Solutions Dell EMC Ready pour le stockage HPC PixStor
Résumé: Architecture de référence de la solution, ainsi que l’évaluation initiale des performances.
Cet article concerne
Cet article ne concerne pas
Cet article n’est associé à aucun produit spécifique.
Toutes les versions du produit ne sont pas identifiées dans cet article.
Symptômes
Article écrit par Mario Gallegos du HPC and AI Innovation Lab en octobre 2019
Cause
.
Résolution
Sommaire
- Introduction
- Architecture de la solution
- Composants de la solution
- Caractérisation des performances
- Performances IOzone séquentielles N clients vers N fichiers
- Performances IOR séquentielles N clients vers 1 fichier
- Petits blocs aléatoires, performances IOzone séquentielles N clients vers N fichiers
- Performances des métadonnées avec MDtest à l’aide de fichiers vides
- Performances des métadonnées avec MDtest à l’aide de fichiers de 4 Kio
- Performances des métadonnées à l’aide de MDtest avec des fichiers 3K
- Analytique avancée
- Conclusions et travaux futurs
Introduction
Les environnements HPC actuels ont intensifié la demande en stockage très haut débit, qui nécessite aussi souvent une capacité élevée et un accès distribué via plusieurs protocoles standard, tels que NFS, SMB, etc. Ces exigences HPC très strictes sont généralement couvertes par des systèmes de fichiers parallèles qui fournissent un accès simultané à un seul fichier ou à un ensemble de fichiers à partir de plusieurs nœuds, en distribuant très efficacement et en toute sécurité les données sur plusieurs LUN réparties sur plusieurs serveurs.Architecture de la solution
Dans ce blog, nous présentons le dernier ajout de Dell EMC aux solutions PFS (Parallel File System) pour les environnements HPC, la solution Dell EMC Ready pour le stockage HPC PixStor. La figure 1 présente l’architecture de référence, qui exploite les serveurs Dell EMC PowerEdge R740 et les baies de stockage PowerVault ME4084 et ME4024, avec le logiciel PixStor de notre société partenaire Arcastream.PixStor comprend le système de fichiers parallèle général, également connu sous le nom de Spectrum Scale, en tant que composant PFS, en plus des composants logiciels Arcastream tels que l’analyse avancée, l’administration et la surveillance simplifiées, la recherche efficace de fichiers, les capacités de passerelle avancées et bien d’autres.
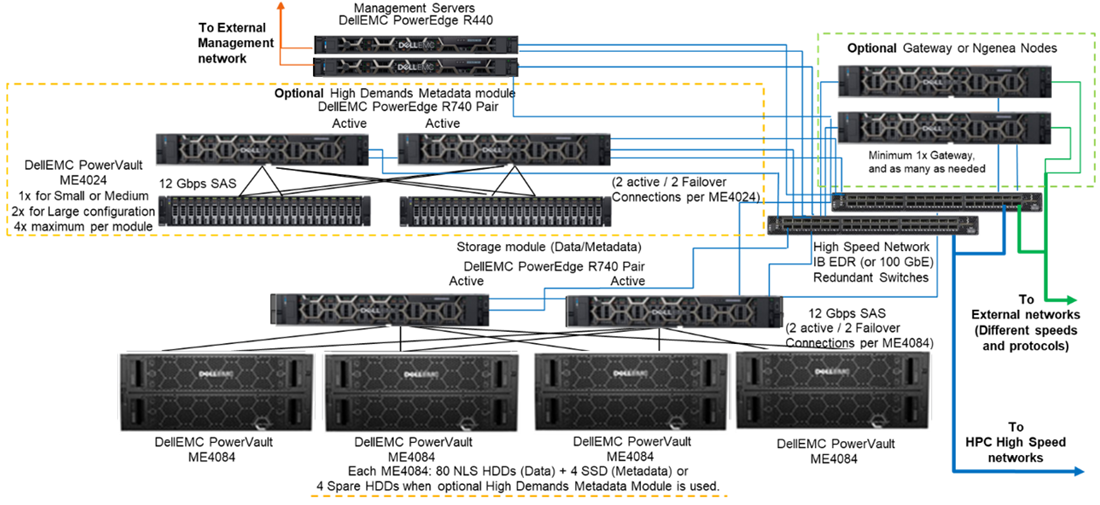
Graphique 1 : Architecture de référence.
