und geben einen Alias an, um eine konsistente Benennungskonvention für alle Knoten zu gewährleisten. Ein Beispiel ist im Folgenden dargestellt:
multipaths {
multipath {
wwid <out put of step4 for volume1>
alias alias_of_volume1
}
multipath {
wwid <out put of step4 for volume2>
alias alias_of_volume2
}
}
- Starten Sie Ihren Multipfad-Daemon-Dienst neu:
Service multipathd restart
- Überprüfen Sie, ob der Alias für Multipfad-Volumes ordnungsgemäß angezeigt wird.
multipath -ll
- Wiederholen Sie alle Schritte für alle Nodes
3.2. Partitionieren der freigegebenen Festplatte
In diesem Abschnitt wird beschrieben, wie Sie mit dem Dienstprogramm "parted" eine einzelne Partition auf einem Volume/virtuellen Datenträger erstellen können, die sich über die gesamte Festplatte erstreckt.
Partitionieren Sie jedes Datenbankvolume, das mit Device-Mapper eingerichtet wurde, indem Sie den folgenden Befehl ausführen:
$> parted -s /dev/mapper/<volume1> mklabel msdos
$> parted -s /dev/mapper/<volume1> primary 2048s 100%
Wiederholen Sie diesen Vorgang für alle erforderlichen Volumes.
-
Wiederholen Sie die obigen Schritte für alle Volumes und starten Sie multipathd auf allen anderen Nodes neu.
systemctl restart multipathd.service
-
Starten Sie das System neu, wenn die neu erstellte Partition nicht ordnungsgemäß angezeigt wird.
3.3 Verwenden von udev-Regeln für Datenträgerberechtigungen und Persistenz
Red Hat Enterprise Linux 7.x hat die Möglichkeit, udev-Regeln zu verwenden, um sicherzustellen, dass das System die Berechtigungen von Geräteknoten ordnungsgemäß verwaltet. In diesem Fall geht es um die ordnungsgemäße Einstellung der Berechtigungen für die LUNs/Volumes, die vom Betriebssystem erkannt werden. Es ist wichtig, darauf hinzuweisen, dass die udev-Regeln in der aufgelisteten Reihenfolge ausgeführt werden. Wenn Sie udev-Regeln zum Festlegen von Berechtigungen erstellen, fügen Sie das Präfix "60-" und das Suffix ".rules" am Ende des Dateinamens ein.
- Erstellen Sie eine Datei 60-oracle-asmdevices.rules unter /etc/udev/rules.d
- Stellen Sie sicher, dass jedes Blockgerät einen Eintrag in der Datei aufweist (siehe Abbildung unten).
#---------------------start udev rule contents ------------------------#
KERNEL=="dm-*", ENV =="C1_OCR1p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_OCR2p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_OCR3p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_DATA1p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_DATA2p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_DATA3p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_DATA4p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_REDO1p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_REDO2p?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_FRA?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
KERNEL=="dm-*", ENV =="C1_TEMP?", OWNER:="grid", GROUP:="asmadmin", MODE="0660"
#-------------------------- end udev rule contents ------------------#
- Führen Sie "udevadm trigger" aus, um die Regel anzuwenden.
- Kopieren Sie die udev-Regeln auf alle Nodes und führen Sie den Auslöser udevadm zum Anwenden von Regeln aus.
4. Oracle 12c Grid Infrastructure für einen Cluster installieren
In diesem Abschnitt finden Sie Informationen zur Installation der Oracle 12C-Grid-Infrastruktur für ein Cluster. Stellen Sie vor der Installation der Oracle 12c-RAC-Software auf Ihrem System sicher, dass Sie das Betriebssystem, das Netzwerk und den Speicher auf der Grundlage der Schritte in den vorherigen Abschnitten in diesem Dokument bereits konfiguriert haben, und suchen Sie Ihr Oracle 12c-Kit.
4.1 Konfigurieren der Systemuhr-Einstellungen für alle Nodes
Um Ausfälle während des Installationsverfahrens zu vermeiden, konfigurieren Sie alle Nodes mit identischen Systemuhr-Einstellungen. Synchronisieren Sie die Systemuhrzeit des Node mit dem Cluster Time Synchronization Service (CTSS), der in Oracle 12c integriert ist. Um CTSS zu aktivieren, deaktivieren Sie den ntpd-Service (Network Time Protocol Daemon) des Betriebssystems mithilfe der folgenden Befehle in dieser Reihenfolge:
-
systemctl stop chronyd.service
-
systemctl disable chronyd.service
-
mv /etc/chrony.conf /etc/ntp.chrony.orig
Wenn nicht anders angegeben, sind die folgenden Schritte für Node 1 ihrer Clusterumgebung erforderlich.
- Melden Sie sich als root-Nutzer an.
- Wenn Sie nicht in einer grafischen Umgebung sind, starten Sie das X Window-System, indem Sie Folgendes eingeben: startx
- Öffnen Sie ein Terminalfenster und geben Sie Folgendes ein: xhost +
- Binden Sie den Oracle Grid Infrastructure-Datenträger ein.
- Melden Sie sich als Grid-Benutzer an, z. B.: su - grid.
- Geben Sie den folgenden Befehl ein, um das universelle Oracle-Installationsprogramm zu starten: /runInstaller
- Wählen Sie im Fenster „Select Configuration“ die Option „Configure Grid Infrastructure for a Cluster“, und klicken Sie auf „Next“.

