Dell EMC Ready Solution for HPC PixStor Storage - NVMe 계층
Summary: HPC 스토리지 솔루션 구성 요소에 대한 블로그로, 아키텍처와 성능 평가를 포함합니다.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
작성자: HPC 및 AI Innovation Lab의 Mario Gallegos, 2020년 6월
HPC 스토리지 솔루션 구성 요소에 대한 블로그로, 아키텍처와 성능 평가를 포함합니다.
HPC 스토리지 솔루션 구성 요소에 대한 블로그로, 아키텍처와 성능 평가를 포함합니다.
Resolution
Dell EMC Ready Solution for HPC PixStor Storage
NVMe 계층
목차
랜덤 작은 블록 IOzone 성능 N 클라이언트-N 파일
소개
오늘날의 HPC 환경에서는 초고속 스토리지에 대한 수요가 증가했고, CPU 수, 네트워크 속도 및 메모리의 증가와 함께 스토리지가 많은 워크로드에서 병목 현상이 발생하고 있었습니다. 이렇게 수요가 많은 HPC 요구 사항은 일반적으로 여러 서버에 걸쳐 여러 LUN에 데이터를 매우 효율적이고 안전하게 배포하여 단일 파일 또는 여러 노드의 파일 세트에 동시에 액세스할 수 있는 PFS(병렬 파일 시스템)를 통해 처리됩니다. 이러한 파일 시스템은 대체로 가장 낮은 비용으로 가장 높은 용량을 제공하는 회전식 미디어입니다. 하지만 회전식 미디어의 속도와 레이턴시가 많은 최신 HPC 워크로드의 요구 사항을 충족할 수 없는 경우가 많아지고 있습니다. 그에 따라 버스트 버퍼, 더욱 빠른 계층 또는 매우 빠른 스크래치, 로컬 또는 분산 등의 형태로 플래시 기술을 사용해야 합니다. DellEMC Ready Solution for HPC PixStor Storage는 NVMe 노드를 구성 요소로 사용하여 이렇게 새로운 고대역폭 요구 사항을 충족하는 동시에 유연성, 확장성, 효율성 및 신뢰성을 제공합니다.
솔루션 아키텍처
이 블로그는 HPC 환경을 위한 PFS(Parallel File System) 솔루션 시리즈의 일부로, 특히 DellEMC Ready Solution for HPC PixStor Storage의 일부입니다. 여기서 NVMe 드라이브가 탑재된 DellEMC PowerEdge R640 서버는 고속 플래시 기반 계층으로 사용됩니다.
PixStor PFS 솔루션에는 Spectrum Scale이라고도 하는 광범위한 일반 병렬 파일 시스템이 포함되어 있습니다. ArcaStream에는 고급 분석, 간소화된 관리 및 모니터링, 효율적인 파일 검색, 고급 게이트웨이 기능 등을 제공하는 여러 소프트웨어 구성 요소도 포함되어 있습니다.
이 블로그에서 소개하는 NVMe 노드는 PixStor 솔루션의 고성능 플래시 기반 계층을 제공합니다. 이 NVMe 계층의 성능과 용량은 추가 NVMe 노드를 통해 확장할 수 있습니다. PowerEdge R640에서 지원되는 적절한 NVMe 디바이스를 선택하여 용량을 늘릴 수 있습니다.
그림 1은 테스트한 구성에서 모든 메타데이터를 처리하는 High Demand Metadata 모듈을 사용하는 4개의 NVMe 노드를 갖춘 솔루션의 레퍼런스 아키텍처를 보여줍니다. 현재 이러한 NVMe 노드가 데이터 전용 스토리지 타겟으로 사용되었기 때문입니다. 하지만 NVMe 노드는 데이터와 메타데이터를 저장하는 데 사용할 수도 있고, 극단적인 메타데이터 수요가 발생하는 경우 High Demand Metadata 모듈에 대한 더욱 빠른 플래시 대안으로 사용할 수도 있습니다. NVMe 노드에 대한 구성은 이 연구의 일부분으로 테스트되지 않았지만 향후 테스트가 실시될 예정입니다.
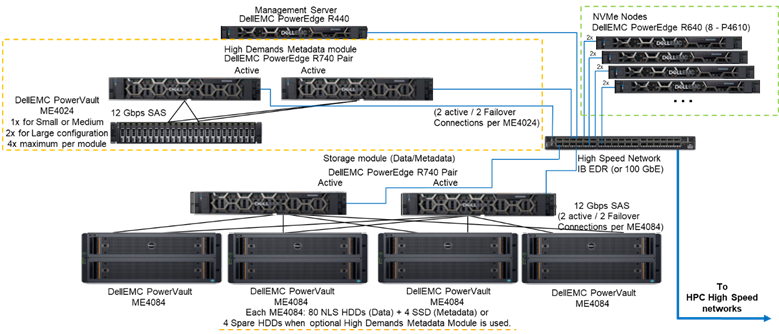
그림 1 레퍼런스 아키텍처
솔루션 구성 요소
이 솔루션은 최신 인텔 제온 2세대 스케일러블 제온 CPU(Cascade Lake CPU)와 사용 가능한 가장 빠른 RAM(2933MT/s)을 사용합니다. 단, 비용 효율성 유지를 위한 관리 노드는 제외됩니다. 추가로 이 솔루션은 릴리스 시점에서 지원되는 소프트웨어 버전인 RHEL 7.7 및 OFED 5.0을 지원하는 최신 버전의 PixStor(5.1.3.1)로 업데이트되었습니다.
