VMware ESXi 上的英特尔芯片上群集 (COD) 技术
Summary: Intel Cluster on Die, COD, VMware ESXi, 每个处理器插槽多个 NUMA 节点,
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
简介
在启用 NUMA 的系统中,内存通道分布在各个处理器上。所有与内存相关的操作都需要 snoop 操作,以保持高速缓存数据的一致性。侦听用于探测本地和远程处理器上的高速缓存内容,以查找所请求数据的副本驻留在任何高速缓存中。 如果禁用了 NUMA(在 BIOS 中启用了节点交叉存取),则将自动禁用侦听模式。
英特尔 Haswell 微体系结构中提供三种类型的侦听模式。戴尔第 13代服务器 (13G) 支持所有三种监控模式,例如:
1) 早期窥探
2) 家庭监听
3) 芯片上群集
在此博客中,我们将从 VMware ESXi 的角度讨论芯片上群集 (COD) 侦听模式。本博客涵盖以下几个方面。
- COD的基础知识
- 从硬件和 VMware ESXi 的角度启用 COD 的前提条件
- ESXi 中几乎没有命令行选项,显示了启用和禁用 COD 时 NUMA 列表的差异。
在深入了解 COD 的详细信息之前,需要根据英特尔 Haswell 处理器微体系结构上的核心数量了解处理器类型。
英特尔将 Haswell 处理器体系结构分为以下几种类型:
1) LCC — 核心数量少 [4 -8 个核心]
2) MCC - 中等核心数量 [10 – 12 个核心]
3) HCC - 高核心数量 [14-18 核心]
提醒:此核心数量类型因不同的英特尔微体系结构而异。
什么是芯片上群集 (COD) 模式?
COD 是具有 10 个或更多核心的英特尔 Haswell 处理器系列引入的一种新的监听模式。对于 MCC 和 HCC 处理器类别,英特尔在单个处理器插槽上集成了两个内存控制器,而 LCC 处理器只有一个内存控制器。处理器插槽中的每个内存控制器都充当一个本地代理 [HA]。
在启用了 COD 的服务器上,每个处理器在逻辑上将套接字拆分为 2 个 NUMA 节点每个 NUMA 节点具有物理内核总数的一半和最后一级缓存 (LLC) 的一半,具有一个本地代理。术语群集是指处理器核心和相应的内存控制器分组在一起,并在插槽芯片上形成群集。每个本地代理使用两个内存通道,并看到来自较少数量的处理器逻辑内核的请求,从而提供更高的内存带宽和低延迟。此操作模式主要用于优化 NUMA 工作负载。操作系统通过读取 ACPI SRAT 表显示 NUMA 节点的数量。
COD的图形表示如下:
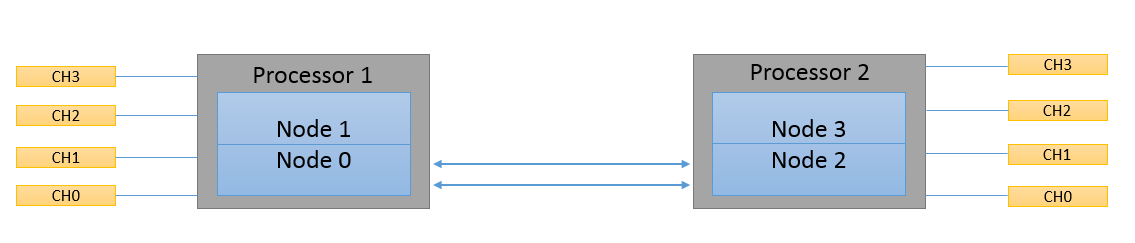
在第二张图像中可以看到,启用 COD 时,单处理器插槽芯片被划分为两个逻辑节点。
前提条件:
在本节中,我们将从硬件和 VMware ESXi 的角度讨论前提条件。
硬件:
- COD 只能在具有 10 个或更多核心的英特尔 Haswell-EP 处理器上启用。
- 内存需要填充在备用内存通道(CH0、CH2 & CH1 & CH3)上。例如,R730、R730xd、R630 和 T630 服务器的每个插槽有 4 个内存通道。
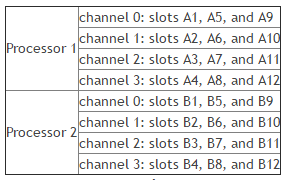
让我们举个例子来更好地理解上述先决条件。对于每个通道仅填充两个内存模块的服务器,需要为特定通道填充以下插槽
- A1 和 A3
带 4 个内存模块,
- A1、A3 和 B1、B3
带 8 个内存模块,
- A1、A3、B1、B3 和 A2、A4、B2、B4
提醒:至少需要填充两个内存模块才能启用 COD。
- 需要在 BIOS 设置中启用 Cluster On Die 令牌。
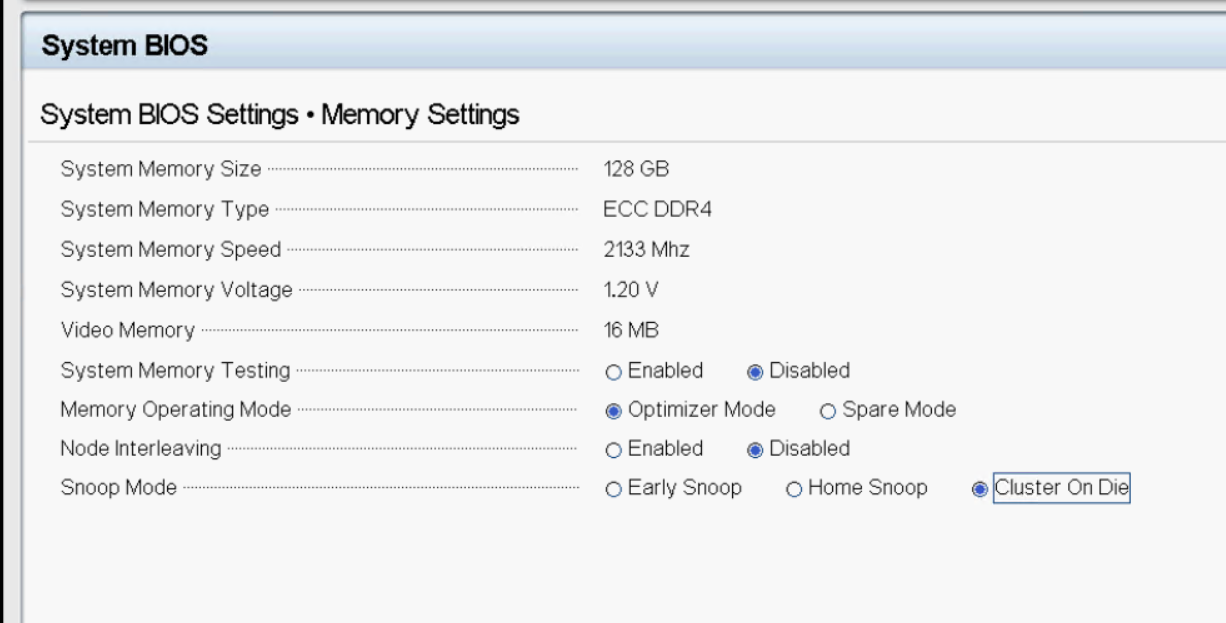
- VMware 对 COD 的支持最初是从 vSphere 6.0 开始的,现在在 ESXi 5.5 U3b 中也支持它。有关详细信息,请参阅 VMware 知识库2142499。
VMware ESXi 读取 ACPI SRAT(系统资源关联表)和 SLIT(系统位置信息表),以识别和映射可用的硬件资源。这还包括映射 NUMA 节点。本节讨论用户可以用来从 VMware ESXi 查看 COD 状态的几个命令行选项。
- esxtop 提供了一个选项来查看已填充的 NUMA 节点。输入 esxtop 命令后,按“m”可查看如下所示的 NUMA 节点详细信息。
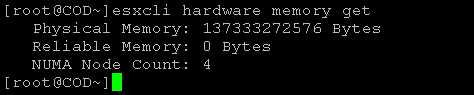
以下屏幕截图取自配备两个处理器插槽和 128 GB 系统内存的系统。在未启用 COD 的默认配置中,esxtop 将显示两个 NUMA 节点,每个 NUMA 节点分配 64 GB。下图显示了禁用 COD 的 VMware ESXi 中的 esxtop 命令输出。 
启用 COD 后,esxtop 会列出四个 NUMA 节点,而不是两个,因为单处理器插槽芯片一分为二。

esxcli 提供了几个命令行选项来显示从硬件公开的 NUMA 节点的数量。
优点
在 COD 模式下,操作系统会看到每个插槽有两个 NUMA 节点。COD 具有最佳的本地延迟。每个本地代理看到来自较少数量的线程的请求,这些线程可能提供更高的内存带宽。COD 模式具有内存目录位支持。此模式最适合高度 NUMA 优化的工作负载。请参阅戴尔 HPC 团队发布的博客,其中详细介绍了不同的侦听模式。
参考材料

Cause
不适用
Resolution
不适用
Article Properties
Article Number: 000147278
Article Type: Solution
Last Modified: 11 Dec 2024
Version: 8
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.