Dell Ready Solution per lo storage HPC Lustre: Cascade Lake Refresh
Riepilogo: Dell Ready Solution per lo storage HPC Lustre: Cascade Lake Refresh
Questo articolo si applica a
Questo articolo non si applica a
Questo articolo non è legato a un prodotto specifico.
Non tutte le versioni del prodotto sono identificate in questo articolo.
Sintomi
Articolo scrittodaio dell'HPC and AI Innovation Lab nel mese di giugno 2019
Causa
None
Risoluzione
Questo blog annuncia la disponibilità di Dell Ready Solution per Lustre con processori Cascade Lake. In questo blog presentiamo le specifiche tecniche aggiornate della soluzione Lustre, i risultati delle prestazioni iniziali della soluzione aggiornata e un confronto tra i risultati attuali e i risultati precedenti. Abbiamo configurato lo stack della soluzione con nuovi aggiornamenti, come illustrato nella Tabella 1 con l'interconnessione EDR, verificato che l'installazione funzionasse come previsto ed eseguito controlli delle prestazioni.
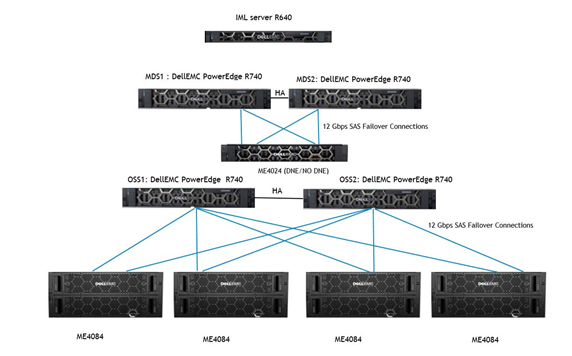
Il diagramma dell'architettura per la configurazione di base di grandi dimensioni è illustrato di seguito nella Figura 1.
Tenere presente che i modelli di server e storage restano invariati come illustrato in precedenza. Solo i nuovi aggiornamenti sono mostrati nella Tabella 1.
Abbiamo configurato la Ready Solution aggiornata come elencata nella Tabella 1 ed eseguito controlli delle prestazioni con benchmark IOzone sequenziali, casuali IOzone e MDtest per verificare le prestazioni della soluzione aggiornata. La metodologia di test, inclusi i comandi di benchmark per tutti i test, è identica al metodo utilizzato e descritto in precedenza.
Per tutti i test abbiamo utilizzato il banco di prova del client come descritto nella Tabella 2 riportata di seguito
Abbiamo eseguito la versione IOzone sequenziale 3.487, utilizzando i client elencati nella Tabella 2. Abbiamo eseguito test da un singolo thread fino a 256 thread, con più thread per client oltre 8 thread. In base al metodo di test, la dimensione aggregata dei dati per il test era di 2 TB. Per i conteggi di thread inferiori a 32 thread, è stato utilizzato un numero di stripe Lustre pari a 32 e per i conteggi di thread maggiori di 32, il conteggio degli stripe Lustre è stato impostato su 1. Gli effetti della memorizzazione nella cache sono stati ridotti al minimo come descritto nel blog precedente.
