PowerEdge:AMD Rome - 架構和初始 HPC 效能
Summary: 在當今的 HPC 世界中,對於 AMD 代號為 Rome 的最新一代 EPYC 處理器的介紹。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage。HPC 與 AI 創新實驗室,2019 年 10 月
在當今的 HPC 世界中,AMD 代號為 Rome 的最新一代 EPYC 處理器幾乎不需要介紹。在過去幾個月中,我們一直在 HPC 與 AI 創新實驗室
評估以 Rome 為基礎的系統,而 Dell Technologies 最近也發表了
支援此處理器架構的伺服器。Rome 系列的第一篇部落格討論了 Rome 處理器架構、如何針對 HPC 效能進行調整,並展示了初步的微效能指標結果。後續部落格將介紹 CFD、CAE、分子動力學、氣象模擬及其他應用領域的應用程式效能。
架構
Rome 是 AMD 的第 2 代 EPYC CPU,為其第 1 代 Naples 架構的升級版本。
Naples 與 Rome 之間最大的架構差異之一能使 HPC 獲益,那就是 Rome 中的新 IO 晶粒。在 Rome 中,每個處理器都是一個多晶片封裝,由最多九個小晶片組成,如圖. 1 所示。中央採用一顆14 nm 的 IO 晶粒,整合了所有 IO 與記憶體功能 - 包括記憶體控制器、插槽內及跨插槽的Infinity Fabric 連結架構,以及PCI-e。每個插槽配備八個記憶體控制器,支援八個記憶體通道,執行 DDR4 的速率可達 3200 MT/s。單插槽伺服器可支援最多 130 個 PCIe Gen4 通道。雙插槽系統可支援最多 160 個 PCIe Gen4 通道。
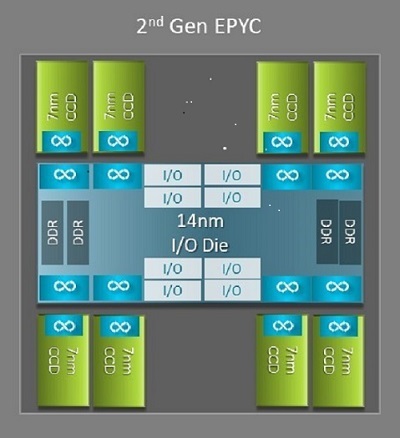
(圖. 1 Rome 多晶片封裝,配備一個中央 IO 晶粒和最多八核心的晶粒)
中央 IO 晶粒周圍有最多八個 7nm 核心小晶片。核心小晶片稱為核心快取晶粒或 CCD。每個 CCD 都有以 Zen2 微架構、L2 快取和 32MB L3 快取為基礎的 CPU 核心。CCD 本身有兩個核心快取複合體 (CCX),每個 CCX 有最多四個核心和 16MB 的 L3 快取。圖. 2 顯示 CCX。

(圖. 2 具有四個核心並共用 16MB L3 快取的 CCX)
不同的 Rome CPU 型號具有不同數量的核心,
但都有一個中央 IO 晶粒。
頂端是 64 核心 CPU 型號,例如 EPYC 7702。Lstopo 輸出顯示,此處理器每個插槽有 16 個 CCX,每個 CCX 有四個核心,如圖. 3 和 4 所示,因此每個插槽有 64 個核心。每個 CCX 的 16MB L3 也就是每個 CCD 的 32MB L3,因此可讓此處理器擁有 256MB L3 快取。但請注意,Rome 中的 L3 快取總數並非由所有核心共用。每個 CCX 中的 16MB L3 快取是獨立的,僅由 CCX 中的核心共用,如圖. 2 所示。
