PowerFlex 4.6 Několik modulů se neustále restartuje
Summary: Během a po novém nasazení nebo upgradu skupiny prostředků (RG) nebo upgradu na 4.6.1 se stále restartuje několik podů.
Symptoms
Nové nasazení nástroje PowerFlex manager 4.6.1 nebo upgrade na verzi 4.6.1 s 200+ uzly uzlů SO a CO
Obrazovka během restartování ukazuje nedostatek paměti: 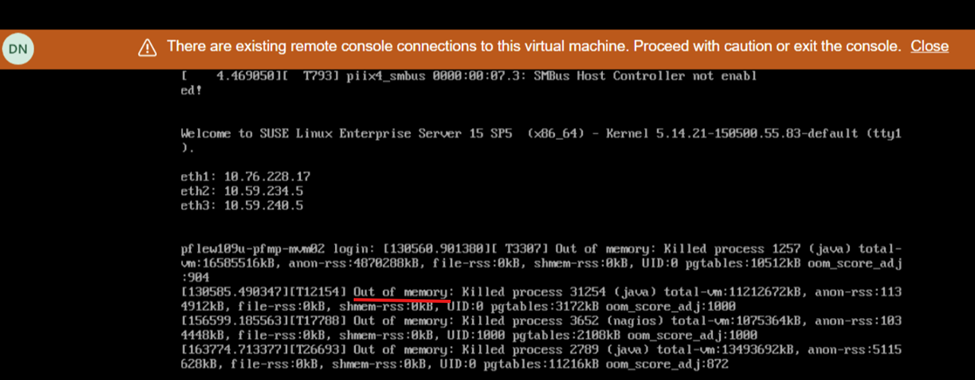
Důsledky
- Nestabilní stav systému a uživatelské rozhraní přestalo reagovat / není k dispozici
Cause
Kvůli softwarové chybě v platformě PowerFlex Manager Platform (PFMP) verze 4.6.1 a vyšší vyžadují systémy s více než 200 uzly (SO i CO) více výpočetních zdrojů, než bylo dříve uvedeno: 28 jader procesoru a 64 GB paměti.
Resolution
Postup vypnutí
- Přihlaste se k MVM a spuštěním následujících příkazů zastavte databázi:
- Ověřte stav databáze:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Ověřte, že je databáze vypnutá:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Ověřte stav databáze:
- Vypněte nástroj MVM.
Aktualizace prostředků MVM
U nových nasazení nebo upgradů na verzi 4.6.1 by uzly MVM musely splňovat další požadavky na paměť a procesor:
- CPU – 28 jader
- Paměť: 64 GB
Postup zapnutí
- Zapnutí všech virtuálních mechanik MVM
- U každého MVM spusťte následující příkaz pro kontrolu stavu služby rke2-server:
kubectl get nodesV závislosti na stavu serveru rke2 postupujte následovně:Stav serveru rke2
Postupujte následovně
Aktivní
Přejděte k dalšímu kroku
Aktivující
Opakujte příkaz pro kontrolu stavu rke2-server až do aktivního stavu.
Failed
Pokuste se spustit službu spuštěním následujícího příkazu:
systemctl start rke2-server - Jakmile je rke2-server aktivní na všech MVM, ujistěte se, že jsou všechny uzly ve stavu Ready:
kubectl get nodes - Jakmile jsou uzly připravené, přejděte k dalšímu kroku. Pokud se zobrazí chybová zpráva, počkejte několik minut a zkuste to znovu.
- Obnovení databáze operátoru monitorování clusteru (CMO):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Ověřte databázi CMO:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Obnovení databáze operátoru monitorování clusteru (CMO):
- Monitorování stavu platformy PowerFlex pro správu:
- Spuštěním následujícího příkazu určete číslo portu pro nástroj pro monitorování platformy pro správu PowerFlex:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Počkejte 20–30 minut a zkontrolujte celkový stav platformy PowerFlex pro správu.
- Spuštěním následujícího příkazu určete číslo portu pro nástroj pro monitorování platformy pro správu PowerFlex:
- Přejděte do části http://< node IP>:p ort/, kde IP adresa uzlu je IP adresa pro správu nakonfigurovaná pro libovolný z uzlů MVM (nikoli IP adresa příchozího přenosu dat nebo IP adresa nástroje PowerFlex Manager).
- Klikněte na stav PFMP a počkejte, dokud se barva všech položek nezmění na zelenou.
- Hlavní uživatelské rozhraní PFMP bude nyní přístupné (někdy může čekat 20 až 30 minut).
Dotčené verze
PFMP 4.6.1
Opraveno ve verzi
PFMP 4.8