AMD Rom - er det rigtigt? Arkitektur og indledende HPC-ydeevne
Oversigt: I HPC-verdenen i dag er en introduktion til AMD's nyeste generation af EPYC-processorer med kodenavnet Rome.
Denne artikel gælder for
Denne artikel gælder ikke for
Denne artikel er ikke knyttet til et bestemt produkt.
Det er ikke alle produktversioner, der er identificeret i denne artikel.
Symptomer
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage. HPC og AI Innovation Lab, oktober 2019
Årsag
Ikke relevant
Løsning
I HPC-verdenen i dag behøver AMDs nyeste generation EPYC-processor  med kodenavnet Rome næppe en introduktion. Vi har evalueret Rom-baserede systemer i HPC og AI Innovation Lab de sidste par måneder, og Dell Technologies annoncerede
med kodenavnet Rome næppe en introduktion. Vi har evalueret Rom-baserede systemer i HPC og AI Innovation Lab de sidste par måneder, og Dell Technologies annoncerede  for nylig servere, der understøtter denne processorarkitektur. Denne første blog i Rom-serien diskuterer Rom-processorarkitekturen, hvordan den kan indstilles til HPC-ydeevne og præsentere indledende mikrobenchmark-ydeevne. Efterfølgende blogs beskriver applikationsydelse på tværs af domænerne CFD, CAE, molekylær dynamik, vejrsimulering og andre applikationer.
for nylig servere, der understøtter denne processorarkitektur. Denne første blog i Rom-serien diskuterer Rom-processorarkitekturen, hvordan den kan indstilles til HPC-ydeevne og præsentere indledende mikrobenchmark-ydeevne. Efterfølgende blogs beskriver applikationsydelse på tværs af domænerne CFD, CAE, molekylær dynamik, vejrsimulering og andre applikationer.
Arkitektur
Rom er AMDs 2. generation EPYC CPU, der opdaterer deres 1. generation Napoli.
En af de største arkitektoniske forskelle mellem Napoli og Rom, der gavner HPC, er den nye IO-matrice i Rom. I Rom er hver processor en multichippakke bestående af op til 9 chiplets som vist i figur 1. Der er en central 14nm IO-matrice, der indeholder alle IO- og hukommelsesfunktioner - tænk hukommelsescontrollere, Infinity-strukturlinks i stikket og inter-socket-tilslutningsmuligheder og PCI-e. Der er otte hukommelsescontrollere pr. sokkel, der understøtter otte hukommelseskanaler, der kører DDR4 ved 3200 MT/s. En server med en enkelt sokkel kan understøtte op til 130 PCIe Gen4-baner. Et system med to sokler kan understøtte op til 160 PCIe Gen4-baner.
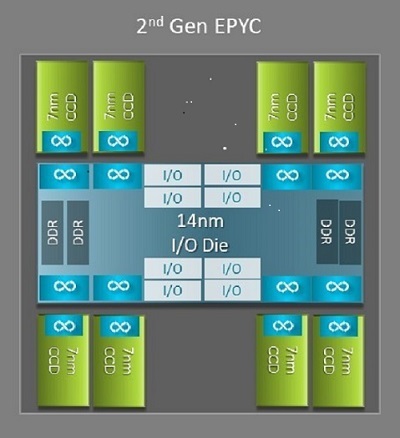
(Figur 1 Rom-multichippakke med en central IO-matrice og op til otte-kerners matricer)
Omkring den centrale IO-matrice er op til otte 7nm kernechiplets. Kernechiplet kaldes en Core Cache-matrice eller CCD. Hver CCD har CPU-kerner baseret på Zen2-mikroarkitekturen, L2-cachen og 32 MB L3-cachen. CCD selv har to Core Cache Complexes (CCX), hver CCX har op til fire kerner og 16MB L3 cache. Figur 2 viser en CCX.
hver CCX har op til fire kerner og 16MB L3 cache. Figur 2 viser en CCX.