각 NVMe 노드에는 서버 쌍에 걸쳐 8개의 RAID 10 디바이스로 구성된 8개의 Dell P4610 디바이스가 있고, NVMe over Fabric 솔루션을 사용하여 디바이스 수준뿐만 아니라 서버 수준에서도 데이터 중복성을 허용합니다. 게다가 이러한 RAID10 디바이스 중 하나에 데이터가 들어가거나 나갈 때 두 서버의 16개 드라이브가 모두 사용되므로, 모든 드라이브에 대한 액세스 대역폭이 증가합니다. 따라서 이러한 구성 요소에 대한 유일한 제한 사항은 쌍으로 판매 및 사용해야 한다는 것입니다. PowerEdge R640에서 지원하는 모든 NVMe 드라이브를 이 솔루션에서 사용할 수 있지만 P4610은 읽기 및 쓰기 모두에 대해 3,200MB/s의 순차적 대역폭과 높은 랜덤 IOPS 사양을 갖추고 있습니다. 덕분에 이 플래시 계층의 요구 사항을 충족하는 데 필요한 쌍의 수를 추정할 때 유용합니다.
각 R640 서버에는 EDR 100Gb IB 연결로 사용되는 2개의 HCA Mellanox ConnectX-6 싱글 포트 VPI HDR100이 있습니다. 하지만 NVMe 노드는 HDR 케이블 및 스위치와 함께 사용할 경우 HDR100 속도를 지원할 수 있습니다. 이러한 노드에서 HDR100 테스트는 전체 PixStor 솔루션에 대한 HDR100 업데이트의 일부로 연기됩니다. 두 CX6 인터페이스 모두 RAID 10(NVMe over Fabric)의 데이터를 동기화하고 파일 시스템의 연결로 사용됩니다. 또한 어댑터, 포트 및 케이블에서 하드웨어 중복성을 제공합니다. 스위치 수준에서의 중복성을 위해 듀얼 포트 CX6 VPI 어댑터가 필요하지만 S&P 구성 요소로 구매해야 합니다.
NVMe 노드의 성능을 특성화하기 위해 그림 1에 나와 있는 시스템에서 High Demand Metadata 모듈과 NVMe 노드만 사용되었습니다.
표 1에는 솔루션의 주요 구성 요소 목록이 나와 있습니다. ME4024에서 지원되는 드라이브 목록에서 메타데이터에 960GB SSD가 사용되었으며 성능 특성화에 사용되었습니다. 더 빠른 드라이브를 사용할 경우, 더 나은 랜덤 IOPS를 제공하고 메타데이터 생성/제거 작업을 개선할 수 있습니다. PowerEdge R640에서 지원되는 모든 NVMe 디바이스는 NVMe 노드에서 지원됩니다.
표 1 릴리스 시점에 사용된 구성 요소 및 테스트 베드에서 사용된 구성 요소
|
릴리스 시점 |
||
|
내부 연결 |
Dell Networking S3048-ON 기가비트 이더넷 |
|
|
데이터 스토리지 서브시스템 |
Dell EMC PowerVault ME4084 1~4개 Dell EMC PowerVault ME484 1~4개(ME4084당 1개) |
|
|
High Demand Metadata 스토리지 서브시스템(옵션) |
Dell EMC PowerVault ME4024 1~2개(필요한 경우 ME4024 4개, 대규모 구성만 해당) |
|
|
RAID 스토리지 컨트롤러 |
12Gbps SAS |
|
|
프로세서 |
NVMe 노드 |
인텔 제온 Gold 6230 2.1G 2개, 20C/40T |
|
High Demand Metadata |
||
|
스토리지 노드 |
||
|
관리 노드 |
인텔 제온 Gold 5220 2.2G 2개, 18C/36T |
|
|
메모리 |
NVMe 노드 |
16GiB 2933MT/s RDIMM 12개(192GiB) |
|
High Demand Metadata |
||
|
스토리지 노드 |
||
|
관리 노드 |
16GB DIMM 12개, 2666MT/s(192GiB) |
|
|
운영 체제 |
CentOS 7.7 |
|
|
커널 버전 |
3.10.0-1062.12.1.el7.x86_64 |
|
|
PixStor 소프트웨어 |
5.1.3.1 |
|
|
파일 시스템 소프트웨어 |
Spectrum Scale(GPFS) 5.0.4-3(NVMesh 2.0.1) |
|
|
고성능 네트워크 연결 |
NVMe 노드: ConnectX-6 InfiniBand 2개(EDR/100GbE 사용) |
|
|
HPS(High Performance Switch) |
Mellanox SB7800 2개 |
|
|
OFED 버전 |
Mellanox OFED 5.0-2.1.8.0 |
|
|
로컬 디스크(OS 및 분석/모니터링) |
나열된 서버를 제외한 모든 서버 NVMe 노드 480GB SSD SAS3(RAID1 + HS) 3개(OS용) 480GB SSD SAS3(RAID1 + HS) 3개(OS용) PERC H730P RAID 컨트롤러 PERC H740P RAID 컨트롤러 관리 노드 PERC H740P RAID 컨트롤러가 있는 480GB SSD SAS3(RAID1 + HS) 3개(OS용) |
|
|
시스템 관리 |
iDRAC 9 Enterprise + DellEMC OpenManage |
|
성능 특성화
새로운 Ready Solution 구성 요소의 특성을 분석하기 위해 다음 벤치마크가 사용되었습니다.
