PowerFlex 4.6 多個 Pod 不斷重新開機
Summary: 在僅儲存 (SO) 和僅運算 (CO) 資源群組 (RG) 新部署或升級到 4.6.1 期間和之後,多個 Pod 會不斷重新開機。
Acest articol se aplică pentru
Acest articol nu se aplică pentru
Acest articol nu este legat de un produs specific.
Acest articol nu acoperă toate versiunile de produs existente.
Symptoms
新部署 PowerFlex Manager 4.6.1 或升級至 4.6.1,搭載 200+ 個 SO 和 CO 節點
節點重新開機期間的螢幕檢視顯示缺少記憶體: 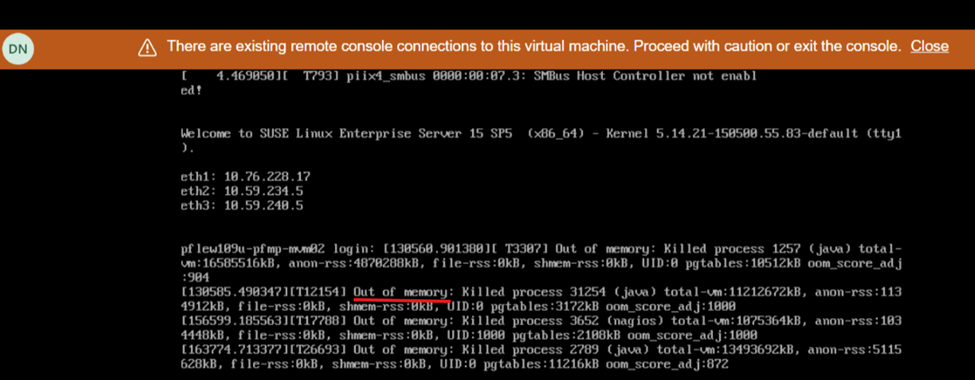
影響
- 系統健全狀況狀態不穩定,且 UI 停止回應/無法使用
Cause
由於 PowerFlex Manager 平台 (PFMP) 版本 4.6.1 及更高版本中的軟體問題,超過 200 個節點 (SO 和 CO) 的系統需要比先前宣傳的更多的運算資源:配備 28 個 CPU 核心和 64 GB 記憶體。
Resolution
關閉電源程序
- 登入 MVM 並執行下列命令以停止資料庫:
- 驗證資料庫執行狀況狀態:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown":true}}' - 驗證資料庫是否已關閉:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- 驗證資料庫執行狀況狀態:
- 關閉 MVM 電源
更新 MVM 資源
進行新部署或升級至 4.6.1 時,MVM 節點必須滿足額外的記憶體和 CPU 需求:
- CPU - 28 核心
- 記憶體 - 64 GB
有關添加資源的完整過程,請與供應商聯繫。
開啟電源程序
- 開啟所有 MVM 的電源
- 在每個 MVM 上,執行下列命令以檢查 rke2 伺服器服務的狀態:
kubectl get nodes根據 rke2 伺服器狀態執行以下操作:rke2 伺服器的狀態
請執行下列操作
使用中
前往下一個步驟
正在啟動
重複命令以檢查 rke2-server 狀態,直到作用中為止。
失敗
嘗試透過執行以下命令來啟動服務:
systemctl start rke2-server - 一旦 rke2-server 在所有 MVM 上處於活動狀態,請確保所有節點都處於就緒狀態:
kubectl get nodes - 節點準備就緒後,請前往下一個步驟。如果出現錯誤訊息,請等待幾分鐘後再重試。
- 還原叢集監控操作員 (CMO) 資料庫:
kubectl config set-context default --namespace=$(kubectl get pods -A | grep -m 1 -E 'platform|pgo|helmrepo|docker' | cut -d' ' -f1) kubectl -n powerflex patch $(kubectl -n powerflex get postgrescluster -o name) --type merge --patch '{"spec":{"shutdown": false}}' - 驗證 CMO 資料庫:
echo $(kubectl get pods -l="postgres-operator.crunchydata.com/control-plane=pgo" --no-headers -o name && kubectl get pods -l="postgres-operator.crunchydata.com/instance" --no-headers -o name) | xargs kubectl get -o wide
- 還原叢集監控操作員 (CMO) 資料庫:
- 監控 PowerFlex 管理平台狀態:
- 執行下列命令,以識別 PowerFlex 管理平台顯示器公用程式的連接埠號碼:
kubectl get services monitor-app -n powerflex -o jsonpath="{.spec.ports[0].nodePort}{\"\n\"}" - 等待 20-30 分鐘,然後檢查 PowerFlex 管理平台的整體健全狀況。
- 執行下列命令,以識別 PowerFlex 管理平台顯示器公用程式的連接埠號碼:
- 前往 http://< node IP>:p ort/,其中節點 IP 位址是任何 MVM 上設定的管理 IP 位址 (不是入口或 PowerFlex Manager IP 位址)。
- 按一下 PFMP 狀態,並等待所有項目變為綠色。
- 現在可存取 PFMP 主 UI (有時可能需要等待 20 至 30 分鐘)。
受影響的版本
PFMP 4.6.1
已修正問題的版本
PFMP 4.8
Produse afectate
PowerFlex appliance R650, Powerflex appliance R750Produse
PowerFlex rack, PowerFlex appliance connectivity, PowerFlex appliance R760, PowerFlex custom nodeProprietăți articol
Article Number: 000321671
Article Type: Solution
Ultima modificare: 31 Jul 2025
Version: 5
Găsiți răspunsuri la întrebările dvs. de la alți utilizatori Dell
Servicii de asistență
Verificați dacă dispozitivul dvs. este acoperit de serviciile de asistență.