Composants de la solution
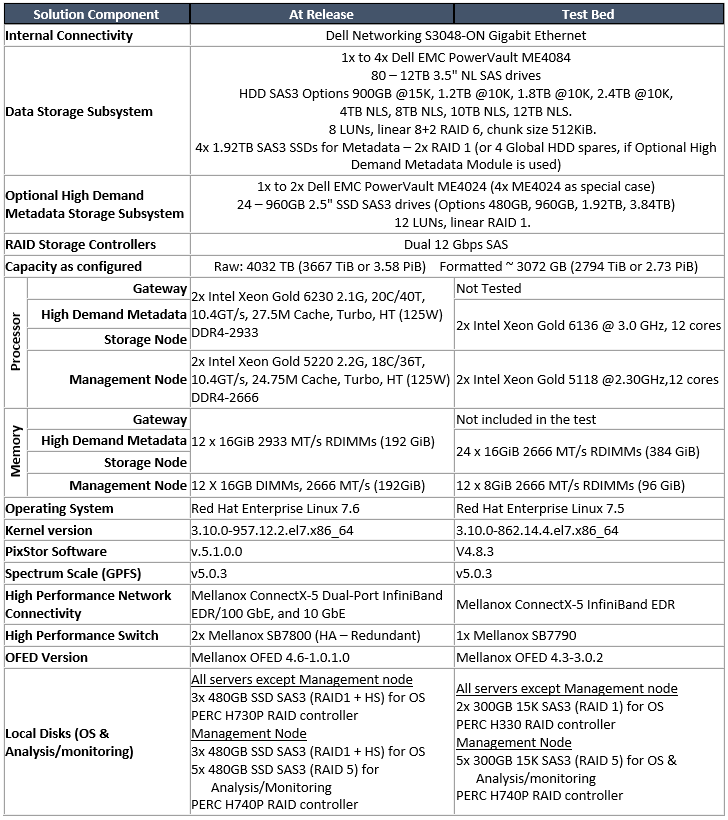
Cette solution devrait être commercialisée avec les derniers processeurs Intel Xeon Scalables de 2e génération, c’est-à-dit des processeurs Cascade Lake, et certains des serveurs utiliseront la RAM la plus rapide disponible (2 933 MT/s). Toutefois, en raison du matériel disponible pour prototyper la solution et caractériser ses performances, les serveurs équipés de processeurs Intel Xeon Xeon Scalable de 1re génération, également appelés Des processeurs Skylake et une RAM plus lente ont été utilisés. Étant donné que le goulot d’étranglement de la solution se situe au niveau des contrôleurs SAS des baies Dell EMC PowerVault ME40x4, aucune disparité significative des performances n’est attendue une fois que les processeurs Skylake et la RAM sont remplacés par les processeurs Cascade Lake envisagés et une RAM plus rapide. En outre, même si la dernière version de PixStor qui prenait en charge RHEL 7.6 était disponible au moment de la configuration du système, il a été décidé de poursuivre le processus d’assurance qualité et d’utiliser Red Hat® Enterprise Linux® 7.5 et la version mineure précédente de PixStor pour caractériser le système. Une fois que le système sera mis à jour vers les processeurs Cascade Lake, le logiciel PixStor sera également mis à jour vers la dernière version et des vérifications ponctuelles des performances seront effectuées pour vérifier que les performances restent proches des chiffres rapportés dans ce document.En raison de la situation décrite précédemment, le Tableau 1 présente la liste des principaux composants de la solution. La colonne du milieu contient les composants planifiés à utiliser au moment de la mise à jour et donc disponibles pour les clients, et la dernière colonne correspond à la liste des composants réellement utilisés pour caractériser les performances de la solution. Les disques répertoriés (NLS 12 To) et les métadonnées (SSD 960 Go) sont utilisés pour l’évaluation des performances, et des disques plus rapides peuvent fournir de meilleures IOPS aléatoires et améliorer les opérations de création/suppression de métadonnées.
Enfin, par souci d’exhaustivité, la liste des disques durs de données et des disques SSD de métadonnées possibles a été incluse, basée sur les disques pris en charge, comme spécifié dans la matrice de support Dell EMC PowerVault ME4, disponible en ligne.
Tableau 1 Composants à utiliser au moment de la libération et ceux utilisés dans le banc d’essai
Caractérisation des performances
Pour caractériser cette nouvelle solution Ready Solution, nous avons utilisé le matériel spécifié dans la dernière colonne du tableau 1, y compris le module de métadonnées à forte demande en option. Afin d’évaluer les performances de la solution, les benchmarks suivants ont été utilisés :- IOzone N à N en mode séquentiel
- IOR N à 1 en mode séquentiel
- IOzone en mode aléatoire
- MDtest
: Pour tous les benchmarks listés ci-dessus, le banc d’essai avait les clients décrits dans le tableau 2 ci-dessous. Étant donné que le nombre de nœuds de calcul disponibles pour les tests était de 16, lorsqu’un nombre de threads plus élevé était requis, ces threads étaient répartis équitablement sur les nœuds de calcul (c’est-à-dire 32 threads = 2 threads par nœud, 64 threads = 4 threads par nœud, 128 threads = 8 threads par nœud, 256 threads = 16 threads par nœud, 512 threads = 32 threads par nœud, 1 024 threads = 64 threads par nœud). L’objectif était de simuler un plus grand nombre de clients simultanés avec le nombre limité de nœuds de calcul. Étant donné que les points de référence prennent en charge un grand nombre de threads, une valeur maximale allant jusqu’à 1 024 a été utilisée (spécifiée pour chaque test), tout en évitant les changements de contexte excessifs et d’autres effets secondaires connexes d’affecter les résultats de performances.
