

未解決
2 Intern
•
38 メッセージ
•
2 ポイント
0
95
2026年4月30日 04:51
DataPlatformTech 第37回 Dell Data Orchestration Engineリリース
ゴールデンウィークな今日この頃、皆様いかがお過ごしでしょうか?
先日のNVIDIA GTC 2026ではDell AI Data Platform関連の発表が多くありました。cuDF/cuVS、Lightning File System(並列ファイルシステム)、Exascale Storage、CMX、PowerScale pNFSなど多くは高性能かつ大規模用途向けですが、今回ご紹介するDell Data Orchestration Engineは規模の大小は関係しないAIライフサイクル向けのオーケストレーションエンジンです。
AIは従来のダッシュボードを作って利用する時代から、エージェントが自律的に判断し行動する時代に移りつつあります。このとき、一番のボトルネックになるのはGPUやモデルではなく、品質が悪い状態でデータがサイロ化されていてAIが使える形になっていないことだと言えます。オンプレミス、パブリッククラウドなどに分散されたデータは扱うのが難しく、特に非構造データは放置されがちです。また、よくあるAIの悩みとして、PoCでは少量のデータを集めることで成功しても、本番運用では大量かつ変化を伴うデータを継続的に投入することができずAI導入を諦めてしまうというお話も聞くことが多いです。上手く本番運用に辿り着けた場合でも、利用しているうちにモデルがドリフトして精度が低下してしまうケースもあります。AIは1度構築したら終わりではなくモデルのライフサイクル全体(データ準備 → 学習 → デプロイ → 監視/改善)を継続的に回すための仕組み(MLOps/LLMOps)が重要です。

Dell Data Orchestration Engine自体は、昨年末にDell Technologiesが買収したDataloop をリブランドした製品です。先月末に装いも新たに(本ブログのスクリーンショットのようにUIをDell Technologiesブランドに変更して)再登場となりました。なお、Dell Data Orchestration Engineは2026年4月現在SaaS版のみの提供となっております。
Dell Data Orchestration Engine概要
Dell Data Orchestration Engineは、構造化/非構造化などマルチモーダルなデータを対象に、AIライフサイクル全体をオーケストレーションし、ガバナンスの効いたAI-Readyなデータセットを準備するデータエンジンです。元々のDataloopの名前の由来のとおり、データの取り込み、アノテーション、モデル作成/学習、評価、デプロイまでを一気通貫で継続的に自動化します。また、評価結果に基づいてモデルを改善し、モデルのバージョンを管理しつつ、より良いバージョンを選定して再デプロイまでをパイプラインとして自動化する流れでデータパイプラインを回すことが可能です。また、Dell AI Data Platformの観点では、PowerScaleやObjectScaleなどのストレージエンジンだけでなく、Dell Data Analytics Engine、Dell Data Processing Engine、Dell Data Search Engineといった各データエンジンや、パブリッククラウドを含む分散されたデータソースにまたがるパイプラインを統合的に制御するインテリジェントなコントロールレイヤと言えます。Dell Data Orchestration Engineでは、データパイプラインを準備するにあたり、Dell Data Orchestration Engine Marketplace上に用意されているコンポーネント(エージェント、モデル、パイプライン、データセットなど)が利用できますので、ゼロからパイプラインを開発する必要はありません。例えば類似のテンプレートや、内蔵の NVIDIA Hub から提供される NVIDIA NIMや NVIDIA AI Blueprints から必要なコンポーネントを選択して、GUIからワンクリックでパイプラインに組み込めるようになっています。もちろん独自の処理(カスタムノード)を追加したい場合は、SDK(Python、JavaScript)を使って組み込むことも可能です。

<Dell Data Orchestration Engine Marketplace>
データパイプラインのユースケース
データパイプラインのユースケースとして、今回はRAG(Retrieval-Augmented Generation)と、能動学習(Active Learning)の2つをご紹介します。
自組織のドキュメントを基に回答させるチャットボット(RAG)の場合、まずPDFや画像などのファイルをPowerScaleなどのデータソースから取り込みます。次にファイル内のテキストやグラフなどの画像を抽出し、レイアウトを検出します。そして必要に応じてOCRを実行後、チャンクに分割します。その後、ベクトル埋め込みを生成し、そのベクトルを Dell Data Search Engine(全文検索とベクトル検索の統合検索エンジン)に格納することで、RAGアプリケーションから検索可能にします。これによってRAGの回答精度と網羅性を高めることができ、データソース側の更新がそのまま検索結果に反映されるため、常に最新かつガバナンスの効いたチャットボットを維持できます。

