VMware: Průvodce odstraňováním problémů s fyzickým diskem vSAN
Summary: Toto je obecný průvodce odstraňováním problémů, který vám pomůže identifikovat, jestli dochází k problému s fyzickým diskem v clusterech vSAN.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Kontrola stavu fyzického disku vSAN z webového uživatelského rozhraní:
Připojte se k webovému klientovi vCenter Server a zkontrolujte stav disku v části:
Zásob > Hostitel a clustery > Cluster > vSAN Konfigurace > nástroje vSAN > Disk Management
Obrázek 1: Zobrazení
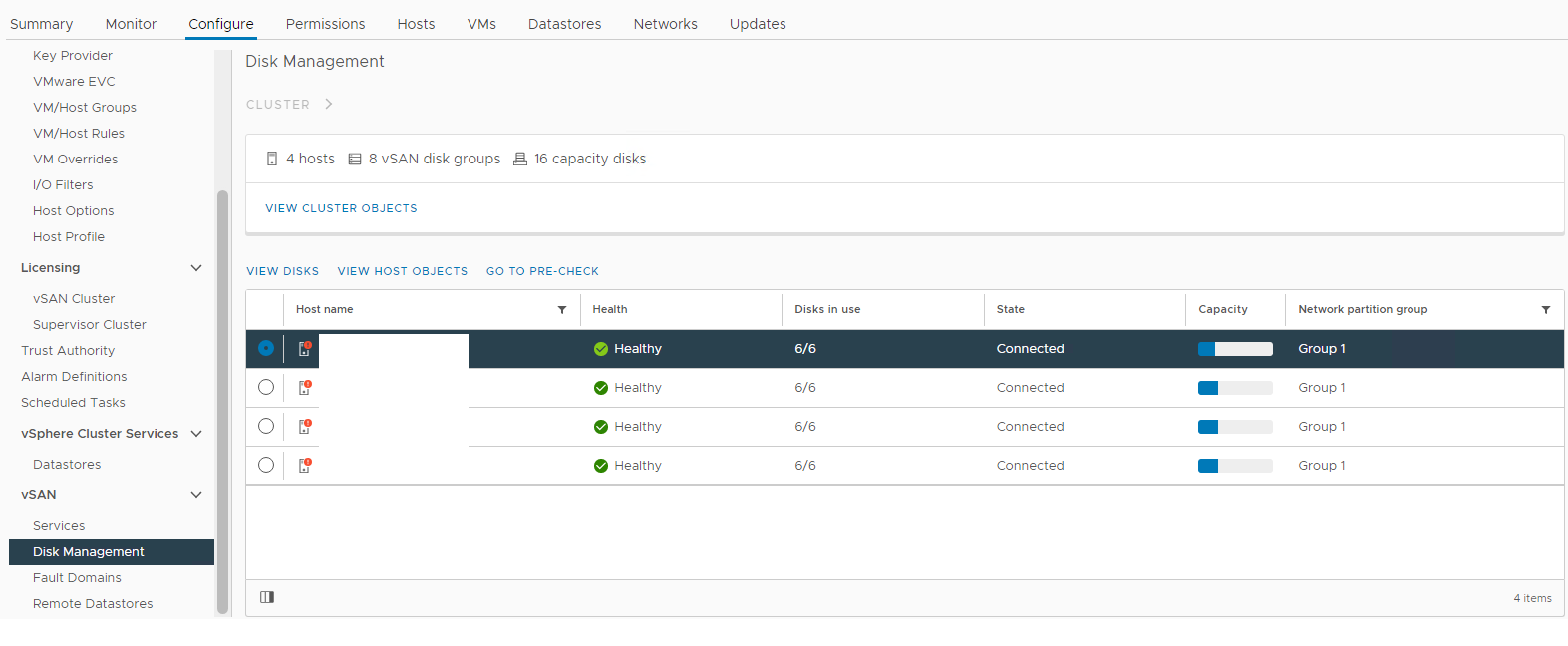 vSAN Disk Management Vyberte dotčeného hostitele a poté rozbalte část
vSAN Disk Management Vyberte dotčeného hostitele a poté rozbalte část
