PowerFlex 4.6 Flere pods fortsetter å starte på nytt
Summary: Flere pods starter på nytt under og etter en ny distribusjon av Storage Only (SO) og Compute Only (CO) Resource Group (RG) eller oppgradering til 4.6.1.
Symptoms
Ny implementering av PowerFlex Manager 4.6.1 eller oppgradering til 4.6.1 med 200+ noder med SO- og CO-noder
Skjermvisning under omstart viser mangel på minne: 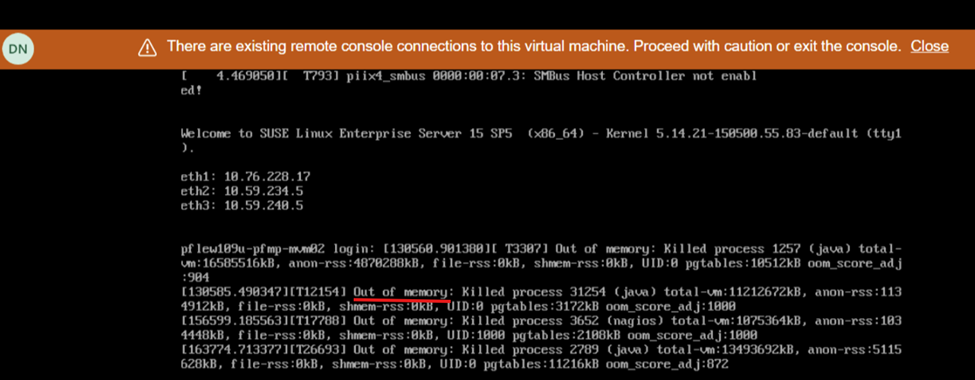
Innvirkning
- Ustabil systemtilstand, og brukergrensesnittet slutter å svare/ikke tilgjengelig
Cause
På grunn av et programvareproblem i PowerFlex Manager Platform (PFMP) versjon 4.6.1 og nyere, krever systemer med over 200 noder (både SO og CO) flere databehandlingsressurser enn tidligere annonsert: 28 CPU-kjerner og 64 GB minne.
Resolution
Prosedyre for avstenging
- Logg på en MVM, og kjør følgende kommandoer for å stoppe databasen:
- Valider tilstandstilstand for database:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Kontroller at databasen er lukket:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Valider tilstandstilstand for database:
- Slå av MVM
Oppdatere MVM-ressurser
For nye distribusjoner eller oppgraderinger til 4.6.1 må MVM-nodene oppfylle kravene til ekstra minne og CPU:
- CPU – 28 kjerner
- Minne – 64 GB
Fremgangsmåte for å slå på
- Slå på alle MVM-er
- På hver MVM kjører du følgende kommando for å kontrollere statusen til rke2-servertjenesten:
kubectl get nodesUtfør følgende, avhengig av rke2-serverstatus:Status for rke2-tjener
Gjør følgende
Aktiv
Gå til neste trinn
Aktivere
Gjenta kommandoen for å kontrollere status for rke2-server til den er aktiv.
Failed
Prøv å starte tjenesten ved å kjøre følgende kommando:
systemctl start rke2-server - Når rke2-serveren er aktiv på alle MVM-ene, må du sørge for at alle nodene er i en klar tilstand:
kubectl get nodes - Når nodene er klare, går du videre til neste trinn. Hvis det vises en feilmelding, venter du noen minutter og prøver på nytt.
- Gjenopprette databasen for Cluster Monitoring Operator (CMO):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Kontrollere CMO-databasen:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Gjenopprette databasen for Cluster Monitoring Operator (CMO):
- Overvåk statusen for PowerFlex-administrasjonsplattformen:
- Kjør følgende kommando for å identifisere portnummeret til PowerFlex Management Platform Monitor-verktøyet:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Vent i 20–30 minutter, og kontroller den generelle tilstandsstatusen til administrasjonsplattformen for PowerFlex.
- Kjør følgende kommando for å identifisere portnummeret til PowerFlex Management Platform Monitor-verktøyet:
- Gå til http://< node IP>:p ort/, der node-IP-adressen er en administrasjons-IP-adresse som er konfigurert på en av MVM-ene (ikke Ingress- eller PowerFlex Manager-IP-adressen).
- Klikk på PFMP-status og vent til alle oppføringene blir grønne.
- PFMP-hovedgrensesnittet vil nå være tilgjengelig (noen ganger kan det vente i 20 til 30 minutter).
Berørte versjoner
PFMP 4.6.1
Løst i versjon
PFMP 4.8