- Wählen Sie im Fenster „Cluster Configuration“ die Option „Configure an Oracle Standalone Cluster“ aus und klicken Sie auf „Next“.

- Geben Sie im Fenster „Grid Plug and Play Information“ die folgenden Informationen ein:
-
Cluster Name: Geben Sie einen Namen für Ihr Cluster ein.
-
SCAN Name: Geben Sie den im DNS Server registrierten Namen ein, der für das gesamte Cluster eindeutig ist. Weitere Informationen zum Einrichten des SCAN Name finden Sie unter „IP-Adresse und Namensauflösung – Voraussetzungen“.
-
SCAN-Port – behalten Sie den Standardport 1521 bei.
-

- Klicken Sie im Fenster „Cluster Node Information“ auf „Add“, um zusätzliche Knoten hinzuzufügen, die von der Oracle Grid Infrastructure verwaltet werden müssen.
- Geben Sie die Informationen zum öffentlichen Hostnamen für Mitglieds-Nodes der Hub- und Leaf-Cluster ein.
- Geben Sie die Rolle des Cluster Mitglieds-Node ein.
- Wiederholen Sie die obigen drei Schritte für jeden Node im Cluster.

- Klicken Sie auf „SSH connectivity“ und konfigurieren Sie die kennwortlose SSH-Verbindung, indem Sie das Betriebssystemkennwort für den Grid-Benutzer eingeben und auf „Setup“ klicken.
- Klicken Sie auf „OK“ und dann auf „Next“, um zum nächsten Fenster zu wechseln.

