PowerEdge : AMD Rome : architecture et premiers résultats de performance en HPC
Summary: Dans le monde du HPC actuel, le processeur AMD EPYC de dernière génération, nommé Rome.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. Laboratoire d’innovation en matière d’IA et de HPC, octobre 2019
Dans le monde du HPC actuel, le processeur AMD EPYC de dernière génération, nommé Rome, n’a pas besoin d’être présenté. Au cours des derniers mois, nous avons évalué des systèmes basés sur Rome dans le laboratoire d’innovation en matière d’IA et de HPC
et Dell Technologies a récemment annoncé
des serveurs prenant en charge cette architecture processeur. Ce premier article de blog de la série consacrée à Rome décrit l’architecture du processeur, explique comment l’optimiser pour les performances HPC et présente les premiers résultats de microbenchmark. Les articles suivants aborderont les performances applicatives dans les domaines de la CFD, du CAE, de la dynamique moléculaire, de la simulation météorologique et d’autres applications.
Architecture
Rome est la 2e génération de processeur EPYC d’AMD, succédant à la 1re génération, Naples.
L’une des principales différences architecturales entre Naples et Rome, bénéfique pour le HPC, est la nouvelle puce E/S de Rome. Dans Rome, chaque processeur est un boîtier multipuces composé de jusqu’à neuf chiplets, comme illustré à la Figure 1. On y trouve une puce E/S centrale en 14 nm qui regroupe toutes les fonctions d’E/S et de mémoire : contrôleurs mémoire, liens Infinity Fabric dans le socket et connectivité inter-socket, ainsi que PCIe. Chaque socket dispose de huit contrôleurs mémoire prenant en charge huit canaux DDR4 à 3 200 MT/s. Un serveur simple socket peut gérer jusqu’à 130 voies PCIe Gen4. Un système à deux sockets peut prendre en charge jusqu’à 160 voies PCIe Gen 4.
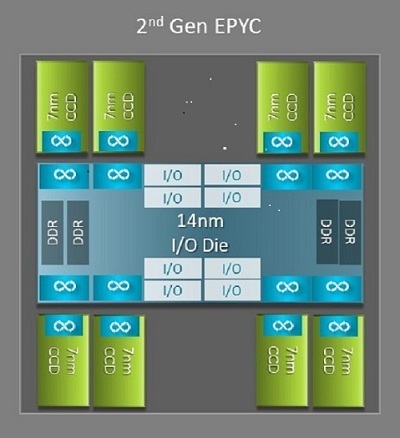
(Figure 1 : Boîtier multipuces Rome avec une puce E/S centrale et jusqu’à huit puces de cœur)
Autour de la puce E/S centrale se trouvent jusqu’à huit chiplets de cœur gravés en 7 nm. Le chiplet de cœur est appelé Core Cache Die, ou CCD. Chaque CCD est doté de cœurs de processeur basés sur la microarchitecture Zen2, d’un cache L2 et d’un cache L3 de 32 Mo. Le CCD possède lui-même deux Core Cache Complexes (CCX), chaque CCX intégrant jusqu’à quatre cœurs et 16 Mo de cache L3. La Figure 2 illustre un CCX.

(Figure 2 : Un CCX avec quatre cœurs et 16 Mo de mémoire cache L3 partagée)
Les différents modèles de processeurs Rome ont un nombre de cœurs variable,
mais possèdent tous une puce E/S centrale.
À l’extrémité supérieure se trouve un modèle de processeur 64 cœurs, par exemple, l’EPYC 7702. La sortie de lstopo montre que ce processeur dispose de 16 CCX par socket, chaque CCX comprenant quatre cœurs (voir Figures 3 et 4), soit 64 cœurs par socket. Avec 16 Mo de cache L3 par CCX, soit 32 Mo par CCD, ce processeur atteint 256 Mo de cache L3. Notez cependant que le cache L3 total dans Rome n’est pas partagé entre tous les cœurs. Les 16 Mo de cache L3 de chaque CCX sont indépendants et partagés uniquement par les cœurs du CCX concerné (voir Figure 2).
Un processeur 24 cœurs comme l’EPYC 7402 dispose d’un cache L3 de 128 Mo. La sortie de lstopo (Figures 3 et 4) illustre qu’un modèle particulier dispose de trois cœurs par CCX et de huit CCX par socket.