像 EPYC 7402 這樣的 24 核 CPU 擁有 128MB 的 L3 快取。圖. 3 和 4 中的 Lstopo 輸出說明此型號每個 CCX 有三個核心,每個插槽有八個 CCX。
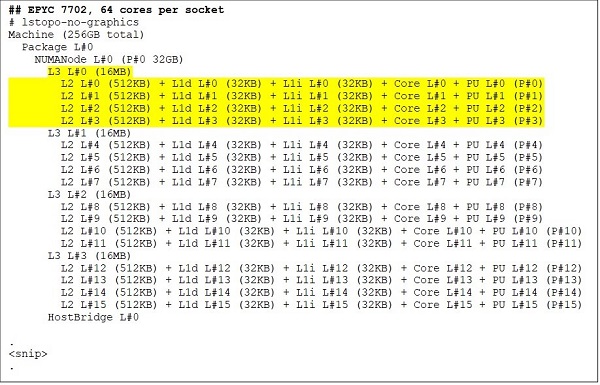
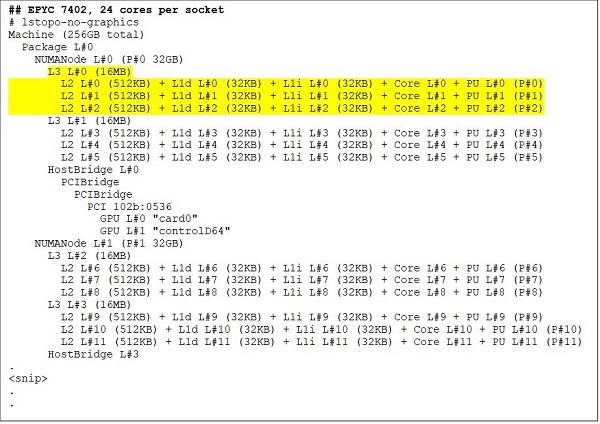
(圖 3 與 4:64 核心和 24 核心 CPU 的 Lstopo 輸出)
無論 CCD 數目為何,每個 Rome 處理器在邏輯上分為四個象限,CCD 盡可能均勻地分佈在四個象限中,每個象限有兩個記憶體通道。中央 IO 晶粒可視為在邏輯上支援插槽的四個象限。
以 Rome 架構為基礎的 BIOS 選項
Rome 的中央 IO 晶粒有助於改善記憶體延遲,相較於 Naples 的測量結果有所提升。此外,它還允許將 CPU 設定為單一的 NUMA 網域,進而實現插槽中所有核心的統一記憶體存取。以下對此進行了說明。
Rome 處理器中的四個邏輯象限可將 CPU 分割成不同的 NUMA 網域。此設定稱為每插槽的 NUMA 或 NPS。
- NPS1 意味著 Rome CPU 是一個單一的 NUMA 網域,插槽中的所有核心以及所有記憶體都位於此一 NUMA 網域內。記憶體在八個記憶體通道中交錯。插槽上的所有 PCIe 裝置都屬於此單一 NUMA 網域
- NPS2 將 CPU 分割成兩個 NUMA 網域,每個 NUMA 網域的插槽上有一半的核心和一半的記憶體通道。記憶體會在每個 NUMA 網域的四個記憶體通道中交錯
- NPS4 將 CPU 分割成四個 NUMA 網域。此處的每個象限均為 NUMA 網域,且記憶體會在每個象限的兩個記憶體通道中交錯。PCIe 裝置隸屬於插槽上四個 NUMA 網域中的其中一個;其歸屬取決於該裝置的 PCIe 根位於 IO 晶粒的哪一個象限
- 並非所有 CPU 都能支援所有 NPS 設定
在可行的情況下,我們建議為 HPC 環境採用 NPS4,因為預期它能提供最佳的記憶體頻寬、最低的記憶體延遲,而且我們的應用程式通常都具備 NUMA 感知能力。在沒有 NPS4 的情況下,我們建議使用 CPU 型號支援的最高 NPS - NPS2,甚至 NPS1。
鑑於以 Rome 為基礎的平台提供了多種 NUMA 選項,PowerEdge BIOS 在 MADT 列舉下允許兩種不同的核心列舉方法。線性列舉會依序為核心編號,先填滿一個 CCX,然後是一個 CCD,接著是一個插槽,之後才會輪到下一個插槽。在一顆 32 核心的 CPU 上,核心 0 到 31 位於第一個插槽上,核心 32 到 63 則位於第二個插槽上。循環式列舉會跨 NUMA 區域輪流為核心編號。在這種情況下,偶數編號的核心位於第一個插槽上,奇數編號的核心位於第二個插槽上。為簡單起見,我們建議對 HPC 進行線性列舉。如需在 NPS4 中設定之雙插槽 64c 伺服器上的線性核心列舉範例,請參閱圖. 5。在圖中,每四個核心的方框代表一個 CCX,每組八個連續核心代表一個 CCD。
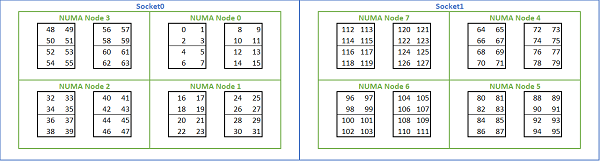