· IOzone N-N 순차적
· IOR N-1 순차적
IOzone 랜덤 MDtest
위에 나열된 모든 벤치마크에서 테스트 베드에는 아래 표 2 에 설명된 클라이언트가 포함되어 있습니다. 테스트에 사용할 수 있는 컴퓨팅 노드 수가 16개에 불과하기 때문에 더 많은 수의 스레드가 필요할 경우 해당 스레드는 컴퓨팅 노드에 균등하게 분산되었습니다(예: 32개 스레드 = 노드당 2개 스레드, 64개 스레드 = 노드당 4개 스레드, 128개 스레드 = 노드당 8개 스레드, 256개 스레드 = 노드당 16개 스레드, 512개 스레드 = 노드당 32개 스레드, 1024개 스레드 = 노드당 64개 스레드). 목적은 제한된 수의 가능한 컴퓨팅 노드로 더 많은 수의 동시 클라이언트를 시뮬레이션하는 것이었습니다. 벤치마크에서 많은 수의 스레드를 지원하므로 성능 결과에 영향을 미치는 과도한 컨텍스트 전환 및 기타 관련 부작용을 방지하면서 최대 1,024 값을 사용했습니다(각 테스트에 대해 지정).
표2 클라이언트 테스트 베드
|
클라이언트 노드 수 |
16 |
|
클라이언트 노드 |
C6320 |
|
클라이언트 노드당 프로세서 수 |
인텔(R) 제온(R) Gold E5-2697v4(2.30GHz에서 18코어) 2개 |
|
클라이언트 노드당 메모리 |
16GiB 2400MT/s RDIMM 8개(128GiB) |
|
BIOS |
2.8.0 |
|
OS 커널 |
3.10.0-957.10.1 |
|
파일 시스템 소프트웨어 |
Spectrum Scale(GPFS) 5.0.4-3(NVMesh 2.0.1) |
순차적 IOzone 성능 N 클라이언트-N 파일
IOzone 버전 3.487을 사용하여 순차적 N 클라이언트-N 파일 성능을 측정했습니다. 단일 스레드에서 최대 1,024개의 스레드까지 2의 거듭제곱 단위로 테스트가 실시되었습니다.
조정 가능한 GPFS 페이지 풀을 16GiB로 설정하고 2배 더 큰 크기의 파일을 사용하여 서버의 캐싱 효과를 최소화했습니다. GPFS의 경우 조정 가능한 페이지 풀이 설치되고 사용 가능한 RAM의 양에 관계없이 데이터 캐싱에 사용되는 최대 메모리 양을 설정한다는 점에 유의해야 합니다. 또한 이전 DellEMC HPC 솔루션에서 대규모 순차 전송의 블록 크기는 1MiB이지만 GPFS는 8MiB 블록으로 포맷되었으므로 이 값이 최적의 성능을 위해 벤치마크에 사용된다는 점에도 주의해야 합니다. 너무 커서 너무 많은 공간을 낭비하는 것처럼 보일 수 있지만 GPFS는 하위 블록 할당을 사용하여 이러한 상황을 방지합니다. 현재 구성에서 각 블록은 각각 32KiB의 하위 블록 256개로 분할되었습니다.
쓰기 및 읽기 벤치마크를 실행하는 데 다음 명령이 사용되었습니다. 여기서 $Threads는 사용된 스레드 수가 포함된 변수입니다(1부터 1,024까지 2의 거듭제곱으로 증가). threadlist는 라운드 로빈을 사용하여 16개의 컴퓨팅 노드에 균일하게 분산시키는 방식으로 각 스레드를 다른 노드에 할당한 파일입니다.