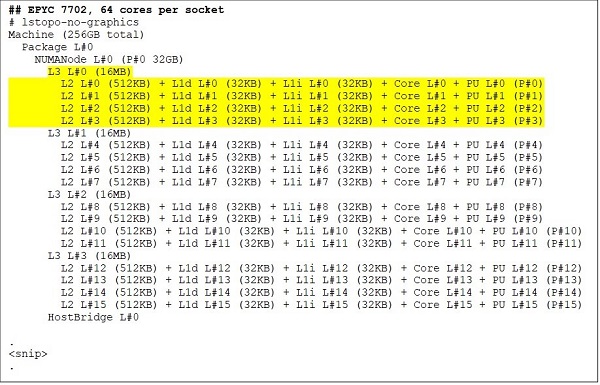
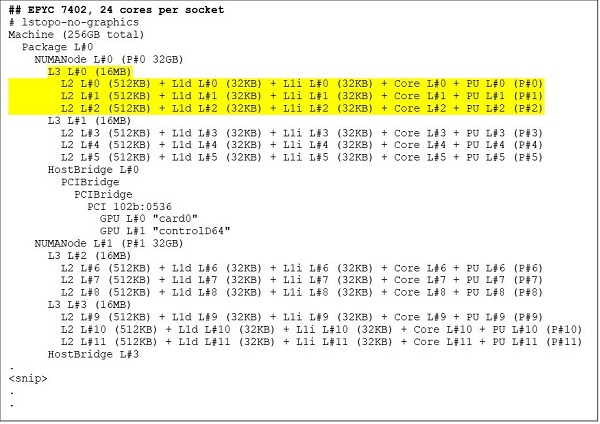
(Figures 3 et 4 : Sortie de lstopo pour des processeurs 64 cœurs et 24 cœurs)
Quel que soit le nombre de CCD, chaque processeur Rome est logiquement divisé en quatre quadrants, les CCD étant répartis de manière aussi équilibrée que possible, avec deux canaux mémoire par quadrant. La puce E/S centrale peut être considérée comme assurant logiquement le support de ces quatre quadrants du socket.
Options du BIOS basées sur l’architecture Rome
Dans Rome, la puce E/S centrale contribue à améliorer la latence mémoire par rapport à celle mesurée dans Naples. Cela permet aussi de configurer le processeur comme un seul domaine NUMA, offrant un accès mémoire uniforme à tous les cœurs du socket. Ceci est expliqué ci-dessous.
Les quatre quadrants logiques d’un processeur Rome permettent de partitionner le processeur en plusieurs domaines NUMA. Ce paramètre est appelé NUMA par socket ou NPS.
- NPS1 signifie que le processeur Rome est un seul domaine NUMA, regroupant tous les cœurs du socket et toute la mémoire dans ce domaine unique. La mémoire est entrelacée sur les huit canaux de mémoire. Tous les périphériques PCIe sur le socket appartiennent à ce domaine NUMA unique
- NPS2 partitionne le processeur en deux domaines NUMA, avec la moitié des cœurs et la moitié des canaux de mémoire sur le socket de chaque domaine NUMA. La mémoire est entrelacée sur les quatre canaux de mémoire de chaque domaine NUMA
- NPS4 partitionne le processeur en quatre domaines NUMA. Ici, chaque quadrant est un domaine NUMA et la mémoire est entrelacée sur les deux canaux de mémoire de chaque quadrant. Les périphériques PCIe sont associés à l’un des quatre domaines NUMA du socket, en fonction du quadrant de la puce E/S où se trouve la racine PCIe de ce périphérique.
- Tous les processeurs ne prennent pas en charge tous les paramètres NPS.
Lorsqu’il est disponible, NPS4 est recommandé pour le HPC, car il devrait fournir la bande passante mémoire la plus élevée, la latence la plus faible, et la plupart de nos applications sont optimisées pour NUMA. Lorsque NPS4 n’est pas disponible, nous recommandons d’utiliser le paramètre NPS le plus élevé supporté par le modèle de processeur : NPS2, voire NPS1.
Étant donné la multitude d’options NUMA disponibles sur les plateformes basées sur Rome, le BIOS PowerEdge propose deux méthodes différentes d’énumération des cœurs dans le cadre de l’énumération MADT. L’énumération linéaire numérote les cœurs dans l’ordre, en remplissant un socket CCX, puis CCD, avant de passer au socket suivant. Sur un processeur 32 cœurs, les cœurs 0 à 31 se trouvent sur le premier socket, les cœurs 32 à 63 sur le deuxième socket. L’énumération par permutation circulaire numérote les cœurs de façon alternée entre les régions NUMA. Dans ce cas, les cœurs pairs sont placés sur le premier socket et les cœurs impairs sur le second. Par souci de simplicité, nous recommandons l’énumération linéaire pour le HPC. Voir la Figure 5 pour un exemple d’énumération linéaire des cœurs sur un serveur double socket 64 cœurs configuré en NPS4. Dans cette figure, chaque bloc de quatre cœurs correspond à un CCX, et chaque ensemble de huit cœurs contigus correspond à un CCD.