I parametri di tuning lato client Lustre utilizzati per questo test sono elencati di seguito
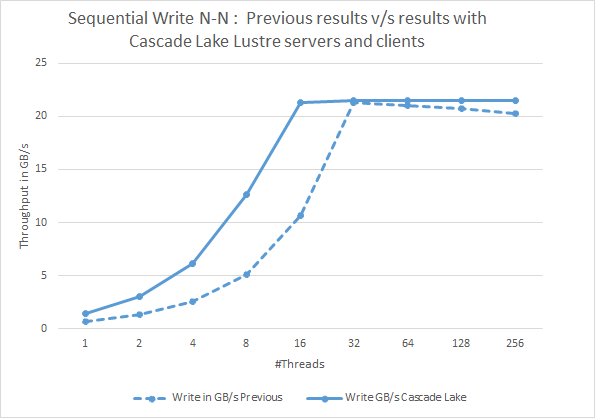
Figura 2: Scritture N-N sequenziali. Confronto dei risultati precedenti con i risultati attuali che utilizzano server e client
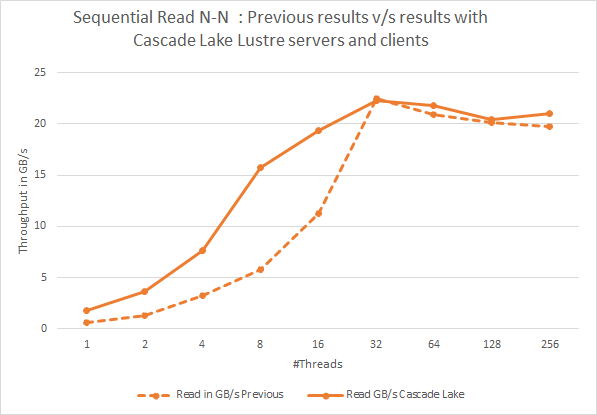
Cascade Lake LustreFigura 3: Letture N-N sequenziali. Confronto dei risultati precedenti con i risultati attuali che utilizzano server e client
Cascade Lake LustreLe figure 2 e 3 presentano le prestazioni di lettura e scrittura sequenziale IOzone della soluzione basata su Cascade Lake più recente e confrontano questi risultati con quelli della precedente soluzione basata su Skylake. Rispetto ai risultati precedenti, vediamo un miglioramento delle prestazioni nelle letture sequenziali e nelle scritture con client basati su Cascade Lake e server Lustre per il numero di thread inferiore a 32 thread. È possibile notare un miglioramento delle prestazioni fino a poco più di 2 volte nelle scritture sequenziali e nelle letture con un numero di thread inferiore a 32 thread. Riteniamo che questo delta delle prestazioni possa essere attribuito alle attenuazioni hardware per gli exploit side-channel inclusi nei processori Cascade Lake (ref link). Tuttavia, altri fattori che contribuiscono potrebbero anche essere una memoria più veloce nella nuova soluzione e le versioni software aggiornate.
È inoltre possibile notare che le prestazioni sequenziali con conteggi di thread più elevati rimangono molto simili alla soluzione precedente. Ciò è dovuto al fatto che i miglioramenti apportati ai processori Cascade Lake non contribuiscono a migliorare le prestazioni quando la soluzione è in funzione al pieno potenziale dei controller di storage back-end.
Abbiamo eseguito random IOzone, versione 3.487, utilizzando i client elencati nella Tabella 2. ed ha eseguito controlli delle prestazioni con 16, 64 e 256 thread. Analogamente al metodo di test precedente, la dimensione aggregata dei dati era di 2 TB e la dimensione di stripe era impostata su 4 MB. Gli effetti della memorizzazione nella cache sono stati ridotti al minimo come descritto nel blog precedente.
I parametri di tuning lato client Lustre utilizzati per questo test sono elencati di seguito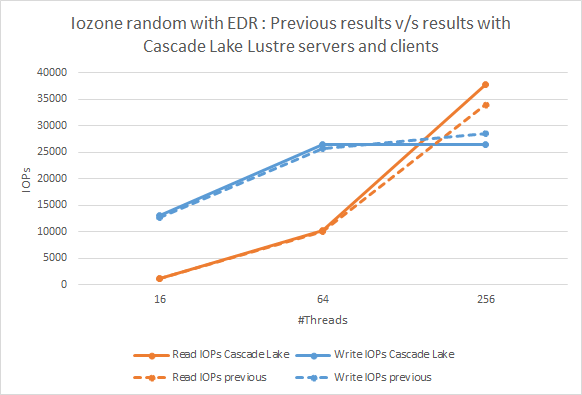
Figura 4: Letture N-N casuali IOzone.Un confronto tra i risultati precedenti e i risultati attuali che utilizzano server e client
Cascade Lake LustreLa Figura 4 traccia i risultati dei test di I/O casuali. Confrontando i risultati precedenti e attuali, vediamo che la tendenza rimane la stessa e il delta delle prestazioni osservato non è statisticamente significativo in base alla variazione eseguita per l'esecuzione.
