VMware: Felsökningsmanual för fysisk vSAN-disk
Sammanfattning: Det här är en allmän felsökningsguide som hjälper dig att identifiera om det finns ett problem med en fysisk disk i vSAN-kluster.
Den här artikeln gäller för
Den här artikeln gäller inte för
Den här artikeln är inte kopplad till någon specifik produkt.
Alla produktversioner identifieras inte i den här artikeln.
Instruktioner
Söka efter status för den fysiska vSAN-disken från webbgränssnittet:
Anslut till vCenter Server Web Client och kontrollera diskstatusen från:
Inventering > Värd och kluster > vSAN-kluster > Konfigurera > vSAN-diskhantering >
Bild 1: vSAN-diskhanteringsvy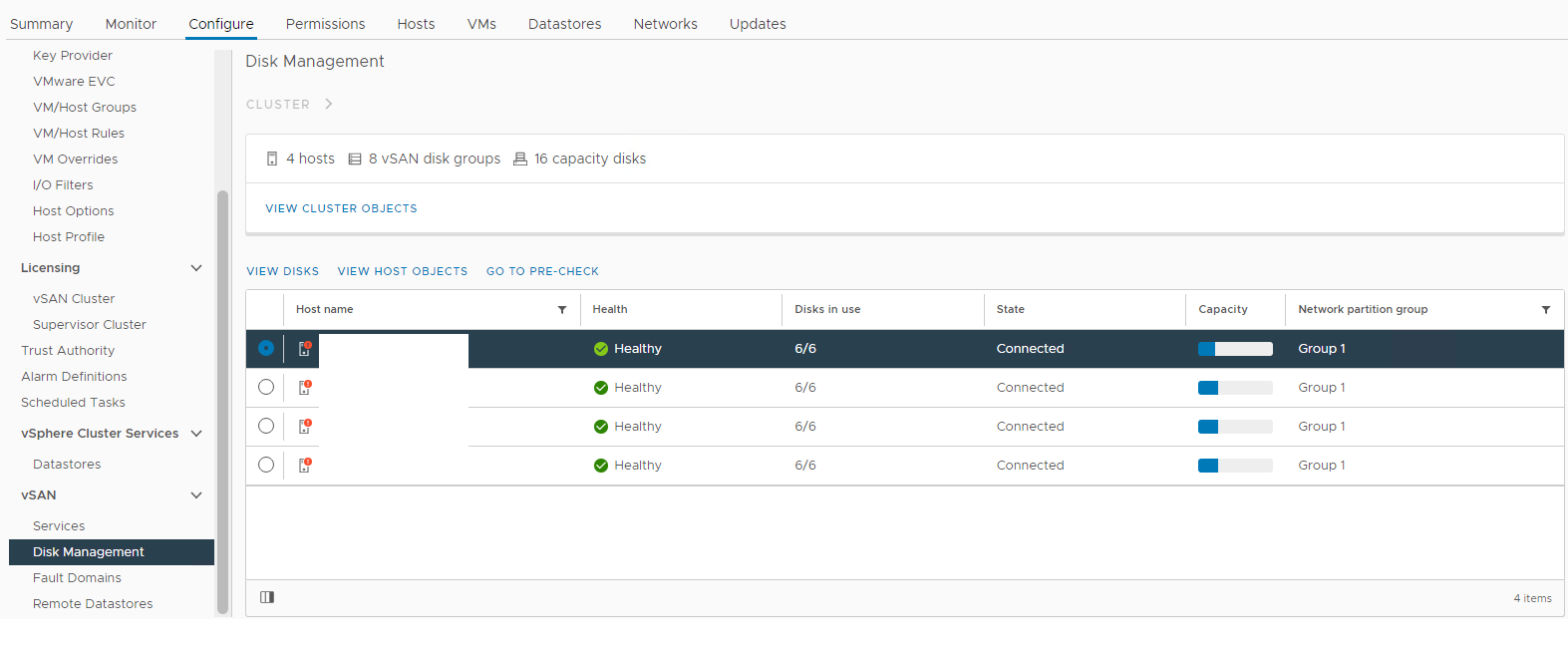
Välj den berörda värden och expandera sedan avsnittet Visa disk:
Bild 2: vyn vSAN-diskgrupp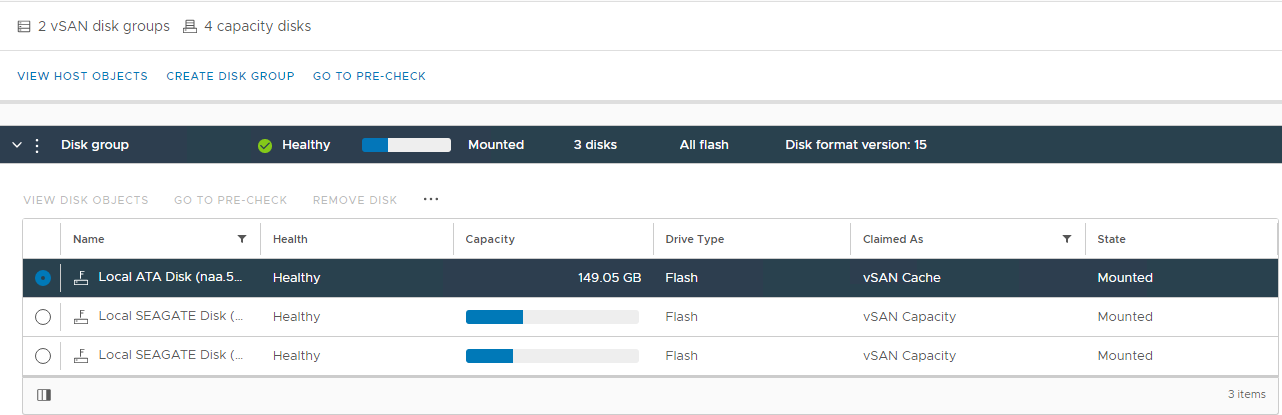
Här kan du kontrollera om en disk detekteras som:
Ej felfri
Omonterad
0 Kapacitet
Permanent diskfel
Disk Disk Disk
Disk saknas
Kontrollera även om det finns diskrelaterade larm som utlöses från avsnittet vSAN Skyline Health:
Inventering > Värd och kluster > vSAN Cluster > Monitor > vSAN > Skyline Health > fysisk disk
Bild 3: Skyline Health view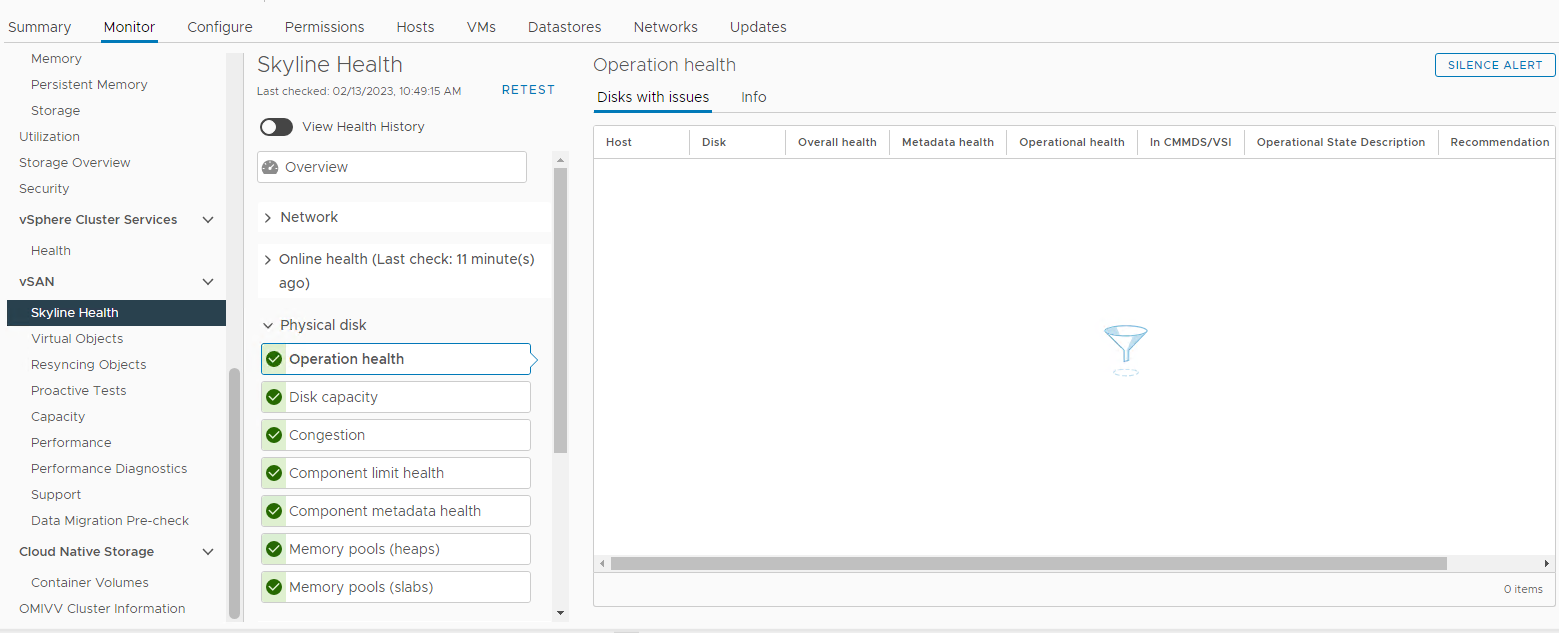