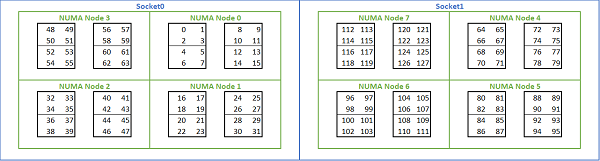
(Figure 5 : Énumération linéaire des cœurs sur un système double socket, 64 cœurs par socket, configuration NPS4 sur un modèle de processeur à 8 CCD)
Une autre option spécifique au BIOS Rome est appelée Preferred IO Device. Ce bouton de réglage est important pour la bande passante InfiniBand et le débit de messages. Elle permet à la plateforme de prioriser le trafic pour un périphérique d’E/S donné. Cette option est disponible sur les plateformes Rome à un ou deux sockets. Pour obtenir un débit de messages optimal lorsque tous les cœurs du processeur sont actifs, le périphérique InfiniBand doit être sélectionné comme périphérique préféré dans le menu BIOS.
À l’instar de Naples, Rome prend en charge l’hyper-threading ou processeur logique. Pour le HPC, nous laissons cette option désactivée, mais certaines applications peuvent bénéficier de l’activation du processeur logique. Restez à l’affût de nos prochains billets de blog sur les études applicatives en dynamique moléculaire.
À l’instar de Naples, Rome dispose de l’option CCX as NUMA Domain. Cette option expose chaque CCX comme un nœud NUMA. Sur un système double socket avec des processeurs disposant de 16 CCX chacun, ce réglage expose 32 domaines NUMA. Dans cet exemple, chaque socket contient huit CCD, soit 16 CCX. Chaque CCX peut être activé comme son propre domaine NUMA, donnant 16 nœuds NUMA par socket et 32 dans un système à deux sockets. Pour le HPC, nous recommandons de laisser l’option CCX as NUMA Domain sur la valeur par défaut : désactivé. L’activation de cette option devrait aider les environnements virtualisés.
À l’instar de Naples, Rome permet aussi de configurer le système en mode Performance Determinism ou Power Determinism. En mode Performance Determinism, le système fonctionne à la fréquence attendue pour le processeur, ce qui réduit les écarts de performance entre serveurs. En mode Power Determinism, le système fonctionne au TDP maximal du processeur, ce qui met en évidence les variations issues de la fabrication, rendant certains serveurs plus rapides que d’autres. Dans ce cas, tous les serveurs consomment la puissance maximale spécifiée pour le processeur, ce qui fixe la consommation électrique mais entraîne des différences de performance entre serveurs.
Comme vous pouvez vous y attendre sur les plateformes PowerEdge, le BIOS dispose d’une méta-option appelée System Profile. La sélection du profil système Performance-Optimized active le turbo boost, désactive les C-states et positionne le curseur de déterminisme sur Power Determinism, optimisant ainsi la performance.
Résultats de performance : STREAM, HPL, microbenchmarks InfiniBand
Beaucoup de lecteurs attendent surtout cette section, allons donc à l’essentiel.
Dans le laboratoire d’innovation en matière d’IA et de HPC, nous avons construit un cluster de 64 serveurs Rome baptisé Minerva. En plus du cluster homogène Minerva, nous avons pu évaluer quelques autres échantillons de processeurs Rome. Notre banc d’essai est décrit dans le Tableau 1 et le Tableau 2.
(Tableau 1 : Modèles de processeurs Rome évalués dans cette étude)
| Processeur | Cœurs par socket | Config | Horloge de base | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4 cœurs par CCX | 2,0 GHz | 200 W |
| 7502 | 32c | 4 cœurs par CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4 cœurs par CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3 cœurs par CCX | 2,8 GHz | 180 W |
(Tableau 2 Banc d’essai)
| Composant | Détails |
|---|---|
| Serveur | PowerEdge C6525 |
| Processeur | Comme indiqué dans le Tableau 1 Double socket |
| Mémoire | 256 Go, 16 x 16 Go de mémoire DDR4 à 3 200 MT/s |
| Interconnexion | ConnectX-6 Mellanox Infini Band HDR100 |
| Système d’exploitation | Red Hat Enterprise Linux 7,6 |
| Noyau | 3.10.0.957.27.2.e17.x86_64 |
| Disque | Module 240 Go SATA SSD M.2 |
STREAM
Les tests de bande passante mémoire sur Rome sont présentés à la Figure 6. Ces tests ont été exécutés en mode NPS4. Nous avons mesuré une bande passante mémoire d’environ 270 à 300 Gbit/s sur notre serveur PowerEdge C6525 à deux sockets en utilisant tous les cœurs du serveur sur les quatre modèles de processeurs répertoriés dans le Tableau 1. Lorsqu’un seul cœur est utilisé par CCX, la bande passante mémoire système est supérieure d’environ 9 à 17 % par rapport aux mesures effectuées avec tous les cœurs actifs.
