Plusieurs pods PowerFlex 4.6 redémarrent sans cesse
Summary: Plusieurs pods redémarrent en permanence pendant et après un nouveau déploiement ou une mise à niveau du groupe de ressources (RG) Storage Only (SO) et Compute Only (CO) ou vers la version 4.6.1. ...
Symptoms
Nouveau déploiement de PowerFlex Manager 4.6.1 ou mise à niveau vers la version 4.6.1 avec + de 200 nœuds de nœuds
SO et COLa vue de l’écran lors du redémarrage indique un manque de mémoire : 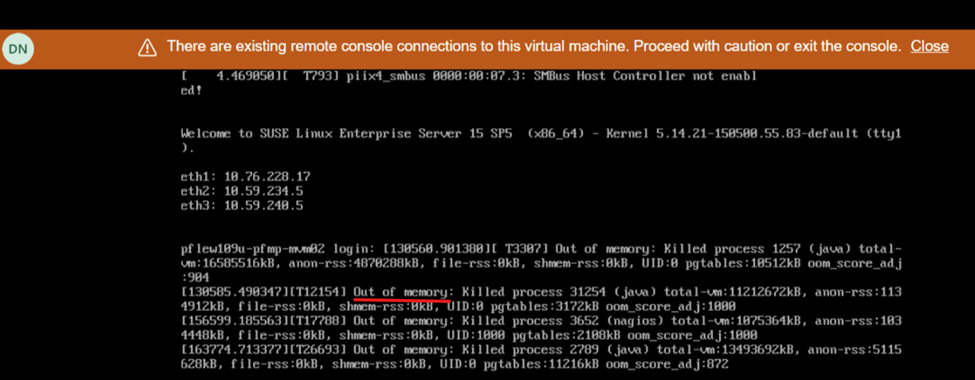
Impact
- État d’intégrité du système instable et interface utilisateur ne répond plus/n’est pas disponible
Cause
En raison d’un problème logiciel dans les versions 4.6.1 et ultérieures de la plate-forme PowerFlex Manager (PFMP), les systèmes comportant plus de 200 nœuds (SO et CO) nécessitent plus de ressources informatiques que ce qui avait été annoncé précédemment : 28 cœurs de processeur et 64 Go de mémoire.
Resolution
Procédure de mise hors tension
- Connectez-vous à un MVM et exécutez les commandes suivantes pour arrêter la base de données :
- Validez l’état d’intégrité de la base de données :
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Vérifiez que la base de données est arrêtée :
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Validez l’état d’intégrité de la base de données :
- Mettre le MVM hors tension
Mettre à jour les ressources MVM
Pour les nouveaux déploiements ou les mises à niveau vers 4.6.1, les nœuds MVM doivent répondre aux exigences supplémentaires en matière de mémoire et de processeur :
- Processeur : 28 cœurs
- Mémoire : 64 Go
Procédure de mise sous tension
- Mettez tous les MVM sous tension
- Sur chaque MVM, exécutez la commande suivante pour vérifier l’état du service rke2-server :
kubectl get nodesProcédez comme suit en fonction de l’état du serveur rke2 :État du serveur rke2
Procédez comme suit
Actif
Passez à l’étape suivante
Activation
Répétez la commande pour vérifier l’état de rke2-server jusqu’à ce qu’il soit actif.
Échec
Essayez de démarrer le service en exécutant la commande suivante :
systemctl start rke2-server - Une fois que le serveur rke2 est actif sur tous les MVM, assurez-vous que tous les nœuds sont à l’état prêt :
kubectl get nodes - Une fois les nœuds prêts, passez à l’étape suivante. Si un message d’erreur s’affiche, patientez quelques minutes et réessayez.
- Restaurez la base de données de l’opérateur de surveillance de cluster (CMO) :
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Vérifiez la base de données CMO :
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Restaurez la base de données de l’opérateur de surveillance de cluster (CMO) :
- Surveillez l’état de la plate-forme de gestion PowerFlex :
- Exécutez la commande suivante pour identifier le numéro de port de l’utilitaire de surveillance de la plate-forme de gestion PowerFlex :
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Patientez 20 à 30 minutes et vérifiez l’état d’intégrité général de la plate-forme de gestion PowerFlex.
- Exécutez la commande suivante pour identifier le numéro de port de l’utilitaire de surveillance de la plate-forme de gestion PowerFlex :
- Accédez à http://< node IP>:p ort/, où l’adresse IP du nœud est une adresse IP de gestion configurée sur l’un des MVM (et non l’adresse IP Ingress ou PowerFlex Manager).
- Cliquez sur l’état PFMP et attendez que toutes les entrées deviennent vertes.
- L’interface utilisateur principale de PFMP sera désormais accessible (cela peut parfois attendre de 20 à 30 minutes).
Versions affectées
PFMP 4.6.1
Problème résolu dans la version
PFMP 4.8