(圖. 5 雙插槽系統上的線性核心列舉,每插槽 64c,八個 CCD CPU 型號上為 NPS4 組態)
另一個 Rome 特定的 BIOS 選項稱為偏好 IO 裝置。這是調整 InfiniBand 頻寬與訊息傳輸速率的重要控制選項。它可讓平台優先處理一個 IO 裝置的流量。此選項適用於單插槽和雙插槽 Rome 平台,且必須在 BIOS 功能表中選取平台中的 InfiniBand 裝置做為偏好的裝置,才能在所有 CPU 核心均處於使用中狀態時達到完全訊息速率。
與 Naples 類似,Rome 也支援超執行緒或邏輯處理器。對於 HPC,我們將其保留為停用狀態,但某些應用程式可以從啟用邏輯處理器中獲益。請尋找我們後續關於分子動力學應用研究的部落格。
與 Naples 類似,Rome 也允許 CCX 作為 NUMA 網域。此選項會將每個 CCX 曝露為 NUMA 節點。在配備雙插槽 CPU 且每顆 CPU 有 16 個 CCX 的系統上,此設定會曝露 32 個 NUMA 網域。在此範例中,每個插槽有八個 CCD,也就是 16 個 CCX。每個 CCX 都可以啟用為自己的 NUMA 網域,每個插槽有 16 個 NUMA 節點,雙插槽系統中則有 32 個。對於 HPC,我們建議在預設的停用選項中將 CCX 保留為 NUMA 網域。啟用此選項應有助於虛擬化環境。
與 Naples 類似,Rome 也允許系統設定為效能確定或功率確定模式。在效能確定模式中,系統會以 CPU 型號的預期頻率操作,減少多部伺服器之間的效能波動。在功率確定模式中,系統會以 CPU 型號的最大可用 TDP 操作。這會放大製造流程中零件與零件之間的差異,讓某些伺服器的速度比其他伺服器更快。所有伺服器都可能會消耗 CPU 的最大額定功率,耗電量具有確定性,但允許在多部伺服器之間的效能存在差異。
正如您對 PowerEdge 平台的期望一樣,BIOS 有一個名為系統設定檔的中繼選項。選取效能最佳化系統設定檔可啟用超級增強模式、停用 C 狀態,並將確定滑桿設定為「功率確定」,以最佳化效能。
效能結果 - STREAM、HPL、InfiniBand 微效能指標
我們的許多讀者可能已經直接跳到了這一部分,所以我們就直接開始了。
在 HPC 與 AI 創新實驗室中,我們已建置了一個由 64 部 Rome 平台伺服器組成的叢集,並將其命名為 Minerva。除了同質的 Minerva 叢集外,我們還有其他幾個 Rome CPU 樣本可供評估。我們的測試平台在表. 1 和表. 2 中描述。
(表. 1 在本研究中進行評估的 Rome CPU 型號)
| CPU | 每個插槽的核心數 | 設定 | 基礎時脈 | TDP |
|---|---|---|---|---|
| 7702 | 64c | 每個 CCX 為 4c | 2.0 GHz | 200W |
| 7502 | 32c | 每個 CCX 為 4c | 2.5 GHz | 180W |
| 7452 | 32c | 每個 CCX 為 4c | 2.35 GHz | 155W |
| 7402 | 24c | 每個 CCX 為 3c | 2.8 GHz | 180W |