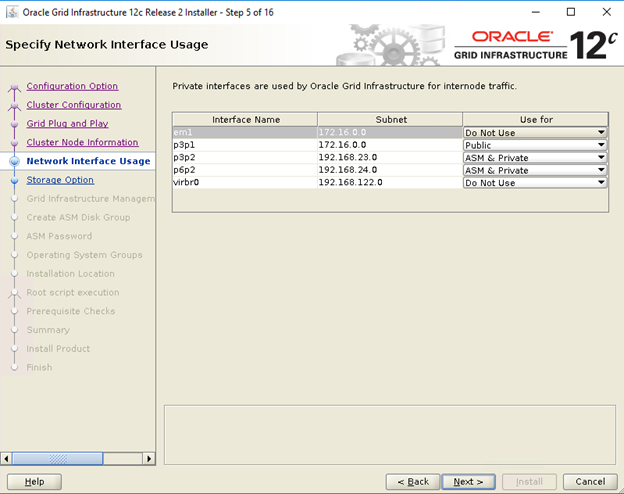
- Vergewissern Sie sich, dass im Fenster „Specify Network Interface Usage“ die korrekten Schnittstellennutzungstypen für die Schnittstellennamen ausgewählt sind. Wählen Sie in der Dropdownliste „Use for“ den Typ der erforderlichen Schnittstelle aus. Die verfügbaren Optionen sind „Public“, „Private“, „ASM“, „ASM and private“. Klicken Sie auf "Next" (Weiter).
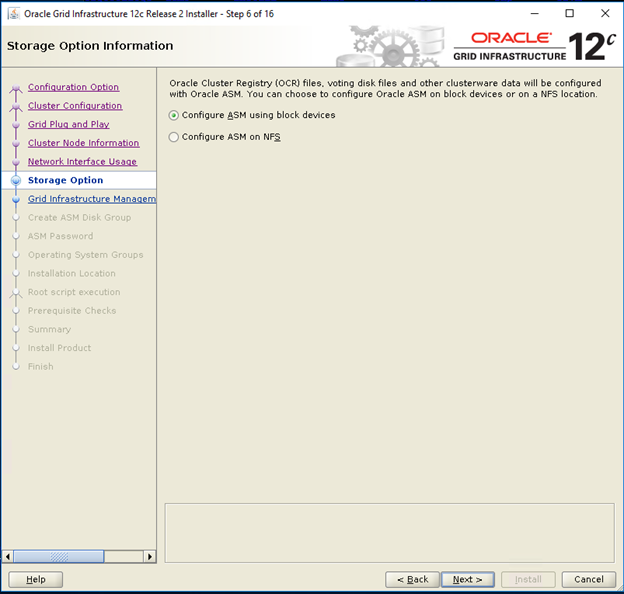
- Wählen Sie im Informationsfenster für Speicheroptionen die Option „Configure ASM using block devices“ aus und klicken Sie auf „Next“.
- Wählen Sie im Fenster „Grid Infrastructure Management Repository Option“ die Option „No“ für „Configure Grid Infrastructure Management“ aus und klicken Sie auf „Next“.
- Geben Sie im Fenster „Create ASM Disk Group“ die folgenden Informationen ein:
-
Disk Group Name: Geben Sie einen Namen ein, z. B.: OCR
-
Redundancy: Wählen Sie für Ihre OCR und Voting Disks „High“, wenn fünf ASM-Datenträger verfügbar sind, „Normal“, wenn drei ASM-Datenträger verfügbar sind, oder „External“, wenn ein ASM-Datenträger verfügbar ist (nicht empfohlen).
-
: Wenn keine geeigneten Festplatten angezeigt werden, klicken Sie auf „Change Discovery Path“ und geben Sie „/dev/mapper/*“ ein.

- Wählen Sie im Fenster „ASM Password“ die entsprechende Option unter „Specify the passwords for these accounts“ und geben Sie die entsprechenden Werte für das Kennwort ein. Klicken Sie auf „Next“ (Weiter).
- Wählen Sie im Fenster „Failure Isolation Support“ die Option „Do Not use Intelligent Platform Management Interface (IPMI)“ aus.
- Wählen Sie im Fenster mit den Verwaltungsoptionen die Option „default“ aus und klicken Sie auf „Next“.
- Wählen Sie im Fenster „Privileged Operating Systems Groups“ Folgendes aus:
-
asmdba unter „Oracle ASM DBA (OSASM) Group“
-
asmoper unter „Oracle ASM Operator (OSOPER) Group“
-
asmdba unter „Oracle ASM Administrator (OSDBA) Group“
-

- Geben Sie im Fenster „Specify Installation Location“ die Werte des Oracle Base- und Softwarespeicherorts gemäß der Konfiguration im Dell Oracle Utilities-RPM an.
Die Standardspeicherorte, die im Dell Oracle Utilities-RPM verwendet werden, sind:
- Oracle Base -/u01/app/grid
- Softwarespeicherort - /u01/app/12.1.0/grid_1

