PowerFlex 4.6 Meerdere pods worden steeds opnieuw opgestart
Summary: Meerdere pods worden steeds opnieuw opgestart tijdens en na een nieuwe implementatie van of upgrade naar 4.6.1 door alleen Storage Only (SO) en Compute Only (CO) Resource Group (RG).
Symptoms
Nieuwe implementatie van PowerFlex Manager 4.6.1 of upgraden naar 4.6.1 met 200+ SO- en CO-knooppunten
De schermweergave tijdens het opnieuw opstarten toont een gebrek aan geheugen: 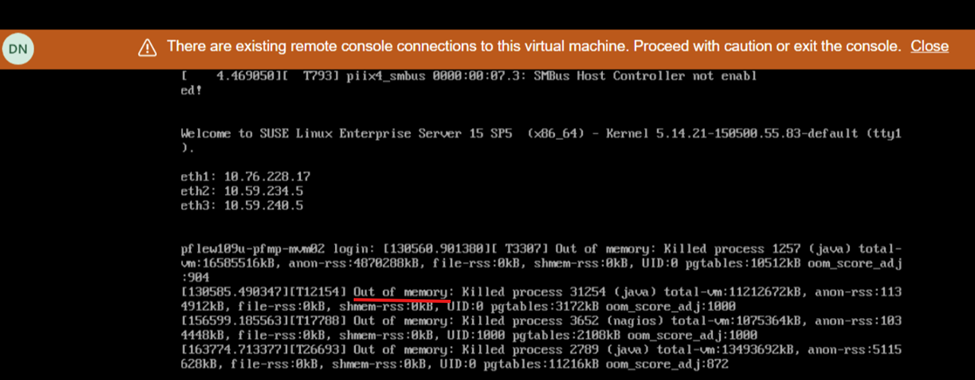
Impact
- Onstabiele systeemstatus en gebruikersinterface reageert niet meer/is niet beschikbaar
Cause
Als gevolg van een softwareprobleem in PowerFlex Manager Platform (PFMP) versie 4.6.1 en hoger hebben systemen met meer dan 200 knooppunten (zowel SO als CO) meer rekenresources nodig dan eerder geadverteerd: 28 CPU-cores en 64 GB geheugen.
Resolution
Uitschakelingsprocedure
- Meld u aan bij een MVM en voer de volgende opdrachten uit om de database te stoppen:
- Valideer de status van de database:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Bevestig dat de database is afgesloten:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Valideer de status van de database:
- Schakel de MVM uit
MVM-resources bijwerken
Voor nieuwe implementaties of upgrades naar 4.6.1 moeten de MVM-knooppunten voldoen aan de extra geheugen- en CPU-vereisten:
- CPU - 28 cores
- Geheugen - 64 GB
Opstartprocedure
- Schakel alle MVM's in
- Voer op elke MVM de volgende opdracht uit om de status van de rke2-server-service te controleren:
kubectl get nodesDoe het volgende, afhankelijk van de status van de rke2-server:Status van de rke2-server
Ga als volgt te werk
Actief
Ga naar de volgende stap
Activeren
Herhaal de opdracht om de rke2-serverstatus te controleren totdat deze actief is.
Failed
Probeer de service te starten door de volgende opdracht uit te voeren:
systemctl start rke2-server - Zodra de rke2-server actief is op alle MVM's, moet u ervoor zorgen dat alle knooppunten gereed zijn:
kubectl get nodes - Zodra de knooppunten gereed zijn, gaat u verder met de volgende stap. Als er een foutmelding wordt weergegeven, wacht u enkele minuten en probeert u het opnieuw.
- Herstel de CMO-database (Cluster Monitoring Operator):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Controleer de CMO-database:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Herstel de CMO-database (Cluster Monitoring Operator):
- De status van het PowerFlex-beheerplatform controleren:
- Voer de volgende opdracht uit om het poortnummer te identificeren voor het PowerFlex-beheerplatformmonitorhulpprogramma:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Wacht 20-30 minuten en controleer de algehele status van het PowerFlex-beheerplatform.
- Voer de volgende opdracht uit om het poortnummer te identificeren voor het PowerFlex-beheerplatformmonitorhulpprogramma:
- Ga naar http://< knooppunt-IP>:p ort/, waarbij het knooppunt-IP-adres een beheer-IP-adres is dat is geconfigureerd op een van de MVM's (niet het IP-adres van Ingress of PowerFlex Manager).
- Klik op PFMP-status en wacht tot alle vermeldingen groen worden.
- De hoofdgebruikersinterface van PFMP is nu toegankelijk (soms kan het 20 tot 30 minuten duren).
Versies waarop dit van toepassing is
PFMP 4.6.1
Opgelost in versie
PFMP 4.8