(Figur 2 En CCX med fire kerner og delt 16 MB L3-cache)
De forskellige Rom CPU-modeller  har forskellige antal kerner,
har forskellige antal kerner,  men alle har en central IO-matrice.
men alle har en central IO-matrice.
I den øverste ende er en 64 core CPU-model, for eksempel EPYC 7702. Lstopo-output viser os, at denne processor har 16 CCX'er pr. Sokkel, hver CCX har fire kerner som vist i figur.3 &; 4, hvilket giver 64 kerner pr. Sokkel. 16MB L3 per CCX, det vil sige 32MB L3 per CCD giver denne processor i alt 256MB L3 cache. Bemærk dog, at den samlede L3-cache i Rom ikke deles af alle kerner. 16MB L3-cachen i hver CCX er uafhængig og deles kun af kernerne i CCX som vist i figur 2.
En 24-core CPU som EPYC 7402 har en 128MB L3 cache. Lstopo-udgang i figur 3 &; 4 illustrerer, at denne model har tre kerner pr. CCX og 8 CCX pr. sokkel.
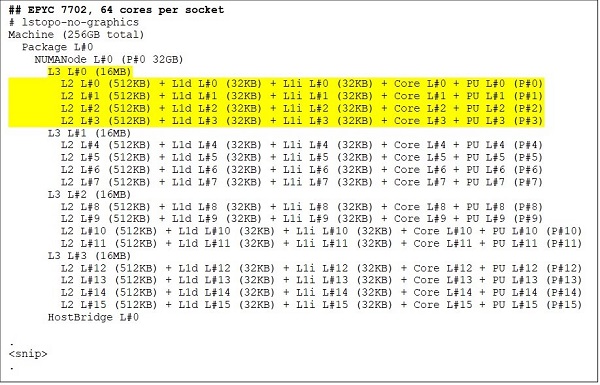
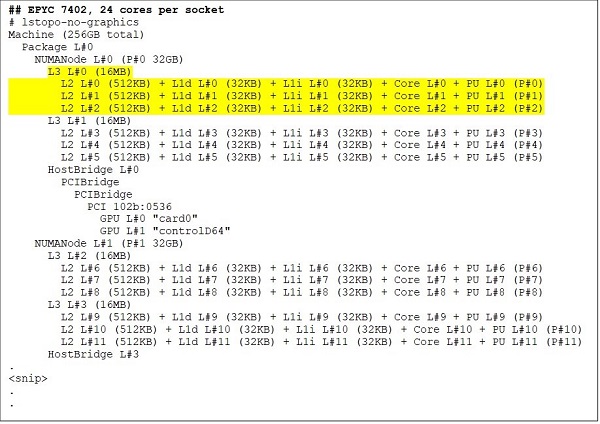
(Figur 3 og 4 lstopo-udgang for CPU'er med 64 kerner og 24 kerner)
Uanset antallet af CCD'er er hver Rom-processor logisk opdelt i fire kvadranter med CCD'er fordelt så jævnt over kvadranterne som muligt og to hukommelseskanaler i hver kvadrant. Den centrale IO-matrice kan betragtes som logisk understøttende de fire kvadranter i soklen.
BIOS-muligheder baseret på Rom-arkitektur
Den centrale IO-matrice i Rom hjælper med at forbedre hukommelseslatenstider  i forhold til dem, der måles i Napoli. Det gør det også muligt at konfigurere CPU'en som et enkelt NUMA-domæne, hvilket muliggør ensartet hukommelsesadgang for alle kernerne i stikkontakten. Dette forklares nedenfor.
i forhold til dem, der måles i Napoli. Det gør det også muligt at konfigurere CPU'en som et enkelt NUMA-domæne, hvilket muliggør ensartet hukommelsesadgang for alle kernerne i stikkontakten. Dette forklares nedenfor.
De fire logiske kvadranter i en Rom-processor gør det muligt at opdele CPU'en i forskellige NUMA-domæner. Denne indstilling kaldes NUMA pr. sokkel eller NPS.