Tableau 2 Banc d’essai clientNombre de nœuds client
16
Nœud client
C6320
Processeurs par nœud client
2 processeurs Intel(R) Xeon(R) Gold E5-2697v4 18 cœurs à 2,30 GHz
Mémoire par nœud client
12 barrettes RDIMM de 16 Gio à 2 400 MT/s
BIOS
2.8.0
Noyau du système d’exploitation
3.10.0-957.10.1
Version de GPFS
5.0.3
Performances IOzone séquentielles N clients vers N fichiers
Les performances séquentielles de N clients vers N fichiers ont été mesurées avec IOzone version 3.487. Les tests exécutés variaient d’un seul thread à 1024 threads.
Les effets de mise en cache ont été minimisés en réglant le pool de pages GPFS à 16 Gio et en utilisant des fichiers plus de deux fois plus volumineux. Il est important de noter que pour GPFS, cette commande tunable définit la quantité maximale de mémoire utilisée pour la mise en cache des données, indépendamment de la quantité de RAM installée et disponible. Il est également important de noter que, alors que dans les solutions HPC Dell EMC précédentes, la taille de bloc pour les transferts séquentiels volumineux est de 1 Mio, GPFS a été formaté avec des blocs de 8 Mio. Par conséquent, cette valeur est utilisée dans le point de référence pour des performances optimales. Cela peut sembler trop volumineux et donner l’impression de gaspiller trop d’espace, mais GPFS utilise l’allocation de sous-blocs pour éviter cette situation. Dans la configuration actuelle, chaque bloc était subdivisé en 256 sous-blocs de 32 Kio chacun.
Les commandes suivantes ont été utilisées pour exécuter le test de référence pour les écritures et les lectures, où Threads était la variable avec le nombre de threads utilisés (1 à 1024 incrémentés en puissances de deux), et threadlist était le fichier qui allouait chaque thread sur un nœud différent, à l’aide de la permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul../iozone -i0 -c -e -w -r 8M -s 128G -t $Threads -+n -+m ./threadlist
./iozone -i1 -c -e -w -r 8M -s 128G -t $Threads -+n -+m ./threadlist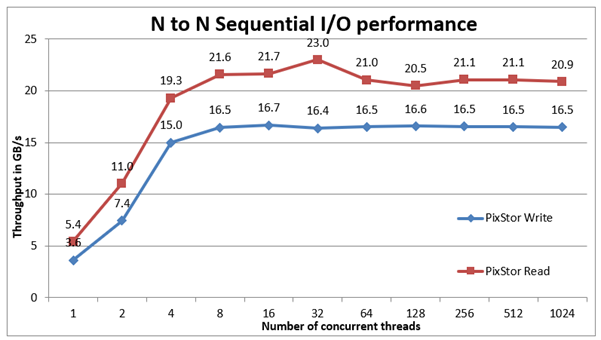
Figure 2 : Performances
séquentielles N à N D’après les résultats, nous pouvons observer que les performances augmentent très rapidement avec le nombre de clients utilisés, puis atteignent un plateau stable jusqu’à ce que le nombre maximum de threads autorisés par IOzone soit atteint, et donc que les performances séquentielles des fichiers volumineux soient stables même pour 1024 clients simultanés. Notez que les performances de lecture maximales étaient de 23 Go/s à 32 threads et que le goulot d’étranglement était très probablement l’interface EDR InfiniBand, tandis que les baies ME4 disposaient encore de performances supplémentaires. De même, notez que les performances d’écriture maximales de 16,7 ont été atteintes un peu tôt à 16 threads et qu’elles sont apparemment faibles par rapport aux spécifications des baies ME4.
Ici, il est important de se rappeler que le mode de fonctionnement préféré de GPFS est dispersé et que la solution a été formatée pour l’utiliser. Dans ce mode, les blocs sont alloués dès le début de manière pseudo-aléatoire, répartissant les données sur toute la surface de chaque disque dur. Si la réduction des performances maximales initiales constitue un inconvénient évident, ces performances demeurent assez constantes, quelle que soit la quantité d’espace utilisée sur le système de fichiers. Ceci contrairement à certains systèmes de fichiers parallèles qui utilisent initialement les pistes externes capables de contenir davantage de données (secteurs) à chaque rotation du disque et atteignent donc les meilleures performances que les disques durs peuvent fournir. Mais étant donné que le système utilise plus d’espace, il utilise des pistes internes qui contiennent moins de données par rotation du disque, ce qui entraîne une réduction des performances.
Performances IOR séquentielles N clients vers 1 fichier
Les performances séquentielles de N clients vers un seul fichier partagé ont été mesurées avec iOR version 3.3.0, en utilisant OpenMPI v4.0.1 pour exécuter le benchmark sur les 16 nœuds de calcul. Les tests exécutés variaient d’un seul thread à 1024 threads.
Les effets de mise en cache ont été minimisés en réglant le pool de pages GPFS à 16 Gio et en utilisant des fichiers plus de deux fois plus volumineux. Ces tests de benchmark ont utilisé des blocs de 8 Mio pour produire des performances optimales. La section précédente sur le test de performance contient une explication plus complète de ces questions.
