PowerFlex 4.6 Vários pods continuam reiniciando
Summary: Vários pods continuam reiniciando durante e após uma nova implementação ou upgrade do grupo de recursos (CO) apenas de armazenamento (SO) e apenas de computação (CO) do 4.6.1.
Symptoms
Nova implementação do PowerFlex Manager 4.6.1 ou upgrade para a versão 4.6.1 com + de 200 nós de SO
e COA exibição da tela durante a reinicialização mostra falta de memória: 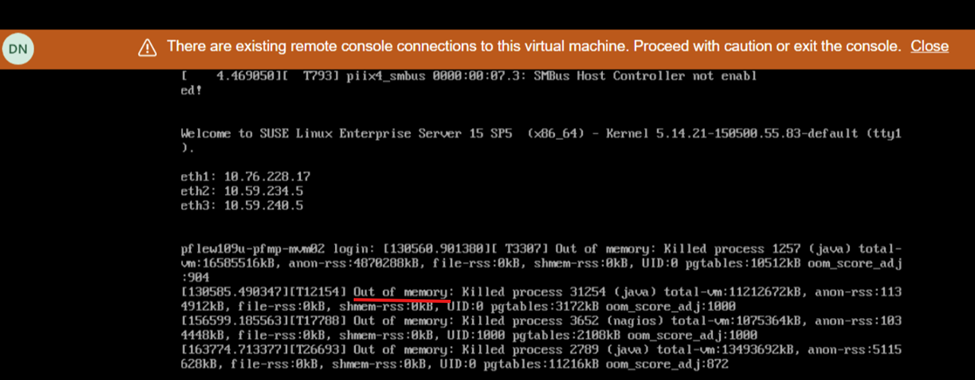
Impacto
- Estado de integridade do sistema instável e interface do usuário parando de responder/não disponível
Cause
Devido a um problema de software na Plataforma PowerFlex Manager (PFMP) versões 4.6.1 e posteriores, os sistemas com mais de 200 nós (SO e CO) exigem mais recursos de computação do que o anunciado anteriormente: 28 núcleos de CPU e 64 GB de memória.
Resolution
Procedimento de desligamento
- Faça log-in em um MVM e execute os seguintes comandos para interromper o banco de dados:
- Valide o estado de integridade do banco de dados:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Valide se o banco de dados está desligado:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Valide o estado de integridade do banco de dados:
- Desligar o MVM
Atualizar recursos do MVM
Para novas implementações ou upgrades para a versão 4.6.1, os nós MVM teriam que atender aos requisitos adicionais de memória e CPU:
- CPU - 28 núcleos
- Memória: 64 GB
Procedimento de inicialização
- Ligue todos os MVMs
- Em cada MVM, execute o seguinte comando para verificar o status do serviço rke2-server:
kubectl get nodesFaça o seguinte, dependendo do status do servidor rke2:Status do servidor rke2
Siga estas etapas
Ativa
Vá para a próxima etapa
Ativar
Repita o comando para verificar o status do servidor rke2 até que esteja ativo.
Failed
Tente iniciar o serviço executando o seguinte comando:
systemctl start rke2-server - Depois que o rke2-server estiver ativo em todos os MVMs, certifique-se de que todos os nós estejam em um estado pronto:
kubectl get nodes - Quando os nós estiverem prontos, vá para a próxima etapa. Se uma mensagem de erro for exibida, aguarde alguns minutos e tente novamente.
- Restaure o banco de dados do operador de monitoramento de cluster (CMO):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Verifique o banco de dados do CMO:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Restaure o banco de dados do operador de monitoramento de cluster (CMO):
- Monitore o status da plataforma de gerenciamento do PowerFlex:
- Execute o seguinte comando para identificar o número da porta do utilitário de monitor da plataforma de gerenciamento do PowerFlex:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Aguarde de 20 a 30 minutos e verifique o status geral de integridade da plataforma de gerenciamento do PowerFlex.
- Execute o seguinte comando para identificar o número da porta do utilitário de monitor da plataforma de gerenciamento do PowerFlex:
- Vá para http://< node IP>:p ort/, em que o endereço IP do nó é um endereço IP de gerenciamento configurado em qualquer um dos MVMs (não o endereço IP de entrada ou do PowerFlex Manager).
- Clique no status da PFMP e aguarde até que todas as entradas fiquem verdes.
- A interface do usuário principal da PFMP agora estará acessível (às vezes, pode esperar de 20 a 30 minutos).
Versões afetadas
PFMP 4.6.1
Correção feita na versão
PFMP 4,8