PowerFlex 4.6: più pod continuano a riavviarsi
Summary: Più pod continuano a riavviarsi durante e dopo un nuovo deployment di un gruppo di risorse Storage Only (SO) e Compute Only (CO) o l'aggiornamento alla versione 4.6.1.
Symptoms
Nuovo deployment di PowerFlex Manager 4.6.1 o upgrade alla versione 4.6.1 con 200+ nodi SO e CO
La schermata visualizzata durante il riavvio mostra una mancanza di memoria: 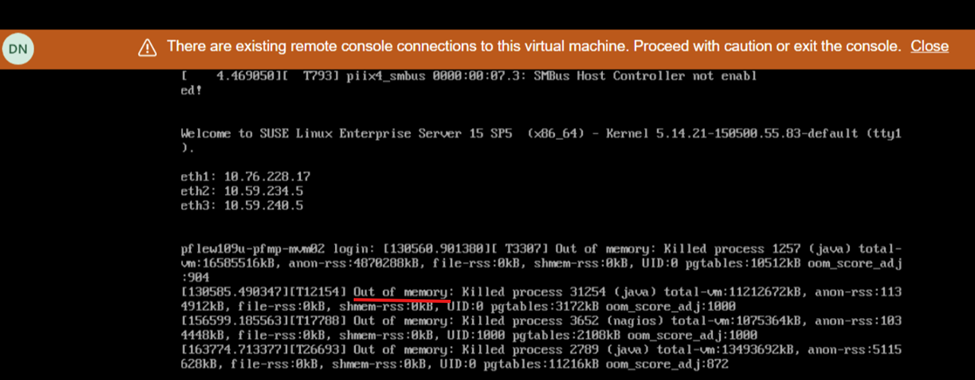
Impatto
- Stato di integrità del sistema instabile e l'interfaccia utente smette di rispondere/non disponibile
Cause
A causa di un problema software nella piattaforma PowerFlex Manager (PFMP) versioni 4.6.1 e successive, i sistemi con oltre 200 nodi (sia SO che CO) richiedono più risorse di elaborazione rispetto a quanto precedentemente pubblicizzato: 28 core CPU e 64 GB di memoria.
Resolution
Procedura di spegnimento
- Accedere a un MVM ed eseguire i seguenti comandi per arrestare il database:
- Convalidare lo stato di integrità del database:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Verificare che il database sia stato arrestato:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Convalidare lo stato di integrità del database:
- Spegnimento dell'MVM
Aggiornamento delle risorse MVM
Per le nuove implementazioni o gli aggiornamenti alla versione 4.6.1, i nodi MVM devono soddisfare i requisiti aggiuntivi di memoria e CPU:
- CPU - 28 core
- Memoria: 64 GB
Procedura di accensione
- Accendere tutte le MVM
- Su ogni MVM, eseguire il seguente comando per verificare lo stato del servizio rke2-server:
kubectl get nodesEffettuare le seguenti operazioni a seconda dello stato del server rke2:Stato del server rke2
Procedere come segue:
Attivo
Andare al passaggio successivo
Attivatore
Ripetere il comando per controllare lo stato di rke2-server fino a quando non è attivo.
Failed
Tentare di avviare il servizio eseguendo il seguente comando:
systemctl start rke2-server - Una volta che il server rke2 è attivo su tutti gli MVM, assicurarsi che tutti i nodi siano in uno stato pronto:
kubectl get nodes - Una volta che i nodi sono pronti, andare al passaggio successivo. Se viene visualizzato un messaggio di errore, attendere alcuni minuti e riprovare.
- Ripristinare il database CMO (Cluster Monitoring Operator):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Verificare il database CMO:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Ripristinare il database CMO (Cluster Monitoring Operator):
- Monitorare lo stato della piattaforma di gestione PowerFlex:
- Eseguire il comando seguente per identificare il numero di porta per l'utilità di monitoraggio della piattaforma di gestione PowerFlex:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Attendere 20-30 minuti e controllare lo stato di integrità generale della piattaforma di gestione PowerFlex.
- Eseguire il comando seguente per identificare il numero di porta per l'utilità di monitoraggio della piattaforma di gestione PowerFlex:
- Passare a http://< node IP>:p ort/, dove l'indirizzo IP del nodo è un indirizzo IP di gestione configurato su uno qualsiasi degli MVM (non l'indirizzo IP di Ingress o PowerFlex Manager).
- Cliccare sullo stato PFMP e attendere che tutte le voci diventino verdi.
- L'interfaccia utente principale di PFMP sarà ora accessibile (a volte potrebbe attendere da 20 a 30 minuti).
Versioni interessate
PFMP 4.6.1
Risolto nella versione
PFMP 4.8