클라이언트에서의 데이터 캐싱 효과를 방지하기 위해 파일의 총 데이터 크기는 사용된 클라이언트의 총 RAM 용량의 2배였습니다. 즉, 각 클라이언트에는 128GiB의 RAM이 있으므로 스레드 수가 16개 이상인 경우 파일 크기는 4,096GiB를 스레드 수로 나눈 값입니다(이 변수를 관리하기 위해 $Size보다 작은 변수가 사용됨). 스레드가 16개 미만인 경우(즉, 각 스레드가 다른 클라이언트에서 실행되고 있었음을 의미) 파일 크기는 클라이언트당 메모리 용량의 2배인 256GiB로 고정되었습니다.
iozone -i0 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
iozone -i1 -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./threadlist
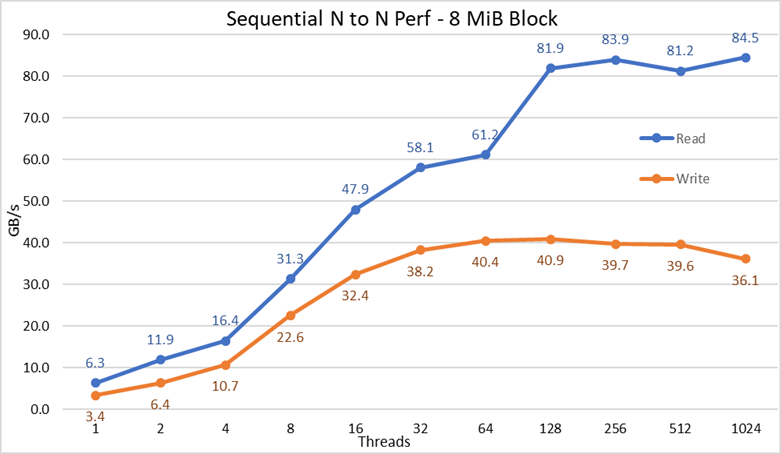
그림 2 N-N 순차적 성능
결과를 통해 사용된 스레드 수에 따라 쓰기 성능이 상승하고 쓰기의 경우 약 64개 스레드, 읽기의 경우 128개 스레드에서 정체기에 도달하는 것을 확인할 수 있습니다. 이후 읽기 성능은 스레드 수에 따라 빠르게 상승하고, IOzone에서 허용하는 최대 스레드 수에 도달할 때까지 안정적으로 유지되므로 1,024개의 동시 클라이언트에서도 대용량 파일 순차적 성능이 안정적입니다. 쓰기 성능은 1,024개 스레드에서 약 10% 떨어집니다. 그러나 클라이언트 클러스터의 코어 수가 그보다 적기 때문에, 성능 저하가 NVMe의 매우 낮은 지연 시간으로 인해 회전식 미디어에서는 나타나지 않는 스왑이나 기타 오버헤드 때문인지, 아니면 RAID 10 데이터 동기화 과정이 병목 현상으로 작용하고 있는 것인지는 명확하지 않습니다. 이 점을 명확히 하려면 더 많은 클라이언트가 필요합니다. 64개 스레드에서 읽기 이상 징후가 관찰되었는데,이전 데이터 포인트에서 관찰된 속도로 성능이 확장되지 않았다가 다음 데이터 포인트에서 지속적인 성능에 매우 가까운 값으로 이동합니다. 이러한 이상 징후의 원인을 찾으려면 더 많은 테스트가 필요하지만 이 블로그의 범위에는 포함되지 않습니다.
NVMe over Fabric 트래픽(4개의 EDR BW, 최대 96GB/s)에 주로 사용되는 링크 중 하나라고 가정하더라도 최대 읽기 성능은 NVMe 디바이스의 이론적 성능(최대 102GB/s) 또는 EDR 링크의 성능보다 낮았습니다.
하지만 하드웨어 구성이 각 CPU 소켓 아래의 NVMe 디바이스 및 IB HCA와 간의 균형을 이루지 못했기 때문에 이는 당연합니다. 1개의 CX6 어댑터가 CPU1에 있고 CPU2에는 모든 NVMe 디바이스와 두 번째 CX6 어댑터가 있습니다. 첫 번째 HCA를 사용하는 모든 스토리지 트래픽은 UPI를 사용하여 NVMe 디바이스에 액세스해야 합니다. 또한 사용된 CPU1의 모든 코어는 CPU2에 할당된 디바이스 또는 메모리에 액세스해야 하므로 데이터 인접성이 저하되고, UPI 링크가 사용됩니다. 이를 통해 NVMe 디바이스의 최대 성능 또는 CX6 HCA의 회선 속도에 비해 최대 성능이 감소하는 것을 설명할 수 있습니다. 이러한 한계를 해결하기 위한 대안은 하드웨어 구성을 균형 있게 조정하는 것입니다. 이를 위해서는 서버 밀도를 절반으로 줄이고, 4개의 x16 슬롯을 가진 R740 시스템을 사용하여 2개의 x16 PCIe 확장기를 통해 NVMe 디바이스를 두 CPU에 균등하게 분배하고, 각 CPU 아래에 CX6 HCA를 하나씩 배치해야 합니다.