view disk: Obrázek 2: zobrazení
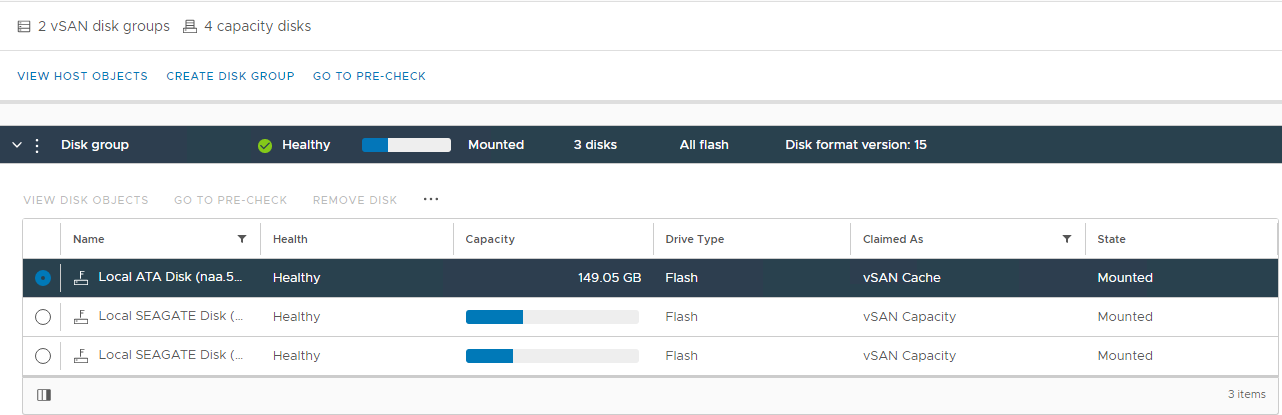
skupiny disků vSAN Zde můžete ověřit, zda je disk rozpoznán jako:
Není v pořádku Kapacita
není v pořádku
0 Trvalé selhání
disku Disk není připojen Disk
chyběl
Zkontrolujte také, zda se v části vSAN Skyline Health nespouštějí alarmy související s diskem:
Zásob > Hostitel a clustery > Monitor > clusteru > vSAN Fyzický disk vSAN > Skyline Health >Obrázek 3:
Pohled
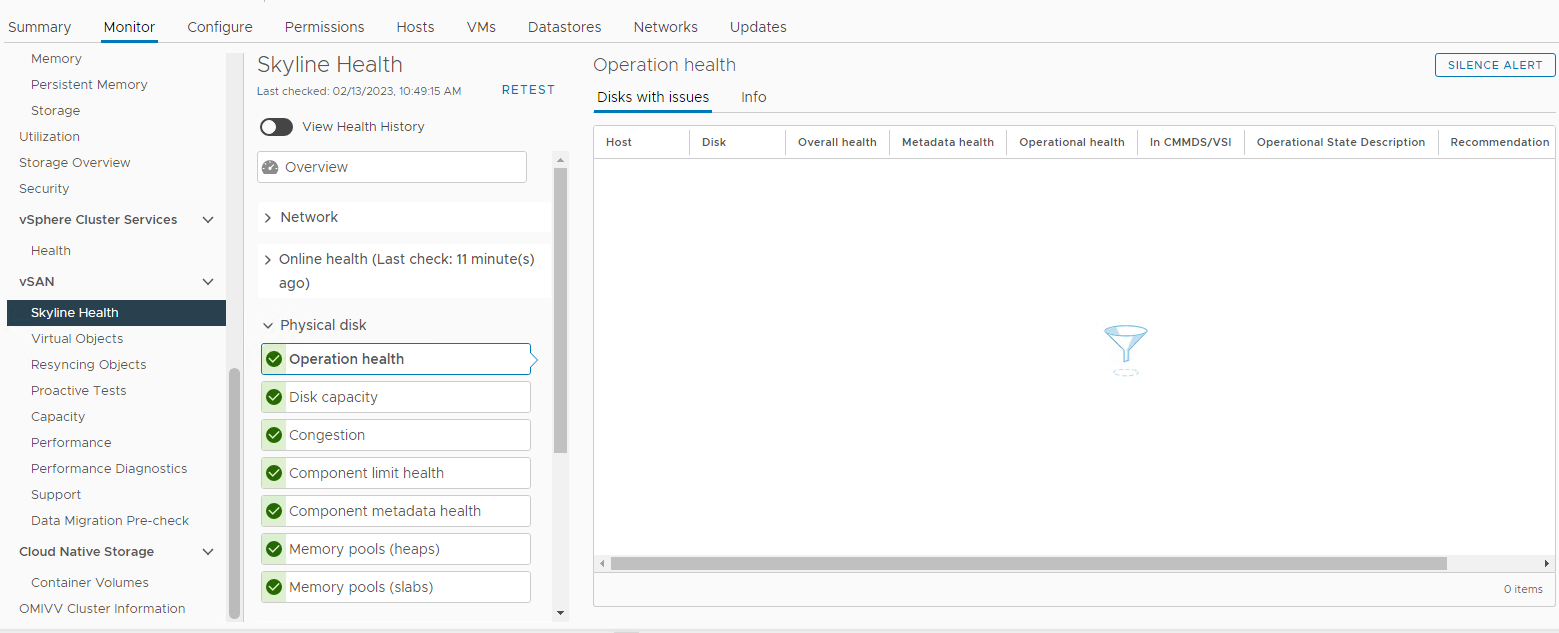
na Skyline Health Zde můžete ověřit, zda se spustil některý z následujících alarmů:
Impending permanent disk failure, data is being evacuated (Health state - Yellow).