Här kan du kontrollera om något av följande larm utlöses:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Du kan också kontrollera diskstatus i listan över lagringsenheter för den berörda värden:
Inventering > Värd och kluster > vSAN-kluster > som påverkas vSAN ESXi-värdkonfigurera >> lagringsenheter >
Bild 4: Vyn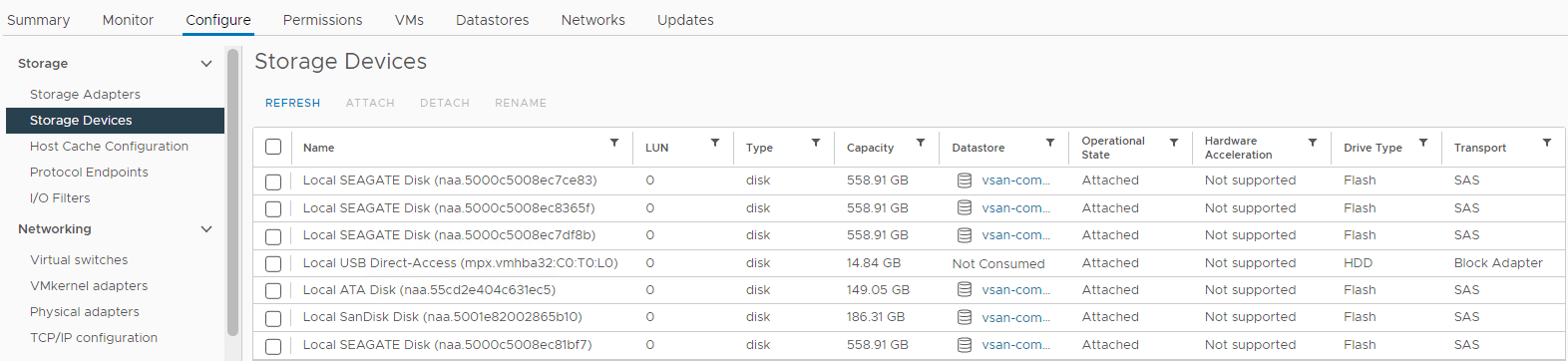
Värdlagringsenheter Här kan du kontrollera om en diskstatus är:
0 Kapacitetsdisk
frånvarande
disk omonterad
Kontrollera om det sker en omsynkronisering:
Inventering > Värd och kluster > vSAN Cluster > Monitor > vSAN > synkronisera om objekt:
Bild 5: Synkronisera om objektvyn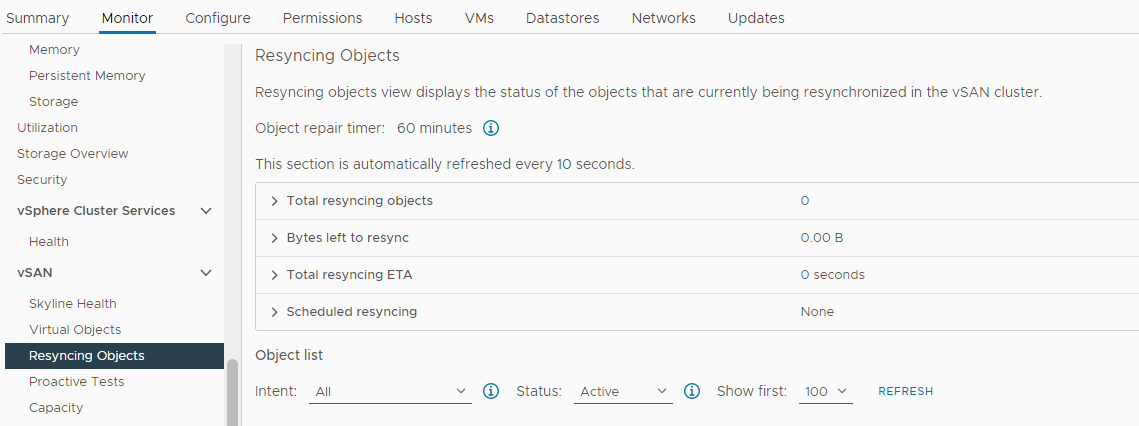