순차적 IOR 성능 N 클라이언트-1 파일
단일 공유 파일에 대한 순차적 N 클라이언트의 성능은 16개의 컴퓨팅 노드에서 벤치마크를 실행하기 위해 OpenMPI v4.0.1의 지원을 받아 IOR 버전 3.3.0으로 측정되었습니다. 1개부터 512개까지 다양한 스레드에서 테스트를 실시했습니다. 1,024개 이상의 스레드를 실행할 수 있는 코어가 충분하지 않았기 때문입니다. 이 벤치마크 테스트에서는 최적의 성능을 위해 8MiB 블록을 사용했습니다. 이전 성능 테스트 섹션에서 이 점이 중요한 이유를 자세히 설명합니다.
데이터 캐싱 효과를 최소화하기 위해 조정 가능한 GPFS 페이지 풀을 16GiB로 설정했으며 총 파일 크기는 클라이언트의 전체 RAM 용량의 2배로 구성했습니다. 즉, 각 클라이언트에는 128GiB의 RAM이 있으므로 스레드 수가 16개 이상인 경우 파일 크기가 4,096GiB였고, 이 합계와 동일한 양을 스레드 수로 나누었습니다(이 변수를 관리하기 위해 $Size보다 작은 변수가 사용됨). 스레드가 16개 미만인 경우(즉, 각 스레드가 다른 클라이언트에서 실행되고 있었음을 의미) 파일 크기는 클라이언트당 사용된 메모리 크기와 스레드 수의 2배가 되었습니다. 다시 말해 각 스레드에 256GiB를 사용하도록 요청되었습니다.
쓰기 및 읽기 벤치마크를 실행하는 데 다음 명령이 사용되었습니다. 여기서 $Threads는 사용된 스레드 수가 포함된 변수입니다(1부터 1,024까지 2의 거듭제곱으로 증가). my_hosts.$Threads는 라운드 로빈을 사용하여 16개의 컴퓨팅 노드에 균일하게 분산시키는 방식으로 각 스레드를 다른 노드에 할당한 파일입니다.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -w -s 1 -t 8m -b $ G
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --mca btl_openib_allow_ib 1 --mca pml ^ucx --oversubscribe --prefix /mmfs1/perftest/ompi /mmfs1/perftest/lanl_ior/bin/ior -a POSIX -v -i 1 -d 3 -e -k -o /mmfs1/perftest/tst.file -r -s 1 -t 8m -b $ G
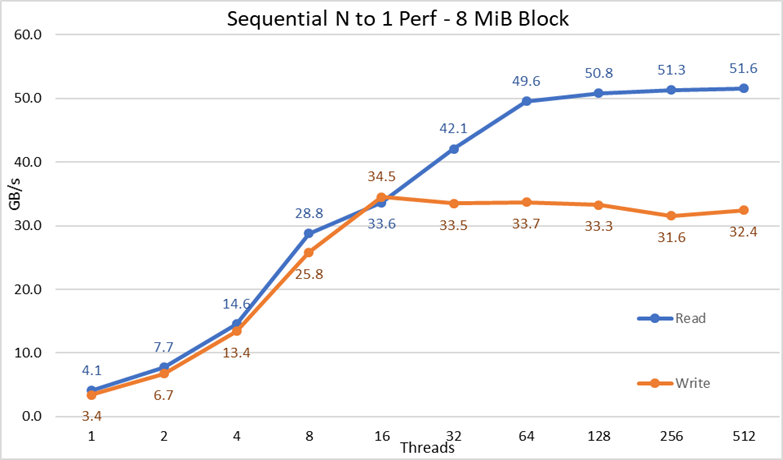
그림 3 N-1 순차적 성능
결과에 따르면 모든 스레드가 동일한 파일에 액세스하기 때문에 암묵적인 잠금 메커니즘의 필요성과 무관하게 읽기 및 쓰기 성능이 높은 것을 확인할 수 있습니다. 사용된 스레드 수에 따라 성능이 매우 빠르게 다시 상승한 다음 이 테스트에 사용된 최대 스레드 수에 이르기까지 읽기 및 쓰기에 대해 상당히 안정적인 정체기에 도달합니다. 최대 읽기 성능은 512개 스레드에서 51.6GB/s였지만 성능 정체는 약 64개 스레드에서 도달했습니다. 마찬가지로 16개 스레드에서 34.5GB/s의 최대 쓰기 성능을 달성했으며 최대 스레드 수가 사용될 때까지 정체기에 도달한 것을 관찰할 수 있었습니다.
랜덤 작은 블록 IOzone 성능 N 클라이언트-N 파일
IOzone 버전 3.487을 사용하여 랜덤 N 클라이언트-N 파일 성능을 측정했습니다. 단일 스레드에서 최대 1,024개의 스레드까지 2의 거듭제곱 단위로 테스트가 실시되었습니다.