Les commandes suivantes ont été utilisées pour exécuter le test de référence pour les écritures et les lectures, où Threads était la variable avec le nombre de threads utilisés (de 1 à 1024 incrémenté en puissances de deux), et my_hosts.$Threads est le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant la permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul.mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b 128G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b 128G
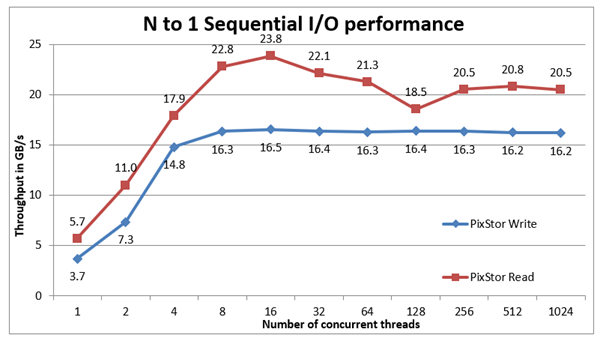
Figure 3 : Performances
séquentielles n à 1 D’après les résultats, nous pouvons observer que les performances augmentent à nouveau très rapidement avec le nombre de clients utilisés, puis atteignent un plateau semi-stable pour les lectures et très stable pour les écritures jusqu’au nombre maximum de threads utilisés dans ce test. Par conséquent, les performances séquentielles d’un seul fichier partagé volumineux sont stables, même pour 1 024 clients simultanés. Notez que les performances de lecture maximales étaient de 23,7 Go/s à 16 threads et que le goulot d’étranglement se situait très probablement au niveau de l’interface EDR InfiniBand, tandis que les baies ME4 disposaient encore de performances supplémentaires. En outre, les performances de lecture ont diminué à partir de cette valeur jusqu’à atteindre le plateau d’environ 20,5 Go/s, avec une diminution momentanée à 18,5 Go/s à 128 threads. De même, notez que les performances d’écriture maximales de 16,5 ont été atteintes à 16 threads et qu’elles sont apparemment faibles par rapport aux spécifications des baies ME4.
Petits blocs aléatoires, performances IOzone séquentielles N clients vers N fichiers
Les performances de N clients aléatoires vers N fichiers ont été mesurées avec IOzone version 3.487. Les tests exécutés variaient d’un seul thread à 1024 threads. Ces tests d’évaluation ont utilisé des blocs de 4 Kio pour émuler le trafic de petits blocs.
Les effets de la mise en cache ont été minimisés en définissant le pool de pages GPFS réglable sur 16 Gio et en utilisant des fichiers deux fois cette taille. La première section du test de performances explique de manière plus exhaustive la raison de son efficacité sur GPFS.
La commande suivante a été utilisée pour exécuter l’analyse comparative en mode IO aléatoire pour les écritures et les lectures, où Threads était la variable avec le nombre de threads utilisés (de 1 à 1024 incrémenté en puissances de deux), et threadlist était le fichier qui allouait chaque thread sur un nœud différent, en utilisant la permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul../iozone -i2 -c -O -w -r 4K -s 32G -t $Threads -+n -+m ./threadlist
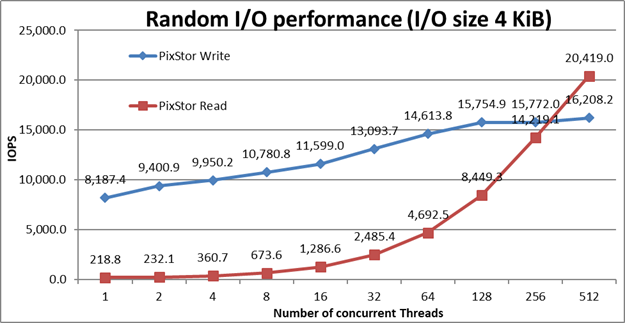
Figure 4 : Performances
aléatoires de N à N D’après les résultats, nous pouvons observer que les performances d’écriture commencent à une valeur élevée de près de 8,2K IOPS et augmentent régulièrement jusqu’à 128 threads où elles atteignent un plateau et restent proches de la valeur maximale de 16,2K IOPS. Les performances de lecture, quant à elles, commencent très modestement à plus de 200 E/S par seconde et augmentent les performances de manière presque linéaire avec le nombre de clients utilisés (gardez à l’esprit que le nombre de threads est doublé pour chaque point de données) et atteignent les performances maximales de 20,4K E/S par seconde à 512 threads sans aucun signe d’atteinte du maximum. Cependant, l’utilisation de plus de threads sur les 16 nœuds de calcul actuels avec deux processeurs chacun et où chaque processeur a 18 cœurs, ont la limitation qu’il n’y a pas assez de cœurs pour exécuter le nombre maximum de threads IOzone (1024) sans encourir de changement de contexte (16 x 2 x 18 = 576 cœurs), ce qui limite considérablement les performances. Un test ultérieur avec plus de nœuds de calcul pourrait vérifier quelles performances de lecture aléatoire peuvent être obtenues avec 1 024 threads avec IOzone, ou IOR pourrait être utilisé pour examiner le comportement avec plus de 1 024 threads.