- Geben Sie im Fenster „Create Inventory“ den Speicherort für Ihr Inventarverzeichnis an. Klicken Sie auf "Next" (Weiter).
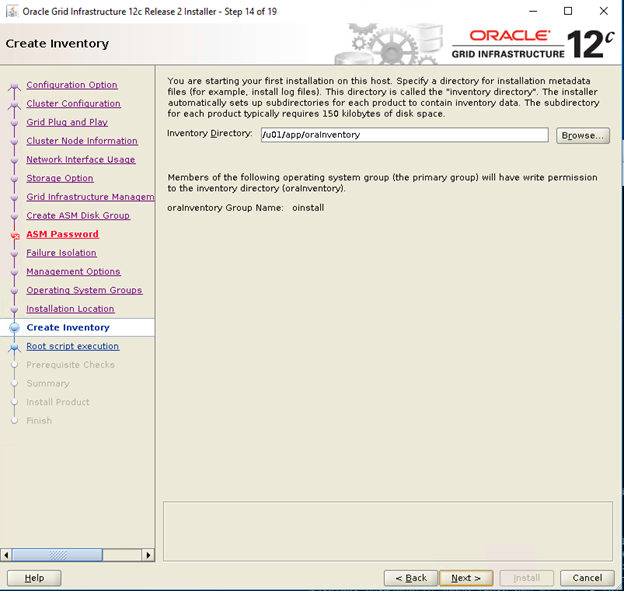
 Der Standardspeicherort, der auf dem Dell Oracle Utilities-RPM für das Inventarverzeichnis basiert, ist /u01/app/oraInventory
Der Standardspeicherort, der auf dem Dell Oracle Utilities-RPM für das Inventarverzeichnis basiert, ist /u01/app/oraInventory
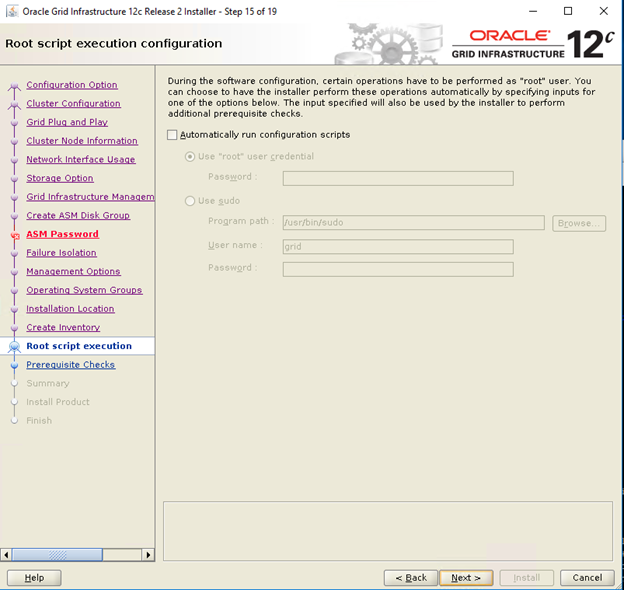
- Deaktivieren Sie im Fenster „Root script execution configuration“ das Kontrollkästchen „Automatically Run Configuration Scripts“ und klicken Sie auf „Next“.
- Überprüfen Sie im Zusammenfassungsfenster alle Einstellungen und wählen Sie „Install“.
- Überprüfen Sie im Fenster „Install Product“ den Status der Grid-Infrastruktur-Installation.
- Führen Sie im Fenster „Execute Configuration Scripts“ auf beiden Nodes root.sh-Skripte aus und klicken Sie auf „OK“.
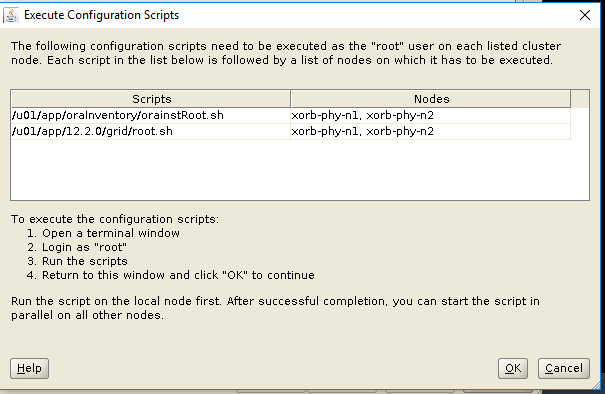
- Klicken Sie im Fenster „Finish“ auf „Close“.
5. Oracle 12c-Datenbank installieren
5.1. Installieren der Oracle 12c-Datenbank (RDBMS)-Software
Wenn nicht anders angegeben, sind die folgenden Schritte für Node 1 ihrer Clusterumgebung erforderlich.
- Melden Sie sich als root an und geben Sie Folgendes ein: xhost+.
- Binden Sie den Oracle Database 12c-Datenträger ein.
- Melden Sie sich als Oracle-Benutzer an, indem Sie Folgendes eingeben: su - oracle
- Führen Sie das Installationsskript von Ihrem Oracle-Datenbankmedium aus:
<CD_mount>/runInstaller
- Geben Sie im Fenster „Configure Security Updates“ Ihre Anmeldeinformationen für My Oracle Support ein, um Sicherheitsupdates zu erhalten, oder klicken Sie auf „Next“.
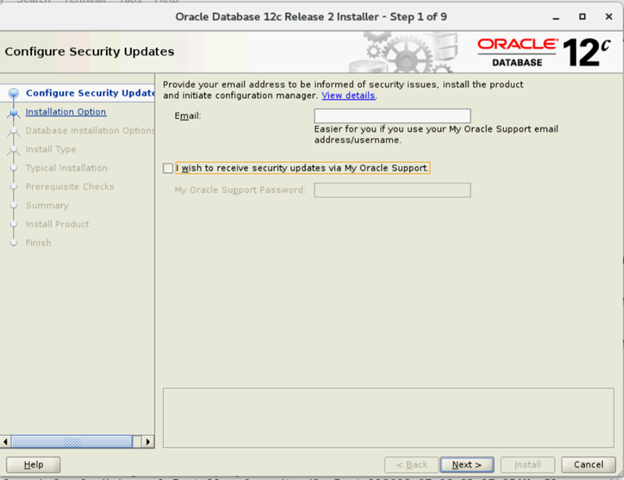
- Wählen Sie im Fenster „Select Installation Option“ die Option „Install Database Software Only“ aus.