- NPS1 indebærer, at Rom CPU er et enkelt NUMA-domæne med alle kernerne i soklen og al hukommelsen i dette ene NUMA-domæne. Hukommelsen flettes ind på tværs af de otte hukommelseskanaler. Alle PCIe-enheder i soklen tilhører dette enkelte NUMA-domæne
- NPS2 opdeler CPU'en i to NUMA-domæner med halvdelen af kernerne og halvdelen af hukommelseskanalerne på soklen i hvert NUMA-domæne. Hukommelsen er sammenflettet på tværs af de fire hukommelseskanaler i hvert NUMA-domæne
- NPS4 opdeler CPU'en i fire NUMA-domæner. Hver kvadrant er et NUMA-domæne her, og hukommelsen er sammenflettet på tværs af de to hukommelseskanaler i hver kvadrant. PCIe-enheder er lokale for et af fire NUMA-domæner på soklen, afhængigt af hvilken kvadrant af IO-matricen der har PCIe-roden for den pågældende enhed
- Ikke alle CPU er understøtter alle NPS-indstillinger
Hvor NPS4 er tilgængelig, anbefales den til HPC, da den forventes at give den bedste hukommelsesbåndbredde og de laveste ventetider, og vores programmer har tendens til at være NUMA-opmærksomme. Hvor NPS4 ikke er tilgængelig, anbefaler vi, at den højeste NPS understøttes af CPU-modellen - NPS2 eller endda NPS1.
På grund af de mange NUMA-muligheder, der er tilgængelige på Rom-baserede platforme, tillader PowerEdge BIOS to forskellige kerneoptællingsmetoder under MAGT-optælling. Lineær optælling numre kerner i rækkefølge, påfyldning af en CCX, CCD, socket, før du flytter til næste socket. På en 32c CPU vil kernerne 0 til 31 være på den første sokkel, kernerne 32-63 på den anden sokkel. Round robin-optælling nummererer kernerne på tværs af NUMA-regioner. I dette tilfælde er lige nummererede kerner på den første sokkel, ulige nummererede kerner på den anden sokkel. For nemheds skyld anbefaler vi lineær optælling til HPC. Se figur 5 for et eksempel på lineær kerneoptælling på en 64c-server med to sokler, der er konfigureret i NPS4. I figuren er hver kasse med fire kerner en CCX, hvert sæt af otte sammenhængende kerner er en CCD.

(Figur 5 Lineær kernetælling på et system med to sokler, 64c pr. sokkel, NPS4-konfiguration på en 8 CCD CPU-model)
En anden Rom-specifik BIOS-indstilling kaldes Preferred IO Device. Dette er en vigtig indstillingsknap til InfiniBand-båndbredde og meddelelseshastighed. Det gør det muligt for platformen at prioritere trafik for én IO-enhed. Denne indstilling er tilgængelig på Rom-platforme med én og to sokler, og InfiniBand-enheden på platformen skal vælges som den foretrukne enhed i BIOS-menuen for at opnå fuld meddelelseshastighed, når alle CPU-kerner er aktive.
I lighed med Napoli understøtter Rom også hyper-threadingeller logisk processor. For HPC lader vi dette være deaktiveret, men nogle programmer kan drage fordel af at aktivere logisk processor. Se efter vores efterfølgende blogs om applikationsstudier af molekylær dynamik.
I lighed med Napoli tillader Rom også CCX som NUMA-domæne. Denne indstilling viser hver CCX som en NUMA-node. På et system med CPU'er med to sokler med 16 CCX'er pr. CPU viser denne indstilling 32 NUMA-domæner. I dette eksempel har hver sokkel 8 CCD'er, dvs. 16 CCX. Hver CCX kan aktiveres som sit eget NUMA-domæne, hvilket giver 16 NUMA-noder pr. sokkel og 32 i et system med to sokler. For HPC anbefaler vi, at CCX forbliver som NUMA-domæne med standardindstillingen deaktiveret. Aktivering af denne indstilling forventes at hjælpe virtualiserede miljøer.