<RAG Preprocessing Multimodal PDFsテンプレート>
能動学習は、ラベル付けが高コストで未ラベルデータが大量にある医療や自動運転などで使われる手法です。すべてのデータを人が手動でアノテーションするのではなく、モデルが不確実性の高いサンプルや新しいパターンを含むサンプル(例えば、レントゲン画像から悪性腫瘍か判断が難しい場合)を自動的に選び出し、その部分だけを人がレビューやアノテーションを行い、再学習を回す仕組みです。このとき付与されたアノテーションは、そのまま次の学習サイクル用データセットになります。Dell Data Orchestration Engineは、モデルの推論、評価と人によるアノテーション追加(Human-in-the-Loop(HITL))を同じパイプラインの中に組み込み、「モデルが提案 → 人が確認して修正 → データセットが更新される」という流れを自動的に回し続けられるようにします。
これにより、ドメインエキスパートはモデルが判断が難しいと判定したデータだけをレビューするため、限られた時間を本当に難しいケースのみに対応することができ、結果としてラベル付けコストを抑えつつ、高品質なラベル付きデータと高精度なモデルの両立が実現できます。
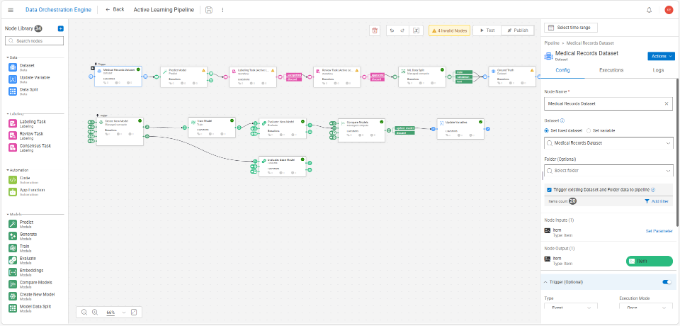
<Active Learning Pipelineテンプレート>
Dataset BrowserとAnnotation Studio
最後に簡単にではありますが、Dell Data Orchestration Engineが持っているDataset BrowserとAnnotation Studioをご紹介します。Dell Data Orchestration Engineは、画像、動画、音声、DICOM、LiDAR、テキスト等、あらゆる非構造化データに対して意味付けを行うことができます。Dataset Browserでは、データセット内に存在するアイテム(ファイル)固有のメタデータやアノテーションを用いた検索や、データセットの統計情報などを確認できるので、少数クラスを特定してHITLタスクに優先的に回すなどの検討材料として利用できます。
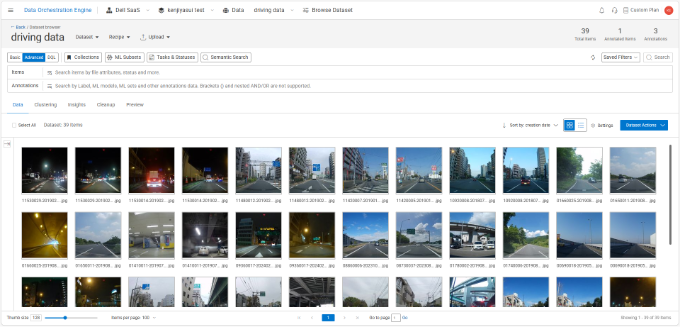
<ドライブレコーダから抽出した画像をアップロードした例>
下記のスクリーンショットでは、サメ、カメ、ライオンなどが写っているWildlife Images Dataset(サンプルのデータセット)に対して、Dataset Browserの機能で可視化(特徴量でクラスタリング)を行い、近傍のデータ(類似画像)に対して一括で「shark」ラベルを追加しています。

<サメが写っている画像に対して一括で「shark」ラベルを追加している例>
HITLタスクなどで手動でアノテーションを追加する場合は、アイテム(ファイル)を選択してAnnotation Studioを起動させる事で、適切なツール(動画ならVideo Studio、音声ならAudio Studio)が起動し、Video Studioであればオブジェクトトラッキング(オブジェクトを自動的に追跡)にも対応しています。下記スクリーンショットは、画像に対してImage Studioでセマンティックセグメンテーションでラベリングした例ですが、他にもバウンディングボックス、ポリゴン、ポイントアノテーション等、用途に応じて様々なツールをご利用頂けます。

<手元にあったデータを何となく選んだら日付が古かったです😢>
まだまだご紹介できていない機能が多いですが、以上Dell Data Orchestration Engineの概要となります。
まとめ
Dell AI Data Platform の一員として、Dell Data Orchestration Engineが加わりました。Dell Data Orchestration EngineはDell AI Data Platformの中核データエンジンとして提供され、既存のパブリッククラウドやオンプレミス環境、他社エコシステムとも連携しながら、AIデータライフサイクル全体を統合的にオーケストレーションします。高度なモデルやAPIとして提供される基盤モデルへのアクセス性が高まる中で、企業ごとの差別化を生み出す源泉は「どんなデータをどのように準備するか」にシフトしつつあり、AIライフサイクルにおいて最も重要なのは品質の高いデータです。Dell AI Data Platform によってインフラレイヤの構築や運用をシンプルにすることで、データチームはエージェントAI を含む次世代のユースケースに備えた「データ準備」に集中できます。
関連リンク
Dell AI Data Platform Technical Solution Guide
Dell AI Data Platform Spec Sheet
Active Learning Pipeline with Dell Data Orchestration Engine
Fuel Analytics and AI Workloads with the Right Data
[Ask The Experts] Dell AI Data Platformはじめました
DataPlatformTech 第36回 Dell Data Search Engineリリース
DataPlatformTech 第34回 Dell Data Lakehouseのアクセスコントロール
DataPlatformTech 第33回 Dell Data Processing Engineリリース
DataPlatformTech 第32回 マルチクラウドにおけるデータプラットフォーム(Snowflake編)
---
Dell Technologies│Data Platform Solutions
インフラストラクチャー ソリューションズ SE統括本部
データプラットフォーム ソリューションズ
安井 謙治