La majorité des charges applicatives HPC sollicitent soit tous les cœurs disponibles du système, soit les centres HPC adoptent un mode haut débit avec plusieurs tâches exécutées simultanément sur chaque serveur. Par conséquent, la bande passante mémoire en mode tous cœurs actifs est la mesure la plus représentative des capacités de bande passante mémoire et de bande passante mémoire par cœur du système.
La Figure 6 trace également la bande passante mémoire mesurée sur la plateforme EPYC Naples de génération précédente, qui disposait elle aussi de huit canaux mémoire par socket, mais fonctionnant à 2 667 MT/s. La plateforme Rome offre entre 5 % et 19 % de bande passante mémoire totale en plus par rapport à Naples, principalement grâce à la mémoire plus rapide à 3 200 MT/s. Même avec 64 cœurs par socket, le système Rome peut fournir plus de 2 Gbit/s par cœur.
En comparant les différentes configurations NPS, on a mesuré une bande passante mémoire environ 13 % plus élevée avec NPS4 qu’avec NPS1, comme illustré à la Figure 7.
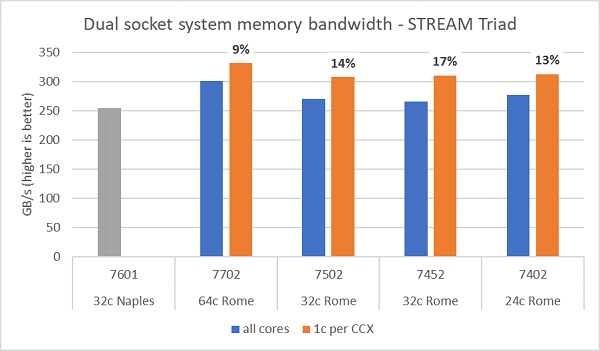
(Figure 6 : Bande passante mémoire STREAM Triad sur un système double socket NPS4)
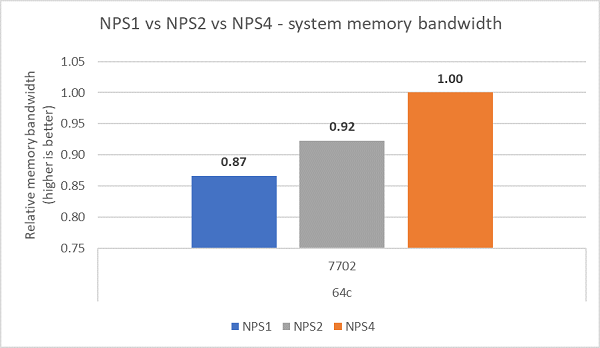
(Figure 7 : Bande passante mémoire : comparaison NPS1, NPS2 et NPS4)
Bande passante et taux de messages InfiniBand
La Figure 8 représente la bande passante InfiniBand sur un seul cœur, pour des tests unidirectionnels et bidirectionnels. Le banc d’essai utilisait HDR100 à 100 Gbit/s, et le graphique illustre les performances attendues à débit nominal pour ces essais.
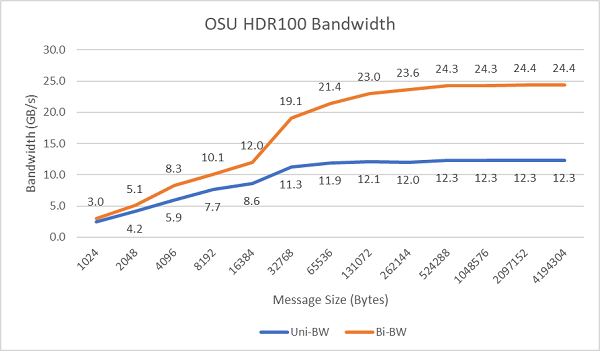
Figure 8 : Bande passante InfiniBand (un seul cœur)
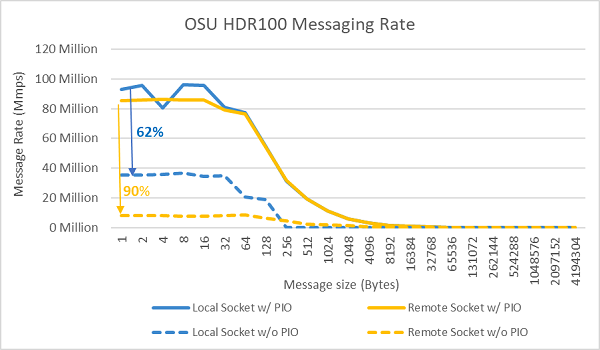
Figure 9 : Taux de messages InfiniBand (tous les cœurs)
Des tests de débit de messages ont ensuite été réalisés en utilisant tous les cœurs d’un socket dans les deux serveurs testés. Lorsque l’option Preferred IO est activée dans le BIOS et que l’adaptateur ConnectX-6 HDR100 est configuré comme périphérique préféré, le taux de messages en mode tous cœurs est supérieur à celui obtenu quand Preferred IO n’est pas activé, comme le montre la Figure 9. Cela illustre l’importance de cette option BIOS pour l’optimisation HPC, en particulier pour la scalabilité des applications multinœuds.