1개부터 512개까지 다양한 스레드에서 테스트를 실시했습니다. 1,024개 이상의 스레드를 실행할 수 있는 클라이언트 코어가 충분하지 않았기 때문입니다. 각 스레드는 서로 다른 파일을 사용하고 있으며 클라이언트 노드에서 스레드가 라운드 로빈으로 할당되었습니다. 이 벤치마크 테스트에서는 작은 블록 트래픽을 에뮬레이션하고 대기열 깊이 16을 사용하는 데 4KiB 블록을 사용했습니다. 대규모 솔루션과 용량 확장의 결과를 비교합니다.
데이터 캐싱 효과를 최소화하기 위해 조정 가능한 GPFS 페이지 풀을 16GiB로 설정했으며 클라이언트 측에서의 데이터 캐싱 효과를 방지하기 위해, 파일의 총 데이터 크기를 클라이언트 전체 파일의 총 데이터 크기를 클라이언트 전체 RAM 용량의 2배로 설정했습니다. 즉, 각 클라이언트에는 128GiB의 RAM이 있으므로 스레드 수가 16개 이상인 경우 파일 크기는 4,096GiB를 스레드 수로 나눈 값입니다(이 변수를 관리하기 위해 $Size보다 작은 변수가 사용됨). 스레드가 16개 미만인 경우(즉, 각 스레드가 다른 클라이언트에서 실행되고 있었음을 의미) 파일 크기는 클라이언트당 메모리 용량의 2배인 256GiB로 고정되었습니다.
iozone -i0 -I -c -e -w -r 8M -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Create the files sequentially
iozone -i2 -I -c -O -w -r 4k -s $ G -t $Threads -+n -+m ./nvme_threadlist <= Perform the random reads and writes.
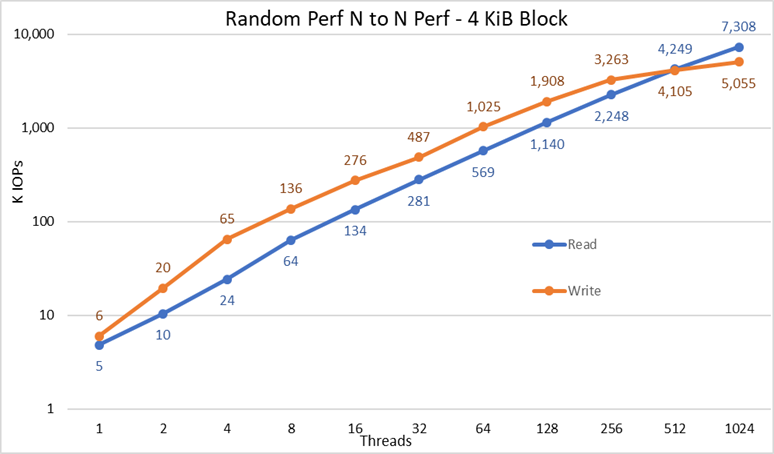
그림 4 N-N 랜덤 성능
결과에 따르면 쓰기 성능은 6K IOPS의 높은 값에서 시작하여 최대 1,024개 스레드까지 꾸준히 증가하며, 더 많은 스레드를 사용할 수 있는 경우 5M IOPS 이상에서 정체기에 도달하는 것을 관찰할 수 있습니다. 반면에 읽기 성능은 5K IOPS에서 시작하여 사용되는 스레드 수에 따라 꾸준하게 성능이 증가합니다. 각 데이터 요소마다 스레드 수가 두 배로 증가한다는 점에 유의하십시오. 1,024개의 스레드에서 최대 7.3M IOPS에 도달해도 정체기에 이르는 징후는 나타나지 않았습니다. 스레드를 더 많이 사용하려면 리소스 부족과 과도한 스와핑으로 인한 성능 저하를 방지하기 위해 16개 이상의 컴퓨팅 노드가 필요하지만 이 경우 NVMe 노드는 실제로 성능을 유지할 수 있습니다.
4KiB 파일을 사용한 MDtest의 메타데이터 성능
메타데이터 성능은 16개의 컴퓨팅 노드에서 벤치마크를 실행하기 위해 OpenMPI v4.0.1의 지원을 받아 Mdtest 버전 3.3.0으로 측정되었습니다. 단일 스레드부터 최대 512개 스레드까지 다양한 테스트가 실행되었습니다. 벤치마크는 파일에만 사용되었고(디렉토리 메타데이터 없음), 솔루션이 처리할 수 있는 생성, 통계, 읽기 및 제거 수를 구했으며, 결과를 대규모 솔루션과 대조했습니다.
선택 사항인 High Demand Metadata 모듈이 사용되었지만, 단일 ME4024 어레이에서 이 연구에서 대규모 구성과 테스트를 거친 경우에도 ME4024가 2개 있는 것으로 지정되었습니다. 해당 Metadata 모듈을 사용하는 이유는 현재 이러한 NVMe 노드가 데이터 전용 스토리지 타겟으로 사용되기 때문입니다. 하지만 노드는 데이터와 메타데이터를 저장하는 데 사용할 수도 있고, 극단적인 메타데이터 수요가 발생하는 경우 High Demand Metadata 모듈에 대한 플래시 대안으로 사용할 수도 있습니다. 이러한 구성은 이 연구에서는 테스트되지 않았습니다.