È stato utilizzato lo strumento MDTest versione 1.9.3 per valutare le prestazioni dei metadati del sistema. La distribuzione MPI utilizzata era Intel MPI. I test sono stati eseguiti utilizzando DNE con 2 MDT e striping di directory. La metodologia di test, il comando utilizzato e il numero di file e directory creati erano identici a quanto spiegato nel blog precedente.
2) Benchmark Mdtest
Il diagramma dell'architettura per la configurazione di base di grandi dimensioni è illustrato di seguito nella Figura 1.
Tenere presente che i modelli di server e storage restano invariati come illustrato in precedenza. Solo i nuovi aggiornamenti sono mostrati nella Tabella 1.
Figura 1: Dell Ready Solution per lo storage HPC Lustre: Diagramma dell'architettura della configurazione di base L
Tabella 1: Aggiornate le specifiche tecniche di Ready Solution for Lustre e un rapido confronto con la release precedente
| Componente hardware/software | Corrente | Indietro |
|---|---|---|
| Processori in OSS e MDSObject Storage Server (OSS) e metadata server (MDS) | 2 CPU Intel Xeon™ Gold 6230 con 20 core a 2,1 GHz per OSS/MDS | 2 Intel Xeon™ Gold 6136 con 12 core a 3 GHz |
| Processore nel server Integrated Manager for Lustre (IML) | 2 Intel Xeon Gold 5218 con 16 core a 2,3 GHz | 2 Intel Xeon Gold 5118 con 12 core a 2,3 GHz |
| DIMM di memoria in OSS e MDS | 12 RDIMM DDR4 da 32 GiB a 2.933 MT/s | 24 RDIMM DDR4 da 16 GiB a 2.666 MT/s |
| DIMM di memoria nel server IML | 12 RDIMM DDR4 da 8 GiB a 2.666 MT/s | 12 RDIMM DDR4 da 8 GB a 2.666 MT/s |
| BIOS | 2.1.8 o versioni successive | 1.4.5 o versioni successive |
| OS Kernel | 3.10.0-957.1.3 | 3.10.0-862 |
| Versione Lustre | 2.10.7 | 2.10.4 |
| Versione IML | 4.0.10.0 | 4.0.7.0 |
| Mellanox OFED | 4.5-1.0.1.0 | 4.4-1 |
Risultati delle prestazioni
Abbiamo configurato la Ready Solution aggiornata come elencata nella Tabella 1 ed eseguito controlli delle prestazioni con benchmark IOzone sequenziali, casuali IOzone e MDtest per verificare le prestazioni della soluzione aggiornata. La metodologia di test, inclusi i comandi di benchmark per tutti i test, è identica al metodo utilizzato e descritto in precedenza.
Per tutti i test abbiamo utilizzato il banco di prova del client come descritto nella Tabella 2 riportata di seguito
Tabella 2: Banco di prova client
| Numero di nodi client | 8 |
|---|---|
| Nodo client | C6420 |
| Processori per nodo client | 2 Intel(R) Xeon(R) Gold 6248 con 20 core a 2,5 GHz |
| Memoria per nodo client | 12 RDIMM da 16 GiB e 2.933 MT/s |
| BIOS | 2.2.6 |
| OS Kernel | 3.10.0-957.10.1 |
| Versione Lustre | 2.10.7 |
| Mellanox OFED | 4.5-1.0.1.0 |
Prestazioni IOzone sequenziali
Abbiamo eseguito la versione IOzone sequenziale 3.487, utilizzando i client elencati nella Tabella 2. Abbiamo eseguito test da un singolo thread fino a 256 thread, con più thread per client oltre 8 thread. In base al metodo di test, la dimensione aggregata dei dati per il test era di 2 TB. Per i conteggi di thread inferiori a 32 thread, è stato utilizzato un numero di stripe Lustre pari a 32 e per i conteggi di thread maggiori di 32, il conteggio degli stripe Lustre è stato impostato su 1. Gli effetti della memorizzazione nella cache sono stati ridotti al minimo come descritto nel blog precedente.