Performances des métadonnées avec MDtest à l’aide de fichiers vides
Les performances des métadonnées ont été mesurées avec MDtest version 3.3.0, en utilisant OpenMPI v4.0.1 pour exécuter le benchmark sur les 16 nœuds de calcul. Les tests exécutés ont utilisé de 1 à 512 threads. Le point de référence a été utilisé uniquement pour les fichiers (pas de métadonnées de répertoires), pour obtenir le nombre de créations, de statistiques, de lectures et de suppressions que la solution peut gérer.
Pour évaluer correctement la solution par rapport à d’autres solutions de stockage HPC Dell EMC, le module de métadonnées à forte demande en option a été utilisé, mais avec une seule baie ME4024, même si la configuration volumineuse testée dans ce travail a été désignée pour avoir deux ME4024.
Ce module High Demand Metadata est capable de prendre en charge jusqu’à quatre baies ME4024, et il est recommandé d’augmenter le nombre de baies ME4024 à 4 avant d’ajouter un autre de ces modules. On s’attend à ce que les baies ME4024 supplémentaires augmentent les performances des métadonnées de manière linéaire avec chaque baie supplémentaire, sauf peut-être pour les opérations Stat (et les lectures pour les fichiers vides), car les chiffres sont très élevés, à un moment donné, les processeurs deviendront un goulot d’étranglement et les performances ne continueront pas à augmenter de manière linéaire.
La commande suivante a été utilisée pour exécuter le benchmark, « Threads » étant la variable correspondant au nombre de threads utilisés (de 1 à 512, incrémentés par puissances de deux), et « my_hosts.$Threads » le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant une permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul. Comme dans le cas du benchmark d’E/S aléatoires, le nombre maximal de threads a été limité à 512, car il n’y a pas suffisamment de cœurs pour 1 024 threads et la commutation de contexte affecterait les résultats, en signalant un nombre inférieur aux performances réelles de la solution.mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F
Étant donné que les résultats de performance peuvent être affectés par le nombre total d’IOPS, le nombre de fichiers par répertoire et le nombre de threads, il a été décidé de maintenir fixe le nombre total de fichiers à 2 Mio (2^21 = 2097152), le nombre de fichiers par répertoire fixé à 1024, et le nombre de répertoires varie en fonction du nombre de threads, comme indiqué dans le tableau 3.
Tableau 3 : Distribution MDtest des fichiers sur les répertoiresNombre de threads
Nombre de répertoires par thread
Nombre total de fichiers
1
2048
2 097 152
2
1 024
2 097 152
4
512
2 097 152
8
256
2 097 152
16
128
2 097 152
32
64
2 097 152
64
32
2 097 152
128
16
2 097 152
256
8
2 097 152
512
4
2 097 152
1 024
2
2 097 152
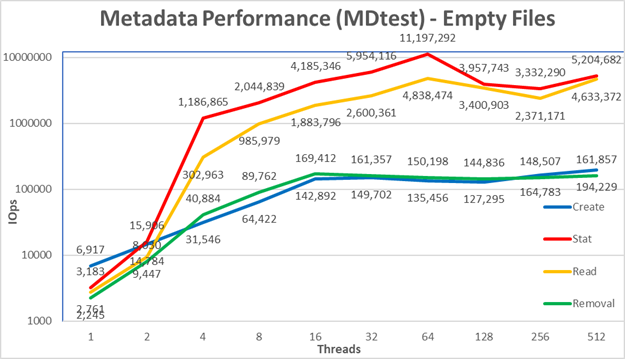
Figure 5 : Performances des métadonnées - Fichiers
vides Tout d’abord, notez que l’échelle choisie était logarithmique en base 10, pour permettre de comparer des opérations qui présentent des différences de plusieurs ordres de grandeur ; Dans le cas contraire, certaines opérations ressembleraient à une ligne plate proche de 0 sur un graphique normal. Un graphe logarithmique en base 2 pourrait être plus approprié, puisque le nombre de threads est augmenté en puissances de 2, mais le graphe serait assez similaire, et les gens ont tendance à manipuler et à se souvenir de meilleurs nombres basés sur des puissances de 10.
Le système obtient de très bons résultats avec des opérations statistiques et de lecture atteignant leur valeur maximale à 64 threads avec respectivement 11,2 millions d’op/s et 4,8 millions d’op/s. Les opérations de suppression ont atteint le maximum de 169,4K op/s à 16 threads et les opérations de création ont atteint leur pic à 512 threads avec 194,2K op/s. Les opérations de statistiques et de lecture sont plus variables, mais une fois qu’elles atteignent leur valeur maximale, les performances ne passent pas en-deçà de 3 millions d’opérations par seconde pour les statistiques et 2 millions d’opérations par seconde pour les lectures. La création et la suppression sont plus stables une fois qu’elles atteignent un plateau et restent au-dessus de 140 000 op/s pour la suppression et de 120 000 op/s pour la création.
Performances des métadonnées avec MDtest à l’aide de fichiers de 4 Kio
Ce test est presque identique au précédent, sauf que les fichiers vides ont été remplacés par de petits fichiers de 4 Kio.
