PowerFlex 4.6 Flere pods bliver ved med at genstarte
Summary: Flere pods bliver ved med at genstarte under og efter en ny implementering eller opgradering til 4.6.1 (Storage Only (SO) og CO (Compute Only (CO) Resource Group (RG).
Symptoms
Ny implementering af PowerFlex Manager 4.6.1 eller opgradering til 4.6.1 med 200+ SO- og CO-noder
Skærmvisning under genstart viser mangel på hukommelse: 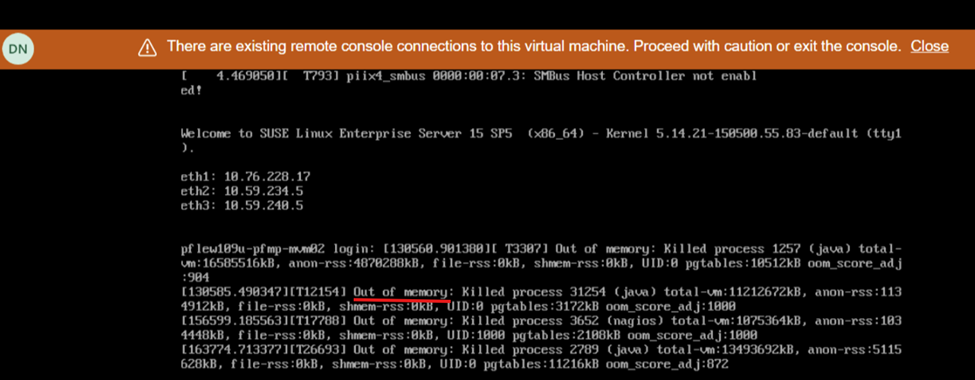
Påvirkning
- Ustabil systemtilstand, og brugergrænsefladen holder op med at svare/er ikke tilgængelig
Cause
På grund af et softwareproblem i PowerFlex Manager Platform (PFMP) version 4.6.1 og nyere kræver systemer med over 200 noder (både SO og CO) flere computerressourcer end tidligere annonceret: 28 CPU-kerner og 64 GB hukommelse.
Resolution
Procedure for slukning
- Log på en MVM, og kør følgende kommandoer for at stoppe databasen:
- Valider databasens tilstand:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Bekræft, at databasen er lukket ned:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Valider databasens tilstand:
- Sluk for MVM en
Opdater MVM-ressourcer
For nye implementeringer eller opgraderinger til 4.6.1 skal MVM-noderne opfylde de ekstra hukommelses- og CPU-krav:
- CPU – 28 kerner
- Hukommelse – 64 GB
Procedure for tænding
- Tænd for alle MVM'er
- Kør følgende kommando på hver MVM for at kontrollere status for rke2-servertjenesten:
kubectl get nodesGør følgende afhængigt af rke2-serverstatus:Status på rke2-serveren
Gør følgende:
Aktiv
Gå til næste trin
Aktivering
Gentag kommandoen for at kontrollere status for rke2-serveren, indtil den er aktiv.
Mislykket
Forsøg at starte tjenesten ved at køre følgende kommando:
systemctl start rke2-server - Når rke2-serveren er aktiv på alle MVM'erne, skal du sikre dig, at alle noder er i klar tilstand:
kubectl get nodes - Når noderne er klar, skal du gå til næste trin. Hvis der vises en fejlmeddelelse, skal du vente et par minutter og prøve igen.
- Gendan CMO-databasen (Cluster Monitoring Operator):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Kontroller CMO-databasen:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Gendan CMO-databasen (Cluster Monitoring Operator):
- Overvåg status for PowerFlex-administrationsplatformen:
- Kør følgende kommando for at identificere portnummeret for overvågningshjælpeprogrammet til PowerFlex-administrationsplatformen:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Vent i 20-30 minutter, og kontrollér PowerFlex-administrationsplatformens overordnede sundhedstilstand.
- Kør følgende kommando for at identificere portnummeret for overvågningshjælpeprogrammet til PowerFlex-administrationsplatformen:
- Gå til http://< node IP>:p ort/, hvor nodens IP-adresse er en administrations-IP-adresse, der er konfigureret på en af MVM'erne (ikke IP-adressen for indgående data eller PowerFlex Manager).
- Klik på PFMP-status, og vent på, at alle poster bliver grønne.
- PFMP's primære brugergrænseflade vil nu være tilgængelig (nogle gange kan det vente i 20 til 30 minutter).
Påvirkede versioner
PFMP 4.6.1
Fast i version
PFMP 4.8