I lighed med Napoli tillader Rom, at systemet indstilles i Performance Determinism eller Power Determinism-tilstand . I Performance Determinism kører systemet med den forventede frekvens for CPU-modellen, hvilket reducerer variabilitet på tværs af flere servere. I Power Determinism fungerer systemet ved CPU-modellens maksimale TDP. Dette forstærker del til del variation i fremstillingsprocessen, så nogle servere kan være hurtigere end andre. Alle servere kan forbruge CPU'ens maksimale nominelle effekt, hvilket gør strømforbruget deterministisk, men giver mulighed for en vis variation i ydeevnen på tværs af flere servere.
Som du ville forvente af PowerEdge-platforme, har BIOS en metamulighed kaldet Systemprofil. Valg af den ydeevneoptimerede systemprofil aktiverer turbo boost-tilstand, deaktiverer C-tilstande og indstiller determinismeskyderen til Strømdeterminisme, hvilket optimerer ydeevnen.
Ydeevneresultater – STREAM, HPL, InfiniBand mikrobenchmarks
Mange af vores læsere er måske hoppet direkte til dette afsnit, så vi dykker lige ind.
I HPC og AI Innovation Lab har vi opbygget en Rom-baseret klynge med 64 servere, som vi kalder Minerva. Ud over den homogene Minerva-klynge har vi et par andre Rome CPU-prøver, vi kunne evaluere. Vores prøvebænk er beskrevet i tabel.1 og tabel.2.
(Tabel.1 Rom CPU-modeller evalueret i denne undersøgelse)
| CPU | Kerner pr. sokkel | Config | Clockhastighed | TDP |
|---|---|---|---|---|
| 7702 | 64c | 4c pr. CCX | 2,0 GHz | 200 W |
| 7502 | 32c | 4c pr. CCX | 2,5 GHz | 180 W |
| 7452 | 32c | 4c pr. CCX | 2,35 GHz | 155 W |
| 7402 | 24c | 3c pr. CCX | 2,8 GHz | 180 W |
(Tabel.2 Testbed)
| Komponent | Detaljer |
|---|---|
| Server | PowerEdge C6525 |
| Processor | Som vist i tabel 1 med to sokler |
| Hukommelse | 256 GB, 16x16 GB, 3200 MT/sek., DDR4 |
| Interconnect | ConnectX-6 Mellanox Infini-bånd HDR100 |
| Operativsystem | Red Hat Enterprise Linux 7.6 |
| Kerne | 3.10.0.957.27.2.e17.x86_64 |
| Skive | 240 GB SATA SSD M.2-modul |
STRØM
Test af hukommelsesbåndbredde på Rom er vist i figur 6, disse tests blev kørt i NPS4-tilstand. Vi målte ~270-300 GB/s hukommelsesbåndbredde på vores PowerEdge C6525 med to sokler, da vi brugte alle kernerne i serveren på tværs af de fire CPU-modeller, der er angivet i tabel.1. Når der kun bruges én kerne pr. CCX, er båndbredden for systemhukommelsen ~9-17 % højere end den, der måles med alle kerner.
De fleste HPC-workloads vil enten abonnere alle kernerne i systemet helt, eller HPC-centre kører i høj overførselstilstand med flere job på hver server. Derfor er all-core hukommelsesbåndbredde den mere nøjagtige repræsentation af systemets hukommelsesbåndbredde og hukommelsesbåndbredde-per-kernefunktioner.
Figur 6 viser også den hukommelsesbåndbredde, der blev målt på den forrige generation af EPYC Naples-platformen , som også understøttede otte hukommelseskanaler pr. sokkel, men som kørte med 2667 MT/s. Rom-platformen giver 5% til 19% bedre samlet hukommelsesbåndbredde end Napoli, og dette skyldes overvejende den hurtigere 3200 MT / s hukommelse. Selv med 64 kerner pr. sokkel kan Rom-systemet levere op mod 2 GB/s/kerne.
BEMÆRK: En 5-10% præstationsvariation i STREAM Triad-resultater blev målt på tværs af flere identisk konfigurerede Rom-baserede servere, nedenstående resultater må derfor antages at være den øverste ende af intervallet.