DellEMC Ready Solution for HPC PixStor Storage 솔루션의 이전 벤치마킹에 동일한 High Demand Metadata 모듈이 사용되었기 때문에 메타데이터 결과는 이전 블로그의 결과와 매우 유사합니다. 그런 이유로 빈 파일로 실험하지 않았고, 대신 4KiB 파일을 사용했습니다. 4KiB 파일은 메타데이터 정보와 함께 inode에 들어갈 수 없으므로 NVMe 노드는 각 파일의 데이터를 저장하는 데 사용됩니다. 따라서 MDtest는 읽기 및 나머지 메타데이터 작업에 대한 낮은 파일 성능과 관련된 대략적인 아이디어를 제공할 수 있습니다.
벤치마크를 실행하는 데 다음 명령이 사용되었습니다. 여기서 $Threads는 사용된 스레드 수가 포함된 변수입니다(1부터 512까지 2의 거듭제곱으로 증가). my_hosts.$Threads is the corresponding file 는 라운드 로빈을 사용하여 16개의 컴퓨팅 노드에 균일하게 분산시키는 방식으로 각 스레드를 다른 노드에 할당한 해당 파일입니다. 랜덤 IO 벤치마크와 마찬가지로 최대 스레드 수는 512개로 제한되었는데, 1024개 스레드를 위한 코어가 충분하지 않고 컨텍스트 전환이 결과에 영향을 미쳐 솔루션의 실제 성능보다 낮은 수치를 보고하기 때문입니다.
mpirun --allow-run-as-root -np $Threads --hostfile my_hosts.$Threads --prefix /mmfs1/perftest/ompi --mca btl_openib_allow_ib 1 /mmfs1/perftest/lanl_ior/bin/mdtest -v -d /mmfs1/perftest/ -i 1 -b $Directories -z 1 -L -I 1024 -y -u -t -F -w 4K -e 4K
성능 결과는 총 IOPS 수, 디렉토리당 파일 수 및 스레드 수에 의해 영향을 받을 수 있으므로 총 파일 수를 2MiB 파일(2^21 = 2097152)로 고정하고 디렉토리당 파일 수는 1,024개로 고정하기로 했습니다. 디렉토리 수는 표 3과 같이 스레드 수의 변경에 따라 달라집니다.표 3:
표3 MDtest 디렉토리의 파일 배포
|
스레드 수 |
스레드당 디렉토리 수 |
총 파일 수 |
|
1 |
2048 |
2,097,152 |
|
2 |
1024 |
2,097,152 |
|
4 |
512 |
2,097,152 |
|
8 |
256 |
2,097,152 |
|
16 |
128 |
2,097,152 |
|
32 |
64 |
2,097,152 |
|
64 |
32 |
2,097,152 |
|
128 |
16 |
2,097,152 |
|
256 |
8 |
2,097,152 |
|
512 |
4 |
2,097,152 |
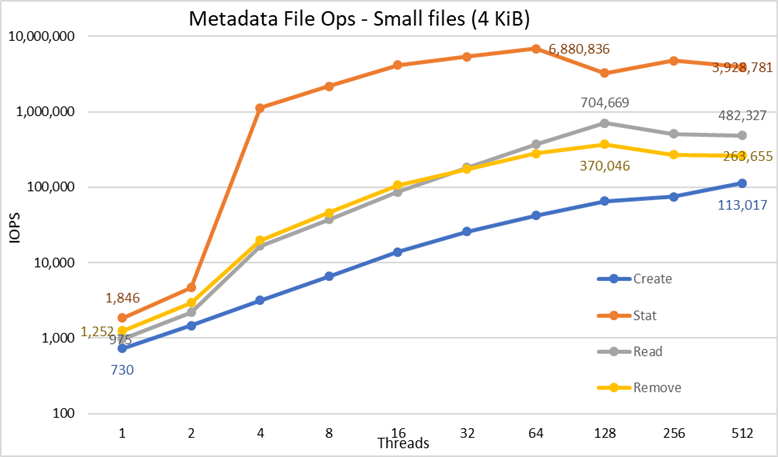
그림 5 메타데이터 성능 - 4KiB 파일
먼저 자릿수의 차이가 있는 연산을 비교하도록 하기 위해 밑이 10인 로그를 척도로 선택한 것을 알 수 있습니다. 그렇지 않으면 일부 연산은 선형 스케일에서 0에 가까운 평행선처럼 보일 것입니다. 밑이 2인 로그 그래프는 스레드 수가 2의 거듭제곱으로 증가하기 때문에 더 적절할 수 있지만 그래프는 매우 비슷하게 보이고 사람들은 10의 거듭제곱에 따라 더 나은 숫자를 처리하고 기억하는 경향이 있습니다.