La commande suivante a été utilisée pour exécuter le benchmark, « Threads » étant la variable correspondant au nombre de threads utilisés (de 1 à 512, incrémentés par puissances de deux), et « my_hosts.$Threads » le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant une permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul.mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
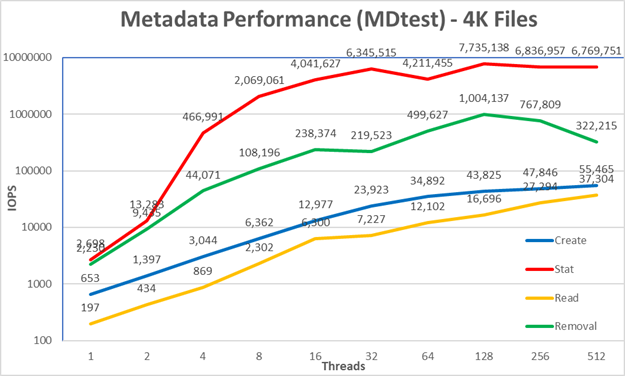
Figure 6 : Performances des métadonnées - Petits fichiers (4K)
Le système obtient de très bons résultats pour les opérations de statistiques et de suppression, atteignant leur valeur maximale à 128 threads avec respectivement 7,7 millions d’op/s et 1 million d’op/s. Les opérations de suppression ont atteint le maximum de 37.3K op/s et les opérations de création ont atteint leur pic avec 55.5K op/s, toutes deux à 512 threads. Les opérations de statistiques et de suppression ont plus de variabilité, mais une fois qu’elles ont atteint leur valeur maximale, les performances ne descendent pas en dessous de 4 millions d’op/s pour les statistiques et de 200 000 op/s pour la suppression. Les opérations de création et de lecture ont moins de variabilité et continuent d’augmenter à mesure que le nombre de threads augmente.
Étant donné que ces chiffres se rapportent à un module de métadonnées avec un seul ME4024, les performances augmenteront pour chaque baie ME4024 supplémentaire, mais nous ne pouvons pas simplement supposer une augmentation linéaire pour chaque opération. À moins que le fichier entier ne s’insère dans l’inode de ce fichier, les cibles de données sur les ME4084 seront utilisées pour stocker les fichiers 4K, ce qui limite les performances dans une certaine mesure. Étant donné que la taille de l’inode est de 4 Kio et qu’il doit toujours stocker des métadonnées, seuls les fichiers d’environ 3 Kio s’y intègrent, et tout fichier plus volumineux utilisera des cibles de données.
Performances des métadonnées à l’aide de MDtest avec des fichiers 3K
Ce test est presque exactement identique aux précédents, sauf que de petits fichiers de 3 Kio ont été utilisés. La principale différence est que ces fichiers s’insèrent complètement à l’intérieur de l’inode. Par conséquent, les nœuds de stockage et leurs ME4084 ne sont pas utilisés, ce qui améliore la vitesse globale en utilisant uniquement des supports SSD pour le stockage et moins d’accès au réseau.
La commande suivante a été utilisée pour exécuter le benchmark, « Threads » étant la variable correspondant au nombre de threads utilisés (de 1 à 512, incrémentés par puissances de deux), et « my_hosts.$Threads » le fichier correspondant qui a alloué chaque thread sur un nœud différent, en utilisant une permutation circulaire pour les répartir de manière homogène sur les 16 nœuds de calcul.mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 3K -e 3K
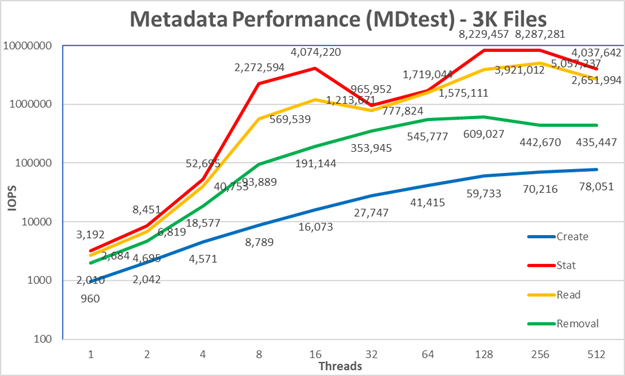
Figure 7 : Performances des métadonnées - Petits fichiers (3K) Le système obtient de très bons résultats pour les opérations statistiques et de lecture,
atteignant leur valeur maximale à 256 threads avec respectivement 8,29 millions d’op/s et 5,06 millions d’op/s. Les opérations de suppression ont atteint le maximum de 609 000 op/s à 128 threads et les opérations de création ont atteint leur pic avec 78 000 op/s à 512 threads. Les opérations de statistiques et de lecture présentent une plus grande variabilité que les opérations de création et de suppression. La suppression a une légère baisse des performances pour les deux points de threads les plus élevés, ce qui suggère que les performances soutenues après 128 threads seront légèrement supérieures à 400K op/s. Les créations ont continué d’augmenter jusqu’à 512 threads, mais il semble qu’elles atteignent un plateau, de sorte que les performances maximales peuvent toujours être inférieures à 100 000 op/s.
