PowerFlex 4.6 Wiele kapsuł uruchamia się ponownie
Summary: Wiele zasobników jest uruchamianych ponownie w trakcie i po nowym wdrożeniu lub uaktualnieniu do wersji 4.6.1 w grupie zasobów tylko magazyn (SO) i tylko zasoby obliczeniowe (CO).
Symptoms
Nowe wdrożenie PowerFlex Manager 4.6.1 lub aktualizacja do wersji 4.6.1 z 200+ węzłami węzłów SO i CO
Widok ekranu podczas ponownego uruchamiania pokazuje brak pamięci: 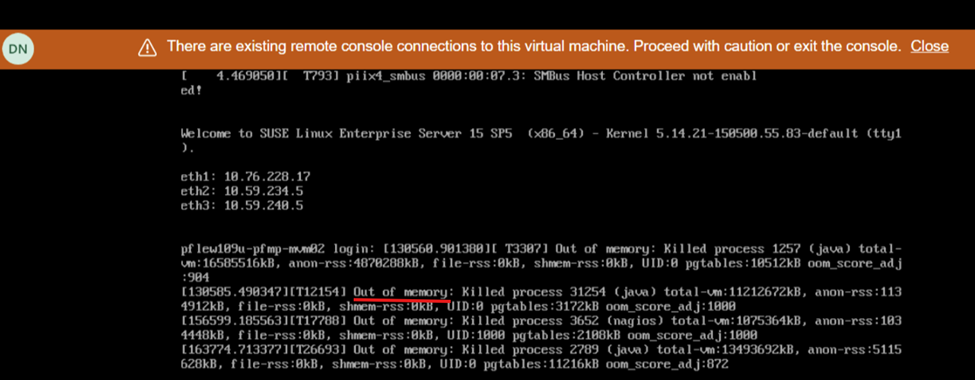
Wpływ
- Niestabilny stan kondycji systemu i interfejs użytkownika przestaje reagować/jest niedostępny
Cause
Ze względu na problem z oprogramowaniem platformy PowerFlex Manager Platform (PFMP) w wersji 4.6.1 i nowszych systemy z ponad 200 węzłami (zarówno SO, jak i CO) wymagają więcej zasobów obliczeniowych niż wcześniej reklamowano: 28 rdzeni procesora i 64 GB pamięci.
Resolution
Procedura wyłączania
- Zaloguj się do MVM i uruchom następujące polecenia, aby zatrzymać bazę danych:
- Weryfikacja kondycji bazy danych:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Sprawdź, czy baza danych została zamknięta za pomocą polecenia:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Weryfikacja kondycji bazy danych:
- Wyłącz MVM
Aktualizacja zasobów MVM
W przypadku nowych wdrożeń lub uaktualnień do wersji 4.6.1 węzły MVM musiałyby spełniać dodatkowe wymagania dotyczące pamięci i procesora CPU:
- Procesor — 28 rdzeni
- Pamięć — 64 GB
Procedura włączania zasilania
- Włącz wszystkie MVM
- W każdym MVM uruchom następujące polecenie, aby sprawdzić stan usługi rke2-server:
kubectl get nodesWykonaj następujące czynności w zależności od stanu serwera rke2:Stan serwera rke2
Wykonaj następujące czynności
Active
Przejdź do następnego kroku
Aktywowanie
Powtórz polecenie, aby sprawdzić stan serwera rke2 do momentu uaktywnienia.
Failed (Awaria)
Spróbuj uruchomić usługę, uruchamiając następujące polecenie:
systemctl start rke2-server - Gdy serwer rke2 jest aktywny na wszystkich MVM, upewnij się, że wszystkie węzły są w stanie gotowości:
kubectl get nodes - Gdy węzły będą gotowe, przejdź do następnego kroku. Jeśli pojawi się komunikat o błędzie, odczekaj kilka minut i spróbuj ponownie.
- Przywróć bazę danych operatorów monitorowania klastra (CMO):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Sprawdź bazę danych CMO:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Przywróć bazę danych operatorów monitorowania klastra (CMO):
- Monitorowanie stanu platformy zarządzania PowerFlex:
- Uruchom następujące polecenie, aby zidentyfikować numer portu narzędzia do monitorowania platformy zarządzania PowerFlex:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Odczekaj 20–30 minut i sprawdź ogólny stan platformy zarządzania PowerFlex.
- Uruchom następujące polecenie, aby zidentyfikować numer portu narzędzia do monitorowania platformy zarządzania PowerFlex:
- Przejdź do opcji http://< node IP>:p ort/, gdzie adres IP węzła to adres IP zarządzania skonfigurowany w dowolnym MVM (nie jest to adres IP Ingress lub PowerFlex Manager).
- Kliknij status PFMP i poczekaj, aż wszystkie wpisy zmienią kolor na zielony.
- Główny interfejs użytkownika PFMP będzie teraz dostępny (czasami może to potrwać od 20 do 30 minut).
Wersje, których dotyczy problem
PFMP 4.6.1
Naprawiono w wersji
PFMP 4.8