(表. 2 試驗平台)
| 元件 | 詳細資料 |
|---|---|
| 伺服器 | PowerEdge C6525 |
| 處理器 | 如表.1 所示的雙插槽 |
| 記憶體 | 256 GB,16x16GB 3200 MT/s DDR4 |
| 互聯 | ConnectX-6 Mellanox Infini Band HDR100 |
| 作業系統 | Red Hat Enterprise Linux 7.6 |
| 核心 | 3.10.0.957.27.2.e17.x86_64 |
| 磁碟 | 240 GB SATA SSD M.2 模組 |
STREAM
Rome 上的記憶體頻寬測試如圖. 6 所示,這些測試是在 NPS4 模式下執行。我們在表. 1 所列的四個 CPU 型號中使用伺服器中的所有核心時,測量到雙插槽 PowerEdge C6525 的 ~270-300 GB/s 記憶體頻寬。若每個 CCX 只使用一個核心,系統記憶體頻寬會比所有核心所測得的頻寬高 ~9-17%。
大多數 HPC 工作負載將完全訂閱系統中的所有核心,或者 HPC 中心會在高輸送量模式下執行,每部伺服器上有多個工作。因此,全核心記憶體頻寬更能準確代表系統的記憶體頻寬及每核心記憶體頻寬能力。
圖. 6 也顯示上一代 EPYC Naples 平台測得的記憶體頻寬,該平台也支援每個插槽八個記憶體通道,但以 2667 MT/s 的速度執行。Rome 平台提供的總記憶體頻寬比 Naples 高 5% 到 19%,這主要歸功於更快的 3200 MT/s 記憶體。即使每個插槽為 64c,Rome 系統仍可為每個核心提供超過 2 GB/s。
注意:在多部設定相同的 Rome 伺服器上測得的 STREAM 三元組結果存在 5-10% 的差異,下方的結果應視為該效能範圍的最高值。
如圖. 7 所示,比較不同的 NPS 組態後,測得 NPS4 的記憶體頻寬比 NPS1 高出約 ~13%。
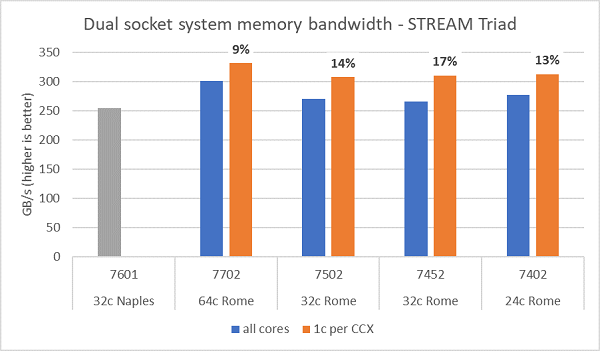
(圖. 6 雙插槽 NPS4 STREAM 三元組記憶體頻寬)
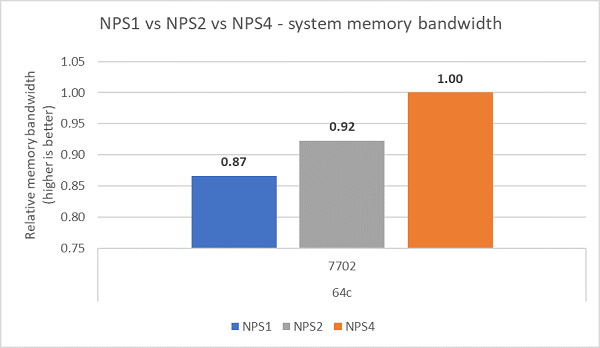
(圖. 7 NPS1 vs NPS2 vs NPS 4 記憶體頻寬)
InfiniBand 頻寬和訊息速率
圖. 8 顯示單向和雙向測試的單核心 InfiniBand 頻寬。測試平台使用了操作速率為 100 Gbps 的 HDR100,圖表顯示了這些測試預期的線路速率效能。
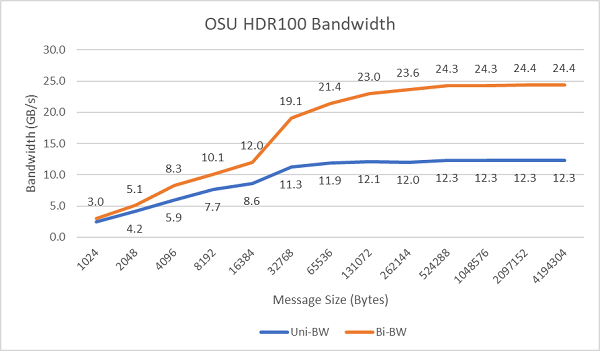
圖. 8 InfiniBand 頻寬 (單核心))
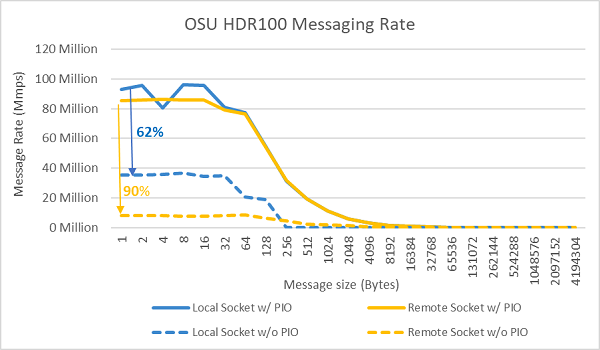
圖. 9 InfiniBand 訊息速率 (所有核心))
接下來,使用兩個受測伺服器中插槽上的所有核心執行訊息速率測試。在 BIOS 中啟用偏好的 IO,並將 ConnectX-6 HDR100 配接卡設定為偏好的裝置時,全核心訊息速率會高於未啟用偏好的 IO 時,如圖. 9 所示。這說明了在針對 HPC,尤其是多節點應用擴展性進行調校時,這個 BIOS 選項的重要性。