Étant donné que les petits fichiers de ce type sont entièrement stockés sur le module de métadonnées SSD, les applications nécessitant des performances supérieures pour les petits fichiers peuvent utiliser un ou plusieurs modules de métadonnées à forte demande en option pour augmenter les performances des petits fichiers. Cependant, les fichiers qui s’insèrent dans l’inode sont minuscules par rapport aux normes actuelles. En outre, étant donné que les cibles de métadonnées utilisent des RAID1 avec des disques SSD relativement petits (taille maximale de 19,2 To), la capacité sera limitée par rapport aux nœuds de stockage. Par conséquent, il convient d’éviter de remplir les cibles de métadonnées, ce qui peut entraîner des défaillances inutiles et d’autres problèmes.
Analytique avancée
Parmi les fonctionnalités de PixStor, la surveillance du système de fichiers via l’analytique avancée peut être essentielle pour simplifier considérablement l’administration, en aidant à identifier de manière proactive ou réactive les problèmes ou les problèmes potentiels. Nous allons maintenant brièvement passer en revue certaines de ces fonctionnalités.
La Figure 8 présente des informations utiles en fonction de la capacité du système de fichiers. Sur le côté gauche, l’espace total utilisé du système de fichiers et les dix principaux utilisateurs en fonction de la capacité utilisée du système de fichiers. Sur la droite, une vue historique avec la capacité utilisée sur de nombreuses années, puis les dix principaux types de fichiers utilisés et les dix principaux jeux de fichiers, tous deux basés sur la capacité utilisée, dans un format similaire aux graphiques de Pareto (sans les lignes pour les totaux cumulés). Avec ces informations, il peut être facile de trouver des utilisateurs qui obtiennent plus que leur juste part du système de fichiers, des tendances d’utilisation de la capacité pour aider à la prise de décisions sur la croissance future de la capacité, quels fichiers utilisent le plus d’espace ou quels projets prennent le plus de capacité.
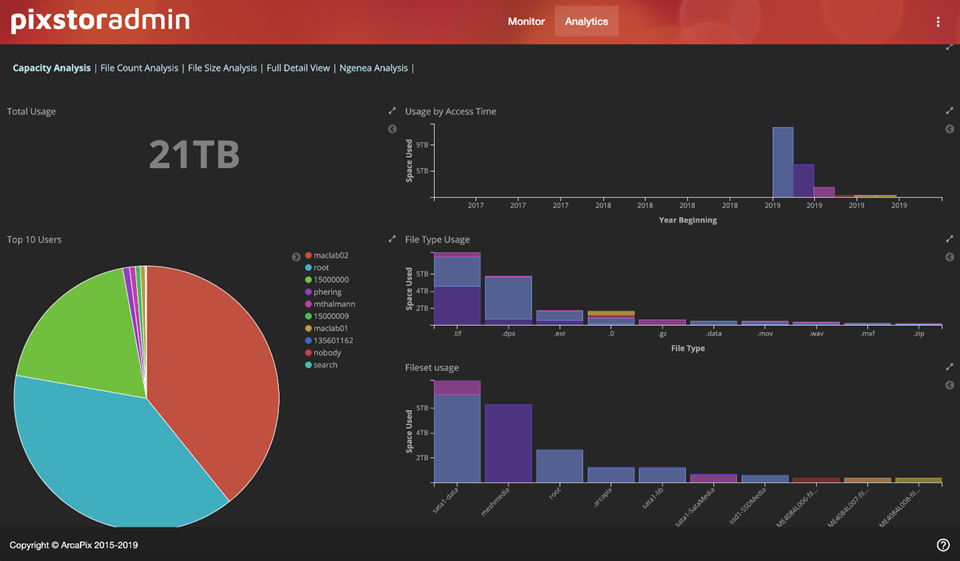
Figure 8 : PixStor Analytics - Vue de la
capacité La Figure 9 fournit une vue du nombre de fichiers avec deux méthodes très utiles pour rechercher des problèmes. La première moitié de l’écran présente les dix principaux utilisateurs dans un graphique circulaire, ainsi que les dix principaux types de fichiers et les dix principaux ensembles de fichiers (pensez aux projets) dans un format similaire aux graphiques de Pareto (sans les lignes pour les totaux cumulés), le tout en fonction du nombre de fichiers. Ces informations peuvent être utilisées pour répondre à certaines questions importantes. Par exemple, quels utilisateurs monopolisent le système de fichiers en créant trop de fichiers, quel type de fichier crée un cauchemar de métadonnées ou quels projets utilisent la plupart des ressources.
La moitié inférieure comporte un histogramme avec le nombre de fichiers (fréquence) pour les tailles de fichiers utilisant 5 catégories pour différentes tailles de fichiers. Cela peut être utilisé pour avoir une idée des tailles de fichiers utilisées sur l’ensemble du système de fichiers, qui, coordonnées avec les types de fichiers, peuvent être utilisées pour décider si la compression sera bénéfique.
