PowerFlex 4.6 Mehrere Pods werden immer wieder neu gestartet
Summary: Während und nach einer Neubereitstellung (RG) einer reinen Storage- (SO) und reinen Compute-Ressourcengruppe (RG) einer Ressourcengruppe (4.6.1) oder einem Upgrade auf 4.6.1 werden immer wieder mehrere Pods neu gestartet. ...
Symptoms
Neue Bereitstellung von PowerFlex Manager 4.6.1 oder Upgrade auf 4.6.1 mit 200+ SO- und CO-Nodes
Die Bildschirmansicht während des Neustarts zeigt einen Mangel an Arbeitsspeicher an: 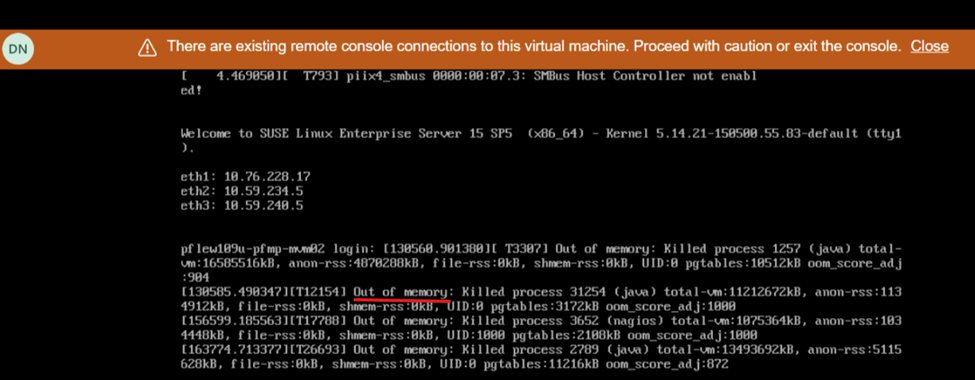
Auswirkungen
- Der Systemzustand ist instabil und die Benutzeroberfläche reagiert nicht mehr/ist nicht verfügbar.
Cause
Aufgrund eines Softwareproblems in der PowerFlex Manager Platform (PFMP)-Version 4.6.1 und höher benötigen Systeme mit mehr als 200 Nodes (sowohl SO als auch CO) mehr Rechenressourcen als zuvor angegeben: 28 CPU-Cores und 64 GB Arbeitsspeicher.
Resolution
Verfahren zum Ausschalten
- Melden Sie sich bei einem MVM an und führen Sie die folgenden Befehle aus, um die Datenbank zu beenden:
- Überprüfen Sie den Integritätsstatus der Datenbank:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Überprüfen Sie, ob die Datenbank heruntergefahren wurde:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Überprüfen Sie den Integritätsstatus der Datenbank:
- Ausschalten des MVM
Aktualisieren von MVM-Ressourcen
Für neue Bereitstellungen oder Upgrades auf 4.6.1 müssen die MVM-Nodes die zusätzlichen Arbeitsspeicher- und CPU-Anforderungen erfüllen:
- CPU – 28 Kerne
- Arbeitsspeicher: 64 GB
Verfahren zum Einschalten
- Schalten Sie alle MVMs ein
- Führen Sie auf jedem MVM den folgenden Befehl aus, um den Status des rke2-server-Service zu überprüfen:
kubectl get nodesGehen Sie je nach Status des rke2-Servers wie folgt vor:Status des rke2-Servers
Gehen Sie folgendermaßen vor:
Aktiv
Fahren Sie mit dem nächsten Schritt fort
Aktivierend
Wiederholen Sie den Befehl, um den Status des rke2-Servers zu überprüfen, bis er aktiv ist.
Ausgefallen
Versuchen Sie, den Service zu starten, indem Sie den folgenden Befehl ausführen:
systemctl start rke2-server - Sobald der rke2-Server auf allen MVMs aktiv ist, stellen Sie sicher, dass sich alle Nodes im Status "Ready" befinden:
kubectl get nodes - Wenn die Nodes bereit sind, fahren Sie mit dem nächsten Schritt fort. Wenn eine Fehlermeldung angezeigt wird, warten Sie einige Minuten und versuchen Sie es erneut.
- Stellen Sie die CMO-Datenbank (Cluster Monitoring Operator) wieder her:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Überprüfen Sie die CMO-Datenbank:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Stellen Sie die CMO-Datenbank (Cluster Monitoring Operator) wieder her:
- Überwachen Sie den Status der PowerFlex-Managementplattform:
- Führen Sie den folgenden Befehl aus, um die Portnummer für das Dienstprogramm zur Überwachung der PowerFlex-Managementplattform zu identifizieren:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Warten Sie 20 bis 30 Minuten und überprüfen Sie den Gesamtintegritätsstatus der PowerFlex-Managementplattform.
- Führen Sie den folgenden Befehl aus, um die Portnummer für das Dienstprogramm zur Überwachung der PowerFlex-Managementplattform zu identifizieren:
- Navigieren Sie zu http://< node IP>:p ort/, wobei die Node-IP-Adresse eine Management-IP-Adresse ist, die auf einem der MVMs konfiguriert ist (nicht die Ingress- oder PowerFlex Manager-IP-Adresse).
- Klicken Sie auf PFMP status und warten Sie, bis alle Einträge grün werden.
- Die PFMP-Hauptnutzeroberfläche ist jetzt zugänglich (manchmal kann es 20 bis 30 Minuten dauern).
Betroffene Versionen
PFMP 4.6.1
Behoben in Version
PFMP 4.8