HPL
Rome 微架構可以淘汰 16 個 DP FLOP/週期,是 Naples 8 個 FLOP/週期的兩倍。這使得 Rome 的理論峰值 FLOPS 達到 Naples 的 4 倍,其中 2 倍來自增強的浮點運算能力,另外 2 倍則來自核心數量翻倍 (64c 對比 32c)。圖. 10 繪製了我們測試的四款 Rome CPU 型號的 HPL 測量結果,以及我們先前 Naples 系統的測試結果。圖中長條上方的百分比值標註了 Rome 的 HPL 效率,而較低 TDP 的 CPU 型號則顯示出更高的效率。
測試在功率確定模式下執行,並在 64 部設定相同的伺服器上測得 ~5% 的效能差異,因此此處的結果位於該效能區間內。
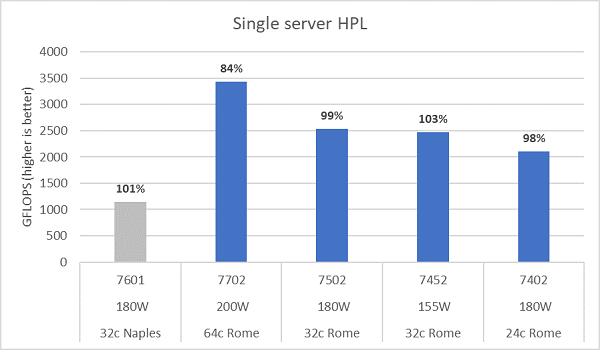
(圖. 10 NPS4 中的單一伺服器 HPL)
接下來執行了多節點 HPL 測試,其結果繪製於圖. 11 中。EPYC 7452 的 HPL 效率在 64 節點的規模下仍保持在 90% 以上,但效率從 102% 下降至 97% 後又回升至 99% 的波動仍需進一步評估。
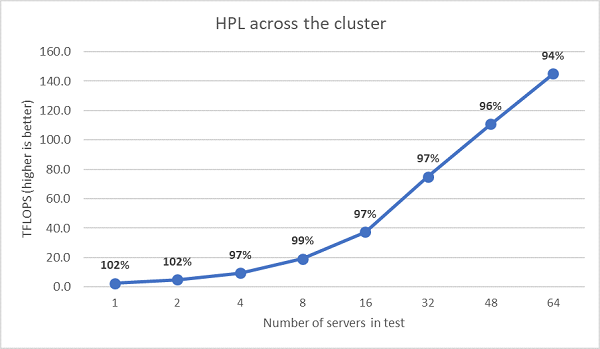
(圖.11 多節點 HPL,雙插槽 EPYC 7452 透過 HDR100 InfiniBand 執行)
摘要與後續內容:
Rome 伺服器的初步效能研究顯示,我們的首批 HPC 效能指標測試結果符合預期。在設定最佳效能時,BIOS 調整至關重要,我們的 BIOS HPC 工作負載設定檔中提供了多項調整選項,這些設定可在出廠時預先進行,亦可透過 Dell EMC 系統管理公用程式進行。
HPC 與 AI 創新實驗室新建置了採用 64 部 Rome 架構 PowerEdge 伺服器的 Minerva 叢集。請持續關注後續部落格文章,我們將發佈關於新建 Minerva 叢集的應用程式效能研究報告。
Affected Products
Mellanox Family of Adapters, PowerEdge C6525, PowerEdge C6615, PowerEdge R6515, PowerEdge R6525, PowerEdge R6615, PowerEdge R6625, PowerEdge R6715, PowerEdge R6725, PowerEdge R7515, PowerEdge R7525, PowerEdge R7615, PowerEdge R7625, PowerEdge R7715
, PowerEdge R7725, PowerEdge R7725xd
...
Article Properties
Article Number: 000137696
Article Type: How To
Last Modified: 16 Oct 2025
Version: 11
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.