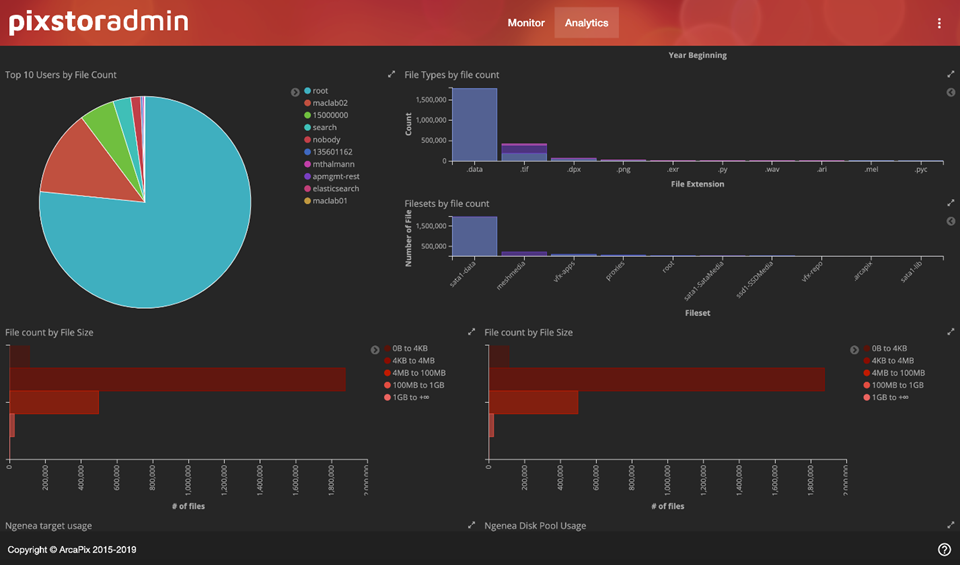
Figure 9 : PixStor Analytics - Vue du nombre de fichiers
Conclusions et travaux futurs
La solution actuelle a été en mesure de fournir des performances assez bonnes, qui devraient être stables quel que soit l’espace utilisé (puisque le système a été formaté en mode dispersé), comme le montre le tableau 4. En outre, la solution évolue de manière linéaire en termes de capacité et de performances à mesure que l’on ajoute des modules de nœuds de stockage, et on peut s’attendre à observer une augmentation de performances similaire avec le module High Demand Metadata en option. Cette solution fournit aux clients HPC un système de fichiers parallèle très fiable utilisé par la plupart des 500 principaux clusters HPC. En outre, il offre des capacités de recherche exceptionnelles, une surveillance et une gestion avancées, et l’ajout de passerelles facultatives permet le partage de fichiers via des protocoles standard omniprésents tels que NFS, SMB et autres vers autant de clients que nécessaire.
Tableau 4 Performances optimales et soutenues
Performances maximales
Performances continues
Écriture
Read
Écriture
Read
Mode séquentiel volumineux N clients vers N fichiers
16,7 Go/s
23 Go/s
16,5 Gbit/s
20,5 Gbit/s
Mode séquentiel volumineux N clients vers un seul fichier partagé
16,5 Gbit/s
23,8 Go/s
16,2 Go/s
20,5 Gbit/s
Mode aléatoire avec petits blocs N clients vers N fichiers
15,8 KIOps
20,4 KIOps
15,7 KIOps
20,4 KIOps
Métadonnées, opérations de création, fichiers vides
169 400 IOPS
127 200 E/S par seconde
Métadonnées, opérations de statistiques, fichiers vides
11,2 millions d’E/S par seconde
3,3 millions d’E/S par seconde
Métadonnées, opérations de lecture, fichiers vides
4,8 millions d’E/S par seconde
2,4 millions d’IOPS
Métadonnées, opérations de suppression, fichiers vides
194 200 E/S par seconde
144 800 E/S par seconde
Métadonnées, opérations de création, fichiers de 4 Kio
55 400 E/S par seconde
55 400 E/S par seconde
Métadonnées, opérations de statistiques, fichiers de 4 Kio
6,4 millions d’E/S par seconde
4 millions d’E/S par seconde
Métadonnées, opérations de lecture, fichiers de 4 Kio
37 300 E/S par seconde
37 300 E/S par seconde
Métadonnées, opérations de suppression, fichiers de 4 Kio
1 million d’E/S par seconde
219 500 E/S par seconde
Étant donné que la solution est destinée à être commercialisée avec des processeurs Cascade Lake et avec une RAM plus rapide, une fois la configuration finale établie, les performances feront l’objet de vérifications ciblées. Il sera également nécessaire de tester le module High Demand Metadata en option avec au moins 2 baies ME4024 et des fichiers de 4 Kio pour mieux retracer l’évolution des performances des métadonnées lorsque des cibles de données sont impliquées. En outre, les performances des nœuds de passerelle seront mesurées et consignées dans un nouvel article de blog ou un livre blanc, avec les résultats de ces vérifications ciblées. Enfin, d’autres composants de la solution doivent être testés et publiés pour offrir encore davantage de fonctionnalités.
Produits concernés
High Performance Computing Solution Resources, Dell EMC PowerVault ME4012, Dell EMC PowerVault ME4024, Dell EMC PowerVault ME4084Propriétés de l’article
Numéro d’article: 000130962
Type d’article: Solution
Dernière modification: 19 avr. 2026
Version: 7
Trouvez des réponses à vos questions auprès d’autres utilisateurs Dell
Services de support
Vérifiez si votre appareil est couvert par les services de support.