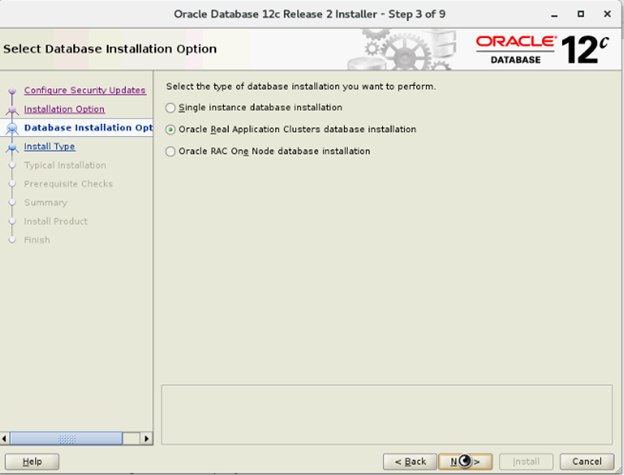
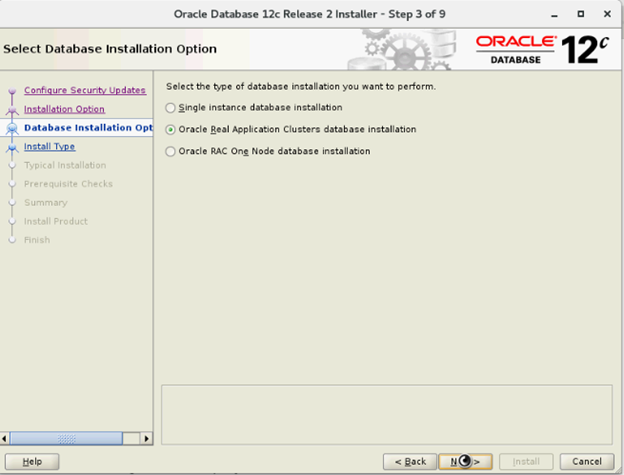
- Wählen Sie im Fenster „Select Database Installation Options“ die Option „Oracle Real Application Clusters Database Installation“ aus und klicken Sie auf „Next“.
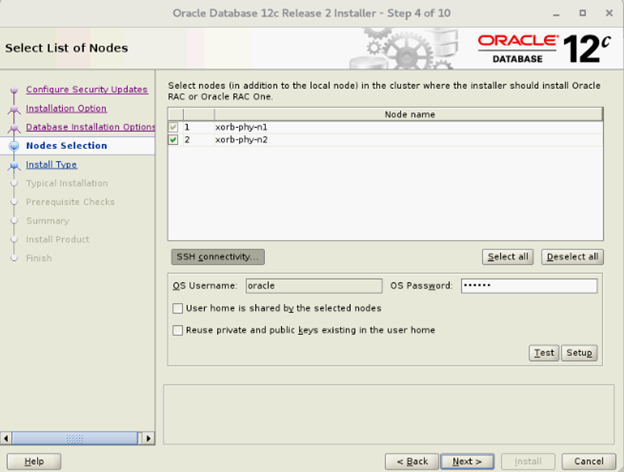
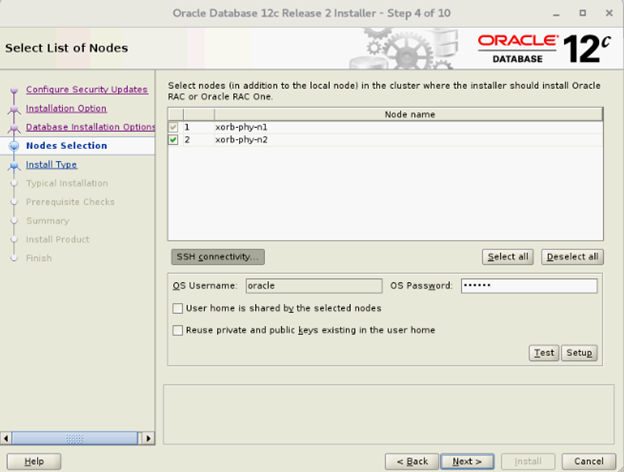
- Wählen Sie im Fenster „Select List of Nodes“ alle Hub-Nodes aus und lassen Sie die Leaf-Nodes aus, klicken Sie auf „SSH Connectivity“ und konfigurieren Sie Ihre kennwortlose SSH-Verbindung, indem Sie das Betriebssystemkennwort für den Oracle-Benutzer eingeben und „Setup“ auswählen. Klicken Sie auf „OK“ und dann auf „Next“, um zum nächsten Fenster zu wechseln.
- Wählen Sie im Fenster „Select Database Installation Options“ die Option „Oracle Real Application Clusters Database Installation“ aus und klicken Sie auf „Next“.
- Wählen Sie im Fenster „Select List of Nodes“ alle Hub-Nodes aus und lassen Sie die Leaf-Nodes aus, klicken Sie auf „SSH Connectivity“ und konfigurieren Sie Ihre kennwortlose SSH-Verbindung, indem Sie das Betriebssystemkennwort für den Oracle-Benutzer eingeben und „Setup“ auswählen. Klicken Sie auf „OK“ und dann auf „Next“, um zum nächsten Fenster zu wechseln.
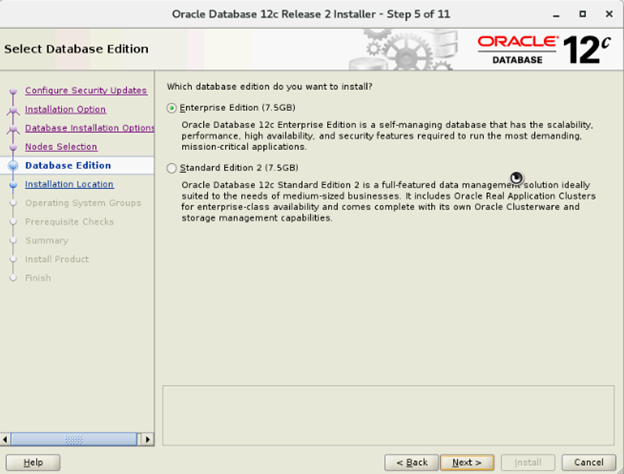
- Wählen Sie im Fenster „Select Database Edition“ die Option „Enterprise Edition“ aus und klicken Sie auf „Next“.
- Geben Sie im Fenster „Specify Installation Location“ die Werte des Oracle Base-Speicherorts gemäß der Konfiguration im Dell Oracle Utilities-RPM an.
Die Standardspeicherorte, die im Dell Oracle Utilities-RPM verwendet werden, lauten wie folgt:
- Oracle Base—/u01/app/oracle
- Softwarespeicherort /u01/app/oracle/product/12.1.0/dbhome_2