이 시스템은 이전에 보고된 바와 같이 매우 우수한 결과를 보였습니다. Stat 연산은 64개의 스레드에서 약 690만 op/s의 최대값에 도달했으며, 그 이후 스레드 수가 증가함에 따라 성능이 점차 감소하다가 정체기에 이르렀습니다. 생성 작업은 512개 스레드에서 최대 113K op/s에 도달하므로 더 많은 클라이언트 노드(및 코어)를 사용하는 경우 계속 증가할 것으로 예상됩니다. 읽기 및 제거 작업은 128개 스레드에서 최대값을 달성하여 읽기의 경우 거의 705K op/s, 제거의 경우 370K op/s에서 최대를 달성한 후 정체기에 도달했습니다. 통계 작업은 가변성이 더 높지만, 최고 값에 도달하면 통계의 경우 3.2M op/s 아래로 성능이 떨어지지 않습니다. 생성 및 제거는 정체기에 도달하면 더욱 안정적인 상태가 되며, 제거의 경우 265K op/s, 생성의 경우 113K op/s 이상으로 유지됩니다. 마지막으로 읽기는 265K op/s 이상의 성능에서 정체기에 도달합니다.
결론 및 향후 작업
NVMe 노드는 HPC 스토리지 솔루션에 매우 중요한 확장 요소로, 높은 집적도와 함께 탁월한 랜덤 액세스 성능 및 매우 높은 순차적 성능을 제공하는 고성능 계층을 구현합니다. 추가로 NVMe 노드 모듈이 더 추가됨에 따라 용량과 성능이 선형적으로 확장됩니다. NVMe 노드의 성능은 표 4에서 간략하게 확인할 수 있고, 안정적일 것으로 예상되며, 이러한 값을 사용하여 NVMe 노드 수가 다를 때의 성능을 추정할 수 있습니다.
그러나 각 NVMe 노드 쌍은 표 4에 표시된 모든 수의 절반을 제공한다는 점에 유의하십시오.
이 솔루션은 HPC 고객에게 다수의 상위 500개 HPC 클러스터에서 사용되는 매우 안정적인 병렬 파일 시스템을 제공합니다. 또한 탁월한 검색 기능, 고급 모니터링 및 관리 기능을 제공하며, NFS, SMB 등의 유비쿼터스 표준 프로토콜을 통해 필요한 만큼 많은 클라이언트에 파일을 공유할 수 있는 게이트웨이 옵션을 추가할 수 있습니다.
표 4 2쌍의 NVMe 노드에 대한 최고 성능 및 지속 성능
|
|
최고 성능 |
지속적인 성능 |
||
|
쓰기 |
읽기 |
쓰기 |
읽기 |
|
|
대규모 순차적 N 클라이언트-N 파일 |
40.9GB/s |
84.5GB/s |
40GB/s |
81GB/s |
|
대규모 순차적 N 클라이언트-단일 공유 파일 |
34.5GB/s |
51.6GB/s |
31.5GB/s |
50GB/s |
|
랜덤 작은 블록 N 클라이언트-N 파일 |
5.06M IOPS |
7.31M IOPS |
5M IOPS |
7.3M IOPS |
|
메타데이터 생성 4KiB 파일 |
113K IOPS |
113K IOPS |
||
|
메타데이터 통계 4KiB 파일 |
6.88M IOPS |
3.2M IOPS |
||
|
메타데이터 읽기 4KiB 파일 |
705K IOPS |
500 K IOPS |
||
|
메타데이터 제거 4KiB 파일 |
370K IOPS |
265K IOPS |
||
NVMe 노드는 데이터에만 사용되었기 때문에 향후 연구에는 데이터 및 메타데이터에 대한 사용이 포함될 수 있고, RAID 컨트롤러 뒤에 SAS3 SSD를 사용하는 것에 비해 NVMe 디바이스의 대역폭이 높고 레이턴시가 짧기 때문에 메타데이터 성능이 뛰어난 자체 포함 플래시 기반 계층을 사용할 수 있습니다. 또는 고객이 메타데이터 수요가 매우 높고 High Demand Metadata 모듈이 제공할 수 있는 것보다 더 높은 집적도의 솔루션을 필요로 하는 경우 ME4024의 RAID 1 디바이스가 사용되는 것과 동일한 방식으로 분산 RAID 10 디바이스의 일부 또는 전체를 메타데이터에 사용할 수 있습니다.
곧 출시될 또 다른 블로그에서는 PixStor Gateway 노드의 특징을 다룰 예정입니다. 이 노드들은 NFS 또는 SMB 프로토콜을 통해 PixStor 솔루션을 다른 네트워크와 연결할 수 있도록 하며, 성능 확장 또한 가능합니다. 또한 이 솔루션은 곧 HDR100으로 업데이트될 예정이며, 다른 블로그에서도 이에 대해 설명할 것입니다.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000130558
Article Type: Solution
Last Modified: 21 Feb 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.