Obs! Omsynkronisering kan tyda på att data evakueras från en berörd disk eller diskgrupp. Ytterligare undersökning krävs för att avgöra om den berörda disken är redo att tas bort eller bytas ut.
Kontrollera status för vSAN-objekt:
Inventering > Värd och kluster > vSAN Cluster > Monitor > vSAN > Skyline Health > Data > vSAN object health
Bild 6: vy över vSAN-objekthälsa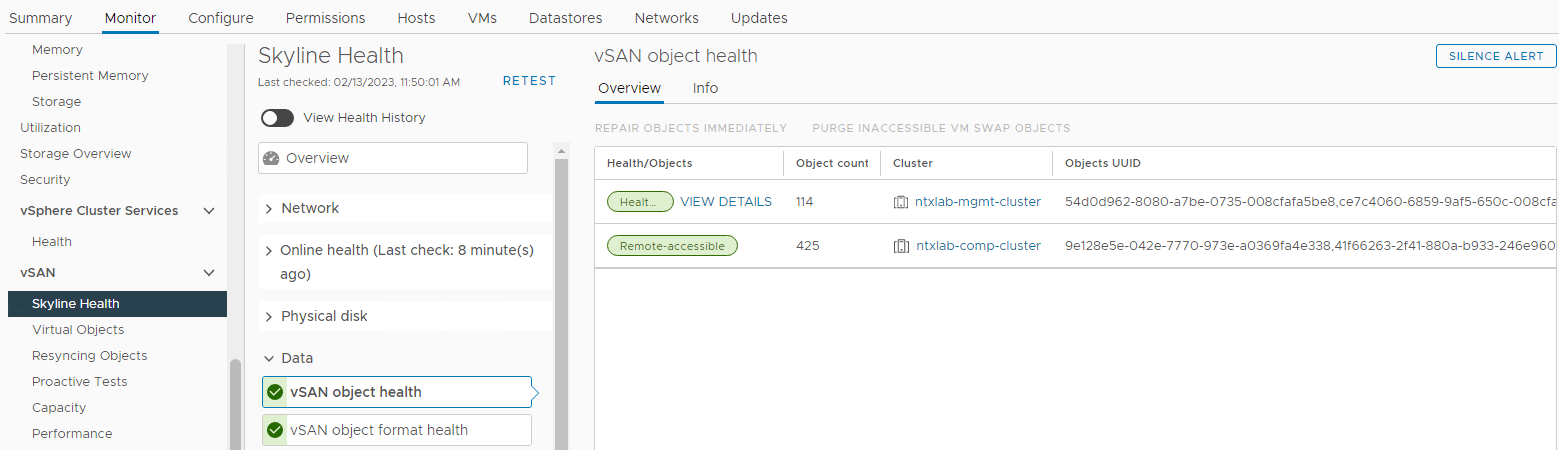
Obs! Det är viktigt att kontrollera att det inte finns några otillgängliga objekt. Objekt otillgängligt betyder "alla kopior av objektet saknas". Om du tar bort eller byter ut en disk som kan orsaka DL.
