PowerFlex 4.6 Flera poddar startar om hela tiden
Summary: Flera poddar fortsätter att startas om under och efter en ny distribution av eller uppgradering till 4.6.1 (Endast lagring) och endast beräkning (CO)
Symptoms
Ny distribution av PowerFlex Manager 4.6.1 eller uppgradering till 4.6.1 med 200+ noder med SO- och CO-noder
Skärmvy under omstart visar brist på minne: 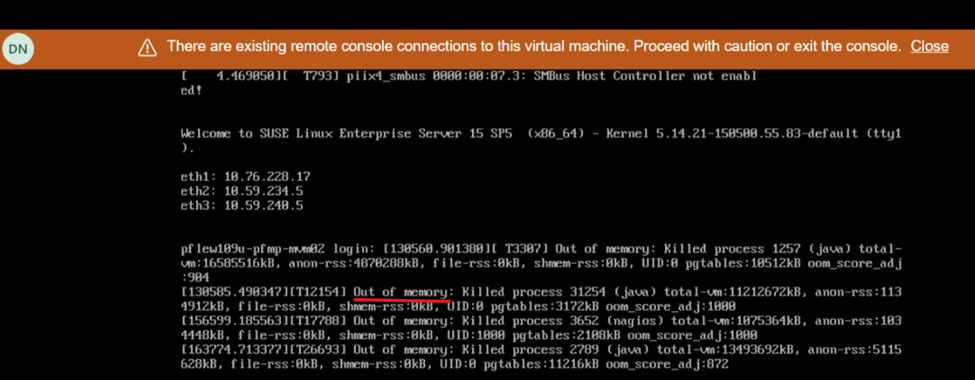
Påverkan
- Instabilt systemhälsotillstånd och användargränssnittet slutar svara/är inte tillgängligt
Cause
På grund av ett mjukvaruproblem i PowerFlex Manager Platform (PFMP) version 4.6.1 och senare kräver system med över 200 noder (både SO och CO) mer datorresurser än vad som tidigare annonserats: 28 processorkärnor och 64 GB minne.
Resolution
Avstängningsprocedur
- Logga in på en MVM och kör följande kommandon för att stoppa databasen:
- Verifiera databasens hälsotillstånd:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - Verifiera att databasen är avstängd:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Verifiera databasens hälsotillstånd:
- Stäng av MVM
Uppdatera MVM-resurser
För nya distributioner eller uppgraderingar till 4.6.1 måste MVM-noderna uppfylla de ytterligare minnes- och CPU-kraven:
- CPU – 28 kärnor
- Minne – 64 GB
Procedur för påslagning
- Slå på alla MVM:er
- Kör följande kommando på varje MVM för att kontrollera status för rke2-servertjänsten:
kubectl get nodesGör följande beroende på rke2-serverns status:Status för rke2-servern
Gör så här
Aktiv
Gå till nästa steg
Aktivera
Upprepa kommandot för att kontrollera rke2-serverstatus tills det är aktivt.
Failed
Försök att starta tjänsten genom att köra följande kommando:
systemctl start rke2-server - När rke2-servern är aktiv på alla MVM:er kontrollerar du att alla noder är redo:
kubectl get nodes - Gå till nästa steg när noderna är klara. Om ett felmeddelande visas väntar du några minuter och försöker igen.
- Återställa databasen för klusterövervakningsoperatör (CMO):
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - Verifiera CMO-databasen:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- Återställa databasen för klusterövervakningsoperatör (CMO):
- Övervaka status för PowerFlex-hanteringsplattformen:
- Kör följande kommando för att identifiera portnumret för PowerFlex Management Platform-bildskärmsverktyget:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - Vänta 20–30 minuter och kontrollera PowerFlex-hanteringsplattformens allmänna hälsostatus.
- Kör följande kommando för att identifiera portnumret för PowerFlex Management Platform-bildskärmsverktyget:
- Gå till http://< nod-IP>:p ort/, där nodens IP-adress är en IP-adress för hantering som är konfigurerad på någon av MVM:erna (inte IP-adressen för Ingress eller PowerFlex Manager).
- Klicka på PFMP-status och vänta tills alla poster blir gröna.
- PFMP:s huvudgränssnitt är nu tillgängligt (kan ibland vänta i 20 till 30 minuter).
Versioner som påverkas
PFMP 4.6.1
Åtgärdat i version
PFMP 4.8