PowerFlex 4.6で複数のポッドが再起動し続ける
Summary: ストレージ専用(SO)およびコンピューティング専用(CO)リソース グループ(RG)での4.6.1への新規導入中または4.6.1へのアップグレード中および実行後に、複数のポッドが再起動し続けます。
Acest articol se aplică pentru
Acest articol nu se aplică pentru
Acest articol nu este legat de un produs specific.
Acest articol nu acoperă toate versiunile de produs existente.
Symptoms
PowerFlex Manager 4.6.1の新規導入、またはSOおよびCOノードの200+ノードを使用した4.6.1へのアップグレード
再起動中の画面ビューにメモリー不足が表示される: 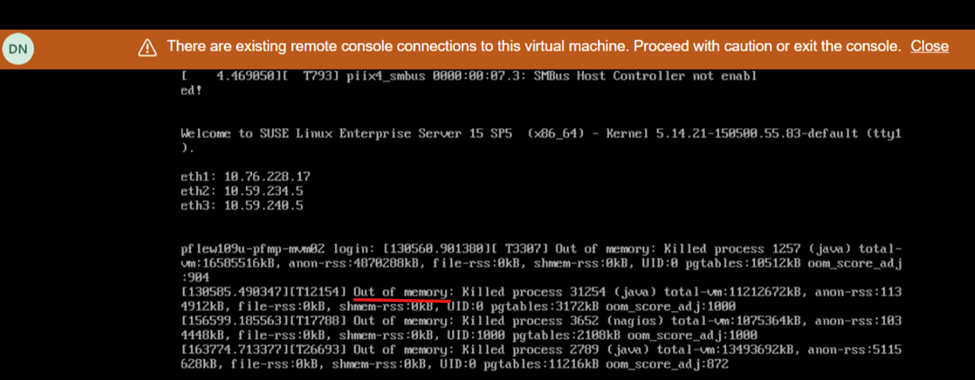
問題
- システムの正常性状態が不安定になり、UIが応答を停止する/使用できない
Cause
PowerFlex Managerプラットフォーム(PFMP)バージョン4.6.1以降のソフトウェアの問題により、200を超えるノード(SOとCOの両方)を持つシステムには、以前に通知されたよりも多くのコンピューティング リソースが必要です。28個のCPUコアと64 GBのメモリー。
Resolution
電源オフ手順
- MVMにログインし、次のコマンドを実行してデータベースを停止します。
- データベースの稼働状態を検証します。
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - データベースがシャットダウンされていることを確認します。
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- データベースの稼働状態を検証します。
- MVMの電源を切ります
MVMリソースのアップデート
新規導入または4.6.1へのアップグレードの場合、MVMノードは追加のメモリーとCPUの要件を満たす必要があります。
- CPU - 28コア
- メモリー - 64 GB
リソースの追加手順の詳細については、ベンダーにお問い合わせください。
電源投入手順
- すべてのMVMの電源をオンにします
- 各MVMで、次のコマンドを実行してrke2-serverサービスのステータスを確認します。
kubectl get nodesrke2-serverのステータスに応じて、次の手順を実行します。rke2-serverのステータス
次の手順を実行
アクティブ
次の手順に進む
アクティブ 化
コマンドを繰り返して、アクティブになるまでrke2-serverのステータスを確認します。
失敗
次のコマンドを実行して、サービスの開始を試みます。
systemctl start rke2-server - すべてのMVMでrke2-serverがアクティブになったら、すべてのノードが準備完了状態であることを確認します。
kubectl get nodes - ノードの準備ができたら、次の手順に進みます。エラー メッセージが表示された場合は、数分待ってから再試行してください。
- クラスター監視オペレーター(CMO)データベースをリストアします。
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - CMOデータベースを確認します。
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- クラスター監視オペレーター(CMO)データベースをリストアします。
- PowerFlex管理プラットフォームのステータスを監視します。
- 次のコマンドを実行して、PowerFlex管理プラットフォーム監視ユーティリティーのポート番号を特定します。
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - 20分から30分待ってから、PowerFlex管理プラットフォームの全体的な正常性ステータスを確認します。
- 次のコマンドを実行して、PowerFlex管理プラットフォーム監視ユーティリティーのポート番号を特定します。
- http://<node IP>:p ort/に移動します。ここで、ノードIPアドレスは、いずれかのMVMで構成されている管理IPアドレスです(IngressまたはPowerFlex ManagerのIPアドレスではありません)。
- [PFMP status]をクリックし、すべてのエントリーが緑色に変わるまで待ちます。
- これで、PFMPメインUIにアクセスできるようになります(20分から30分待つ場合があります)。
問題が発生するバージョン
PFMPの4.6.1
修正バージョン
PFMPの4.8
Produse afectate
PowerFlex appliance R650, Powerflex appliance R750Produse
PowerFlex rack, PowerFlex appliance connectivity, PowerFlex appliance R760, PowerFlex custom nodeProprietăți articol
Article Number: 000321671
Article Type: Solution
Ultima modificare: 31 Jul 2025
Version: 5
Găsiți răspunsuri la întrebările dvs. de la alți utilizatori Dell
Servicii de asistență
Verificați dacă dispozitivul dvs. este acoperit de serviciile de asistență.