I parametri di tuning lato client Lustre utilizzati per questo test sono elencati di seguito
lctl set_param osc.*.checksums=0
lctl set_param timeout=600
lctl set_param at_min=250
lctl set_param at_max=600
lctl set_param ldlm.namespaces.*.lru_size=2000
lctl set_param osc.)*OST*.max_rpcs_in_flight=16
lctl set_param osc.*OST*.max_dirty_mb=1024
lctl set_param osc.*.max_pages_per_rpc=1024
lctl set_param llite.*.max_read_ahead_mb=1024
lctl set_param llite.*.max_read_ahead_per_ file_mb = 1024
Figura 2: Scritture N-N sequenziali. Confronto dei risultati precedenti con i risultati attuali che utilizzano server e client
Cascade Lake LustreFigura 3: Letture N-N sequenziali. Confronto dei risultati precedenti con i risultati attuali che utilizzano server e client
Cascade Lake LustreLe figure 2 e 3 presentano le prestazioni di lettura e scrittura sequenziale IOzone della soluzione basata su Cascade Lake più recente e confrontano questi risultati con quelli della precedente soluzione basata su Skylake. Rispetto ai risultati precedenti, vediamo un miglioramento delle prestazioni nelle letture sequenziali e nelle scritture con client basati su Cascade Lake e server Lustre per il numero di thread inferiore a 32 thread. È possibile notare un miglioramento delle prestazioni fino a poco più di 2 volte nelle scritture sequenziali e nelle letture con un numero di thread inferiore a 32 thread. Riteniamo che questo delta delle prestazioni possa essere attribuito alle attenuazioni hardware per gli exploit side-channel inclusi nei processori Cascade Lake (ref link). Tuttavia, altri fattori che contribuiscono potrebbero anche essere una memoria più veloce nella nuova soluzione e le versioni software aggiornate.
È inoltre possibile notare che le prestazioni sequenziali con conteggi di thread più elevati rimangono molto simili alla soluzione precedente. Ciò è dovuto al fatto che i miglioramenti apportati ai processori Cascade Lake non contribuiscono a migliorare le prestazioni quando la soluzione è in funzione al pieno potenziale dei controller di storage back-end.
Prestazioni IOzone casuali
Abbiamo eseguito random IOzone, versione 3.487, utilizzando i client elencati nella Tabella 2. ed ha eseguito controlli delle prestazioni con 16, 64 e 256 thread. Analogamente al metodo di test precedente, la dimensione aggregata dei dati era di 2 TB e la dimensione di stripe era impostata su 4 MB. Gli effetti della memorizzazione nella cache sono stati ridotti al minimo come descritto nel blog precedente.
I parametri di tuning lato client Lustre utilizzati per questo test sono elencati di seguito
lctl set_param osc.*OST*.max_rpcs_in_flight=256
lctl set_param osc.*.max_pages_per_rpc=1024
Figura 4: Letture N-N casuali IOzone.Un confronto tra i risultati precedenti e i risultati attuali che utilizzano server e client
Cascade Lake LustreLa Figura 4 traccia i risultati dei test di I/O casuali. Confrontando i risultati precedenti e attuali, vediamo che la tendenza rimane la stessa e il delta delle prestazioni osservato non è statisticamente significativo in base alla variazione eseguita per l'esecuzione.
Prestazioni MDtest metadati
È stato utilizzato lo strumento MDTest versione 1.9.3 per valutare le prestazioni dei metadati del sistema. La distribuzione MPI utilizzata era Intel MPI. I test sono stati eseguiti utilizzando DNE con 2 MDT e striping di directory. La metodologia di test, il comando utilizzato e il numero di file e directory creati erano identici a quanto spiegato nel blog precedente.