Sammenligner man de forskellige NPS-konfigurationer, blev ~13 % højere hukommelsesbåndbredde målt med NPS4 sammenlignet med NPS1 som vist i figur 7.
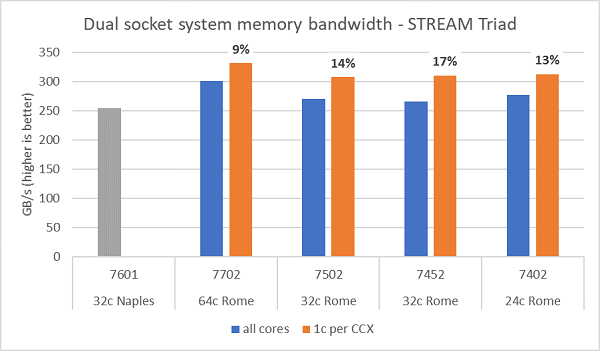
(Figur 6 : NPS4 STREAM med to sokler, Triad-hukommelsesbåndbredde)
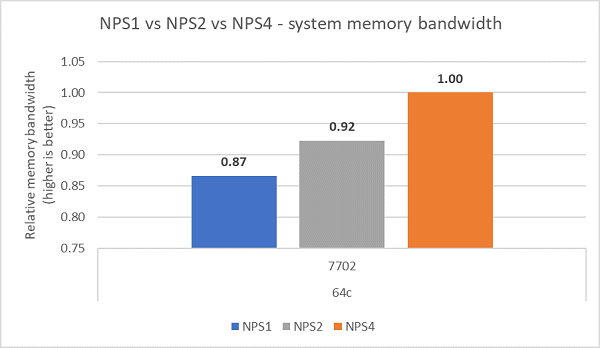
(Figur 7 NPS1 vs. NPS2 vs. NPS 4 hukommelsesbåndbredde)
InfiniBand-båndbredde og meddelelseshastighed
Figur 8 viser single-core InfiniBand-båndbredden til envejs- og tovejstest. Testbænken brugte HDR100, der kører ved 100 Gbps, og grafen viser den forventede linjehastighedsydelse for disse tests.
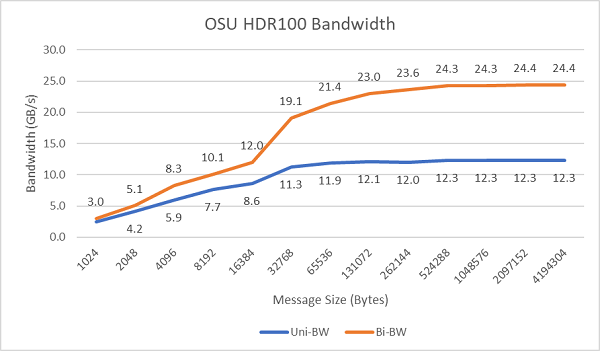
Figur 8 InfiniBand-båndbredde (single-core))
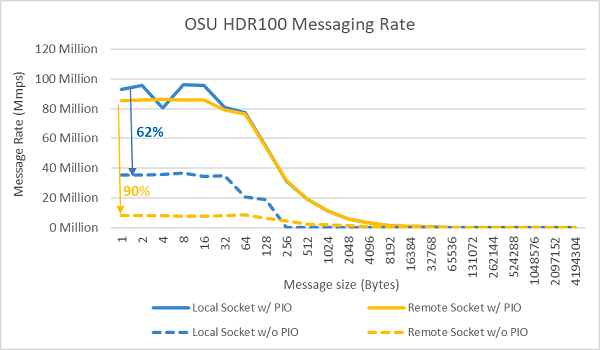
Figur 9 InfiniBand-meddelelseshastighed (alle kerner))
Meddelelseshastighedstest blev derefter udført ved hjælp af alle kernerne på en sokkel i de to servere, der blev testet. Når Foretrukken IO er aktiveret i BIOS, og ConnectX-6 HDR100-adapteren er konfigureret som den foretrukne enhed, er meddelelseshastigheden for hele kernen betydeligt højere, end når Foretrukken IO ikke er aktiveret som vist i figur 9. Dette illustrerer vigtigheden af denne BIOS-indstilling, når der skal finindstilles til HPC og især til applikationsskalerbarhed med flere noder.