- Wählen Sie im Fenster „Privileged Operating System Groups“ die Option „dba“ für die Gruppe „Database Administrator (OSDBA)“, „dba“ für die Gruppe „Database Operator (OSOPER)“, „backupdba“ für die Gruppe „Database Backup and Recovery (OSBACKUPDBA)“, „dgdba“ für die Gruppe „Data Guard administrative (OSDGDBA)“ und „kmdba“ für die Gruppe „Encryption Key Management administrative (OSKMDBA)“ aus und klicken auf „Next“.

- Überprüfen Sie im Fenster „Summary“ die Einstellungen und wählen Sie „Install“.
- Nach Abschluss des Installationsvorgangs wird der Assistent zum Ausführen von Konfigurationsskripten angezeigt. Befolgen Sie die Anweisungen im Assistenten und klicken Sie auf „OK“.

Root.sh sollte jeweils auf einem Node ausgeführt werden.
- Klicken Sie im Fenster „Finish“ auf „Close“.
6. Erstellen von Datenträgergruppen mithilfe des ASM Configuration Assistant (ASMCA)
Dieser Abschnitt enthält Verfahren zum Erstellen der ASM-Datenträgergruppe für die Datenbankdateien und Flashback Recovery Area (FRA).
- Melden Sie sich als Grid-Benutzer an und starten Sie asmca über /u01/app/12.2.0/grid/bin/asmca
- Erstellen Sie „DATA“-Datenträgergruppen mit externer Redundanz durch Auswahl geeigneter Festplatten.
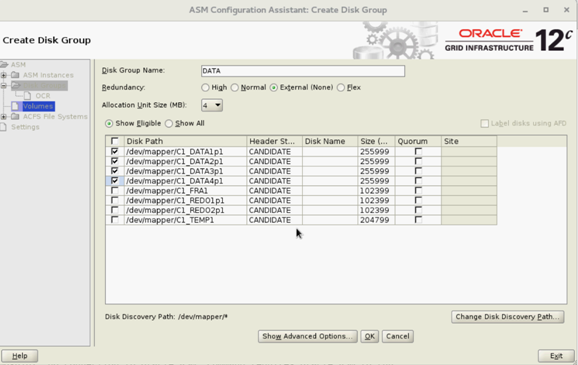
- Erstellen Sie zwei „REDO“-Datenträgergruppen – REDO1 und REDO2 – mit externer Redundanz, indem Sie mindestens einen potenziellen Datenträger pro REDO-Datenträgergruppe auswählen.

- Erstellen Sie „FRA“-Datenträgergruppen mit externer Redundanz durch Auswahl geeigneter Festplatten.

- Erstellen Sie „TEMP“-Datenträgergruppen mit externer Redundanz durch Auswahl geeigneter Festplatten.