Nästa steg är att samla in mer information om problemet via CLI och kontrollera loggarna:
Söker efter status för fysisk vSAN-disk från CLI:
Anslut via SSH till den berörda värden och kör följande kommandon:
vdq -qH
Markera på "IsPDL" (permanent enhetsförlust) parameter. Om det är lika med 1 går disken förlorad.
Exempel:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Kontrollera om det saknas en disk i diskgruppen.
Exempel:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Kontrollera på "In CMMDS"-parametern. Om det är falskt går kommunikationen förlorad till disken.
Exempel:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Kontrollera om det finns läs-/skrivfel med smart get-kommandot.
Exempel:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Kontrollera om det finns tillgängliga diskgrupper.
Exempel:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Kontrollera om det finns pågående eller fastnade omsynkroniseringsåtgärder.
Exempel:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Tryck på Ctrl+C för att stoppa kommandot.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Kontrollera komponenternas tillstånd.
Healthy -- state 7Inaccessible -- state 13Absent or Degraded -- state 15
Exempel:
425 state\": 7
Så här identifierar du var den felaktiga SSD-disken eller HÅRDDISKEN finns över CLI:
Visa en lista över alla tillgängliga enheter:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Exempel:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Kontrollera platsen med hjälp av varje disk naa från listan:
esxcli storage core device physical get -d
Exempel:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Så här identifierar du en defekt hårddisk eller SSD om enhetsnamnet saknas:
Det är möjligt att den felaktiga disken inte detekteras och inte kan identifieras med hjälp av motsvarande naa. I det här scenariot är det nödvändigt att hitta alla diskar, och den som inte är fysiskt lokaliserad är den som misslyckades.
Här är ett skript som kan användas för att utföra uppgiften något snabbare:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
vSAN-relevanta loggar för lagringsrelaterade problem:
/var/log/vmkernel.log
Problem med läsning och skrivning till vSAN-diskar, vSAN-värdpulsslag, PDL:er, SCSI-sense-koder och I/O-begäranden (läsningar/skrivningar) samt information om klustermedlemskap.
Exempel:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Rapporterar om diskhälsa, permanenta förlorade enheter (PDL), disksvarstider och rapporter om när en värd går in i och avslutar underhållsläge.
Exempel:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Det hjälper dig att avgöra om disken har markerats som felaktig på grund av överdriven loggträngsel eller I/O-latenser.
Exempel:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Berörda produkter
PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650, PowerEdge R650xs
, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, VMware ESXi 6.7.X, VMware ESXi 7.x, VMware ESXi 8.x, VMware VSAN, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node, VxRail 460 and 470 Nodes, VxRail D560, VxRail D560F, VxRail E460, VxRail E560, VxRail E560F, VxRail E560N, VxRail E660, VxRail E660F, VxRail E660N, VxRail E665, VxRail E665F, VxRail E665N, VxRail G560, VxRail G560F, VxRail P470, VxRail P570, VxRail P570F, VxRail P580N, VxRail P670F, VxRail P670N, VxRail P675F, VxRail P675N, VxRail S470, VxRail S570, VxRail S670, VxRail V470, VxRail V570, VxRail V570F, VXRAIL V670F, VxRail VD-4510C, VxRail VD-4520C, VxRail VE-660, VxRail VE-6615, VxRail VE-670, VxRail VP-760, VxRail VP-7625, VxRail VP-770
...
Produkter
VxRail, PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650
, PowerEdge R650xs, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node
...
Artikelegenskaper
Artikelnummer: 000209262
Artikeltyp: How To
Senast ändrad: 09 mars 2026
Version: 6
Få svar på dina frågor från andra Dell-användare
Supporttjänster
Kontrollera om din enhet omfattas av supporttjänster.