HPL
Roms mikroarkitektur kan pensionere 16 DP FLOP / cyklus, dobbelt så meget som Napoli, som var 8 FLOPS / cyklus. Dette giver Rom 4x den teoretiske top FLOPS over Napoli, 2x fra den forbedrede floating-point kapacitet og 2x fra dobbelt så mange kerner (64c vs 32c). Figur 10 viser de målte HPL-resultater for de fire Rome CPU-modeller, vi testede, sammen med vores tidligere resultater fra et Napoli-baseret system. Rom HPL-effektiviteten noteres som procentværdien over søjlerne på grafen og er højere for de lavere TDP CPU-modeller.
Test blev kørt i Power Determinism-tilstand, og et ~ 5% delta i ydeevne blev målt på tværs af 64 identisk konfigurerede servere, resultaterne her er således i dette præstationsbånd.

(Figur 10 HPL med en enkelt server i NPS4)
Derefter blev der udført HPL-test med flere noder, og disse resultater er afbildet i figur 11. HPL-effektiviteten for EPYC 7452 forbliver over 90% på en 64-nodeskala, men dykkene i effektivitet fra 102% ned til 97% og tilbage op til 99% kræver yderligere evaluering.
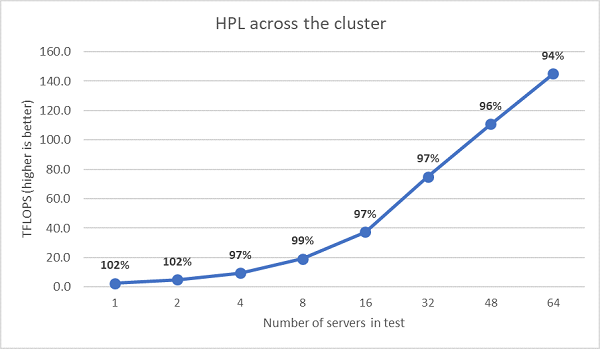
(Figur 11 HPL med flere noder, EPYC 7452 med to sokler over HDR100 InfiniBand)
Resumé og hvad der kommer næste
De indledende undersøgelser af ydeevnen på Rom-baserede servere viser den forventede ydeevne for vores første sæt HPC-benchmarks. BIOS-finjustering er vigtig, når du konfigurerer for at opnå den bedste ydeevne, og der findes finjusteringsmuligheder i vores BIOS HPC-workloadprofil, som kan konfigureres på fabrikken eller indstilles ved hjælp af Dell EMC's systemadministrationshjælpeprogrammer.
HPC og AI Innovation Lab har en ny PowerEdge-klynge Minerva med 64 servere. Se dette rum for efterfølgende blogs, der beskriver undersøgelser af applikationsydelse på vores nye Minerva-klynge.
Berørte produkter
Mellanox Family of Adapters, PowerEdge C6525, PowerEdge C6600, PowerEdge C6615, PowerEdge C6620, PowerEdge HS5610, PowerEdge HS5620, PowerEdge MX760c, PowerEdge R260, PowerEdge R360, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625
, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R860, PowerEdge R960, PowerEdge T160, PowerEdge T360, PowerEdge T560, PowerEdge XE8640, PowerEdge XE9640, PowerEdge XE9680, PowerEdge XR5610, PowerEdge XR7620, PowerEdge XR8000r, PowerEdge XR8610t, PowerEdge XR8620t
...
Artikelegenskaber
Artikelnummer: 000137696
Artikeltype: Solution
Senest ændret: 16 okt. 2025
Version: 11
Find svar på dine spørgsmål fra andre Dell-brugere
Supportservices
Kontrollér, om din enhed er dækket af supportservices.