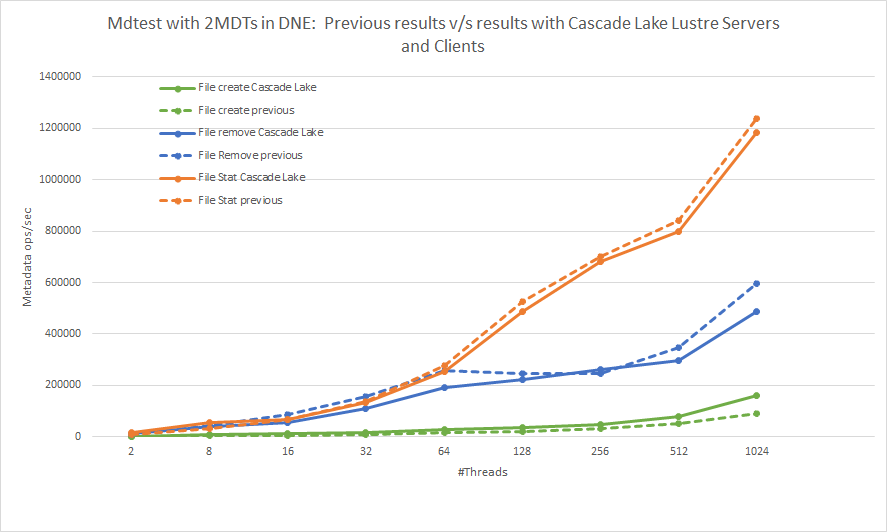
Figura 5. Operazioni di metadati con MDtest. Confronto dei risultati precedenti con i risultati attuali che utilizzano server e client
Cascade Lake LustreLa Figura 5 presenta i risultati dei test sui metadati. Confrontando i risultati correnti con i risultati precedenti, vediamo che la tendenza per tutte e tre le operazioni di metadati rimane invariata. Possiamo notare un miglioramento del 75,4% nelle operazioni di creazione dei file di picco, un calo del 18% nelle operazioni di rimozione dei file di picco e un delta delle prestazioni trascurabile nelle operazioni di statistica dei file. È possibile attribuire i delta delle prestazioni osservati agli aggiornamenti software e hardware nello stack di soluzioni come illustrato nella Tabella 1.
Conclusione
Abbiamo verificato e convalidato gli aggiornamenti della Lustre Ready Solution per quanto riguarda la configurazione, l'installazione e le prestazioni. In questo blog sono inclusi anche i dati sulle prestazioni raccolti.
Confronto dei risultati precedenti con i risultati correnti con server e client
Lustre basati su Cascade Lake 1) I/O sequenziale: Vediamo un miglioramento delle prestazioni leggermente superiore a 2 volte con scritture sequenziali e letture sequenziali con un numero di thread inferiore a 32 thread. Il picco delle prestazioni rimane simile alla soluzione basata su Skylake precedente.
2) I/O casuale: È possibile riscontrare una tendenza molto simile nelle prestazioni di lettura e scrittura con un delta delle prestazioni non statisticamente significativo considerando la variazione eseguita per l'esecuzione.
3) Test delle prestazioni dei metadati: Vediamo un miglioramento nelle operazioni di creazione di file fino al 75,4% al picco. Le operazioni di statistica dei file rimangono molto vicine ai risultati osservati in precedenza con delta delle prestazioni trascurabile. Vediamo un calo di circa il 18% nelle operazioni di rimozione dei file al picco, mentre la tendenza generale per le operazioni di rimozione dei file rimane invariata e trascurabile in altri conteggi di thread.
Riferimenti
1) Benchmark IOzone2) Benchmark Mdtest
Prodotti interessati
High Performance Computing Solution ResourcesProprietà dell'articolo
Numero articolo: 000144408
Tipo di articolo: Solution
Ultima modifica: 19 gen 2024
Versione: 6
Trova risposta alle tue domande dagli altri utenti Dell
Support Services
Verifica che il dispositivo sia coperto dai Servizi di supporto.