- Überprüfen Sie alle erforderlichen Festplattengruppen und klicken Sie auf „Exit“, um das Dienstprogramm ASMCA zu schließen.

- Ändern Sie das ASM-Striping auf „fine-grained“ für die Datenträgergruppen REDO, TEMP und FRA als Grid-Benutzer mit den folgenden Befehlen.
Vor der Ausführung von Sie DBCA müssen wir auf differenziertes Striping umsteigen.
SQL> ALTER DISKGROUP REDO ALTER TEMPLATE onlinelog ATTRIBUTES (fine)
SQL> ALTER DISKGROUP TEMP ALTER TEMPLATE tempfile ATTRIBUTES (fine)
SQL> ALTER DISKGROUP FRA ALTER TEMPLATE onlinelog ATTRIBUTES (fine)
7. Erstellen einer Datenbank mit DBCA
Wenn nicht anders angegeben, gelten die folgenden Schritte für Node 1 ihrer Clusterumgebung:
- Melden Sie sich als Oracle-Benutzer an
- Führen Sie das DBCA-Dienstprogramm von $ aus, indem Sie Folgendes eingeben: $/bin/dbca
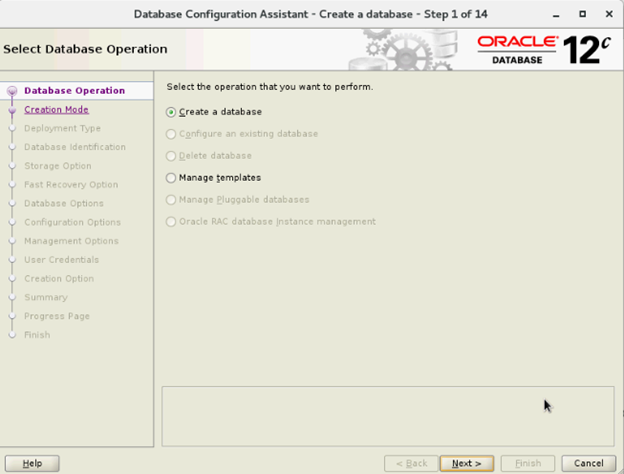
- Wählen Sie im Fenster „Select Database Operation“ die Option „Create Database“ aus und klicken Sie auf „Next“.
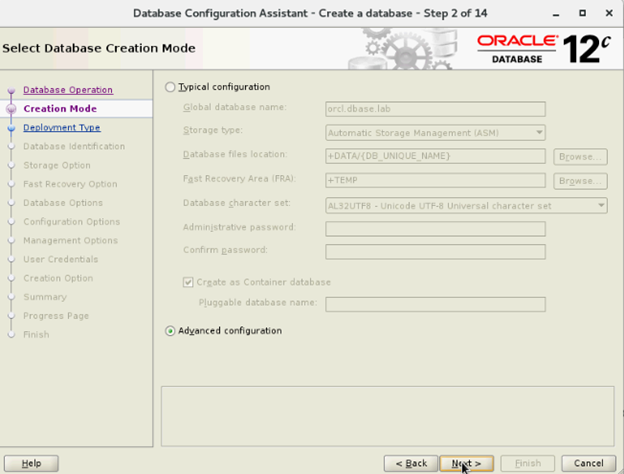
- Wählen Sie im Fenster „Select Database Creation Mode“ die Option „Advanced Mode“ und klicken Sie auf „Next“.
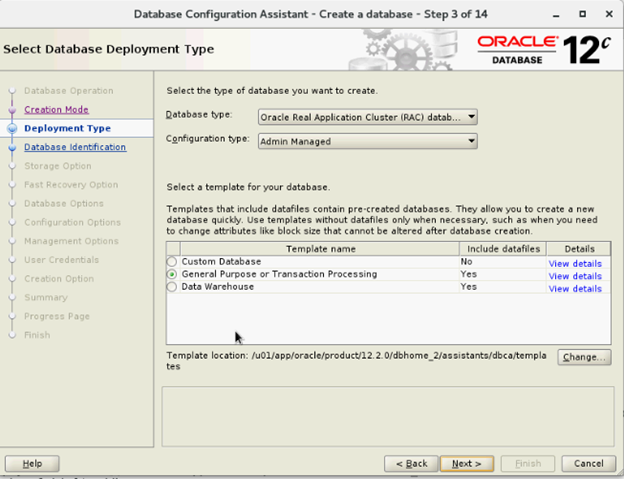
- Wählen Sie im Fenster „Select Database Deployment“ unter „Database type“ die Option „Oracle Real Application Cluster (RAC) database“ und unter „Configuration Type “ die Optionen „Admin-Managed“ und „Select Template“ aus und klicken Sie auf „Next“.
- Wählen Sie im Fenster „Select List of nodes“ die Nodes aus und klicken Sie auf „Next“.
- Im Fenster „Specify Database Identification Details“:

- Wählen Sie im Fenster „Storage Options“ die Option „Datafiles Storage Location“ und deaktivieren Sie die Option „Use Oracle-Managed Files (OMF)“ und klicken Sie auf „Next“.

- Wählen Sie im Fenster „Select Fast Recovery Option“ die Option „Specify Fast Recovery Area“ und klicken Sie auf „Next“.

- Wählen Sie im Fenster "Select Oracle Data Vault Config Option" die Standardwerte aus und klicken Sie auf „Next“.

- Geben Sie im Fenster „Specify Configuration Options“ die erforderlichen SGA- und PGA-Werte ein und klicken Sie auf „Next“.

- Wählen Sie im Fenster „Specify Management Options“ die Option „default“ aus und klicken Sie auf „Next“.
- Geben Sie im Fenster „Specify Database User Credentials“ ein Kennwort ein und klicken Sie auf „Next“.

- Klicken Sie im Fenster „Select Database Creation Options“ auf „Customize Storage Locations“.

- Erstellen/modifizieren Sie die Redo-Protokollgruppen auf Grundlage der folgenden Entwurfsempfehlung
| Redo-Protokollgruppennummer | Thread-Nummer | Speicherort der Datenträgergruppe | Redo-Protokollgröße |
| 1 | 1 | +REDO1 | 5 GB |
| 2 | 1 | +REDO2 | 5 GB5 GB |
| 3 | 1 | +REDO1 | 5 GB |
| 4 | 1 | +REDO2 | 5 GB |
| 5 | 2 | +REDO1 | 5 GB |
| 6 | 2 | +REDO2 | 5 GB |
| 7 | 2 | +REDO1 | 5 GB |
| 8 | 2 | +REDO2 | 5 GB |

- Klicken Sie im Zusammenfassungsfenster auf „Finish“, um die Datenbank zu erstellen.

Die Erstellung der Datenbank kann einige Zeit dauern.
- Klicken Sie nach Abschluss der Datenbankerstellung im Fenster „Finish“ auf „Close“.

Affected Products
Red Hat Enterprise Linux Version 7Article Properties
Article Number: 000179557
Article Type: How To
Last Modified: 21 Feb 2021
Version: 4
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.