HPL
La microarchitecture Rome peut exécuter 16 opérations flottantes double précision (DP FLOP) par cycle, soit deux fois plus que Naples (8 FLOP/cycle). Rome bénéficie ainsi d’un pic théorique de FLOPS quatre fois supérieur à Naples : 2x grâce aux capacités accrues en calcul flottant, et 2x grâce au doublement du nombre de cœurs (64 cœurs contre 32 cœurs). La Figure 10 présente les résultats HPL mesurés pour les quatre modèles de processeurs Rome testés, ainsi que nos résultats précédents sur un système basé sur Naples. L’efficacité HPL de Rome est indiquée par les pourcentages figurant au-dessus des barres du graphique, et elle est plus élevée pour les modèles de processeurs à TDP inférieur.
Les tests ont été effectués en mode Power Determinism. Une variation d’environ 5 % des performances a été constatée entre 64 serveurs configurés de manière identique, les résultats présentés se situent donc dans cette fourchette.
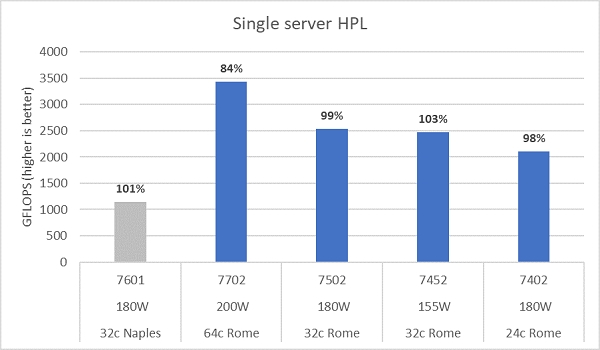
(Figure 10 : HPL sur un serveur unique en NPS4)
Ensuite, des tests HPL multinœuds ont été réalisés, et les résultats sont présentés à la Figure 11. L’efficacité HPL de l’EPYC 7452 reste supérieure à 90 % sur 64 nœuds, mais les fluctuations entre 102 %, 97 % et 99 % méritent d’être examinées de plus près.
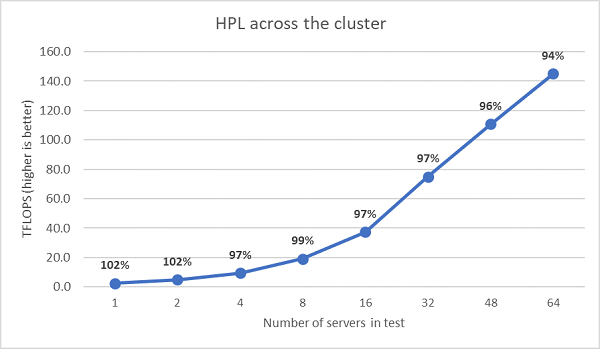
(Figure 11 : HPL multi-nœuds, double socket EPYC 7452 via InfiniBand HDR100)
Récapitulatif et les prochaines étapes :
les premières études de performance sur des serveurs basés sur Rome montrent des résultats conformes aux attentes pour notre première série de benchmarks HPC. Le réglage du BIOS est essentiel pour obtenir les meilleures performances, et des options de configuration sont disponibles dans notre profil BIOS pour charge applicative HPC, pouvant être appliquées en usine ou via les utilitaires de gestion de systèmes Dell EMC.
Le laboratoire d’innovation en matière d’IA et de HPC dispose d’un nouveau cluster PowerEdge basé sur Rome de 64 serveurs : Minerva. Surveillez les mises à jour de la page pour nos prochains articles de blog, qui présenteront les études de performance applicative menées sur ce cluster Minerva.