PowerFlex 4.6 Varios pods se reinician una y otra vez
Summary: Varios pods se siguen reiniciando durante y después de una nueva implementación o actualización a 4.6.1 de un grupo de recursos (RG) de solo almacenamiento (SO) y solo computación (CO). ...
Symptoms
Nueva implementación de PowerFlex Manager 4.6.1 o actualización a 4.6.1 con 200+ nodos de SO y CO
En la vista de pantalla durante el reinicio, se muestra una falta de memoria: 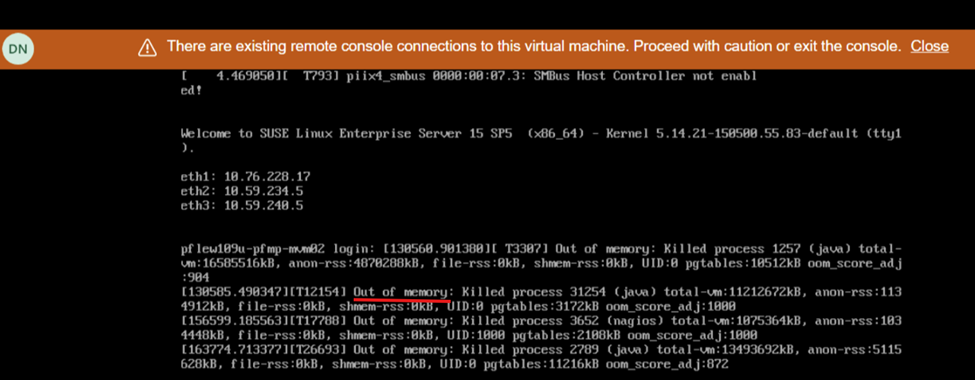
Impacto
- Estado inestable del sistema y la interfaz de usuario deja de responder o no está disponible
Cause
Debido a un problema de software en las versiones 4.6.1 y superiores de PowerFlex Manager Platform (PFMP), los sistemas con más de 200 nodos (tanto SO como CO) requieren más recursos informáticos que los anunciados anteriormente: 28 núcleos de CPU y 64 GB de memoria.
Resolution
Procedimiento de apagado
- Inicie sesión en un MVM y ejecute los siguientes comandos para detener la base de datos:
- Valide el estado de la base de datos:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Valide que la base de datos esté apagada:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Valide el estado de la base de datos:
- Apague el MVM
Actualizar recursos de MVM
Para implementaciones nuevas o actualizaciones a 4.6.1, los nodos MVM tendrían que cumplir con los requisitos adicionales de memoria y CPU:
- CPU: 28 núcleos
- Memoria: 64 GB
Procedimiento de encendido
- Encienda todos los MVM
- En cada MVM, ejecute el siguiente comando para comprobar el estado del servicio rke2-server:
kubectl get nodesRealice lo siguiente según el estado del servidor rke2:Estado del servidor rke2
Realice lo siguiente
Activo
Ir al paso siguiente
Activador
Repita el comando para comprobar el estado del servidor rke2 hasta que esté activo.
Fracasado
Intente iniciar el servicio mediante la ejecución del siguiente comando:
systemctl start rke2-server - Una vez que el servidor rke2 esté activo en todos los MVM, asegúrese de que todos los nodos estén en un estado listo:
kubectl get nodes - Una vez que los nodos estén listos, vaya al paso siguiente. Si aparece un mensaje de error, espere unos minutos y vuelva a intentarlo.
- Restaure la base de datos del operador de monitoreo de clústeres (CMO):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Verifique la base de datos de CMO:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Restaure la base de datos del operador de monitoreo de clústeres (CMO):
- Monitoree el estado de la plataforma de administración de PowerFlex:
- Ejecute el siguiente comando para identificar el número de puerto de la utilidad del monitor de la plataforma de administración de PowerFlex:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Espere entre 20 y 30 minutos y compruebe el estado general de la plataforma de administración de PowerFlex.
- Ejecute el siguiente comando para identificar el número de puerto de la utilidad del monitor de la plataforma de administración de PowerFlex:
- Vaya a http://< node IP>:p ort/, donde la dirección IP del nodo es una dirección IP de administración configurada en cualquiera de los MVM (no la dirección IP de Ingress o PowerFlex Manager).
- Haga clic en Estado de PFMP y espere a que todas las entradas se vuelvan verdes.
- Ahora se podrá acceder a la interfaz de usuario principal de PFMP (a veces puede esperar de 20 a 30 minutos).
Versiones afectadas
PFMP 4.6.1
Problema corregido en la versión
PFMP 4.8