Impending permanent disk failure, data evacuation failed due to insufficient resources (Health state - Red).
Impending permanent disk failure, data evacuation failed due to inaccessible objects (Health state - Red).
Impending permanent disk failure, data evacuation completed (Health state - Yellow)
Stav disku můžete také zkontrolovat ze seznamu úložných zařízení dotčeného hostitele:
Zásob > Hostitel a clustery > Dotčený cluster > vSAN Hostitel > ESXi vSAN Konfigurace > úložných > zařízení
Obrázek 4: Zobrazení
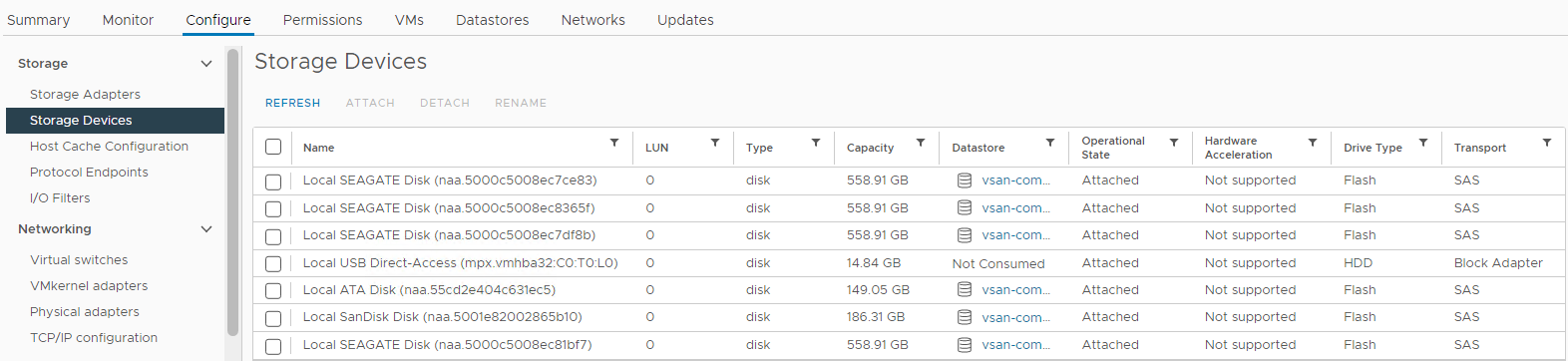
hostitelských úložných zařízení Zde můžete ověřit, zda je stav disku následující:
0 Capacity
Disk Absent
Disk Unmounted
Ověřte, zda dochází k opětovné synchronizaci:
Zásob > Hostitel a clustery > Monitor > clusteru > vSAN Objekty opětovné synchronizace vSAN>:
Obrázek 5: Opětovná synchronizace zobrazení objektů
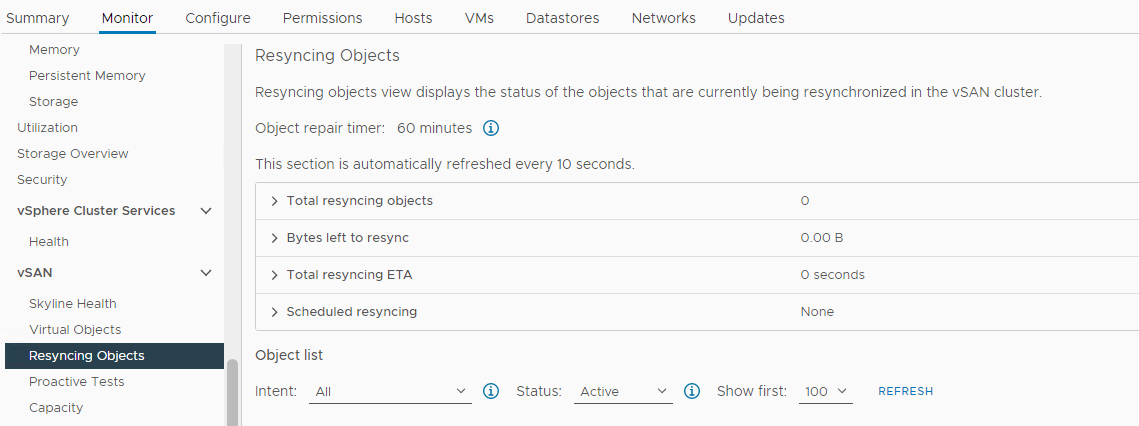
POZNÁMKA: Opakovaná synchronizace může znamenat, že jsou evakuována data z dotčeného disku nebo skupiny disků. Je zapotřebí dalšího šetření, aby bylo možné určit, zda je dotčený disk připraven k odebrání nebo výměně.
Ověřte stav objektů vSAN:
Zásob > Hostitel a clustery > Monitor > clusteru vSAN Data > stavu > vSAN > Skyline Stav >
objektu vSAN Obrázek 6: Zobrazení stavu objektu vSAN
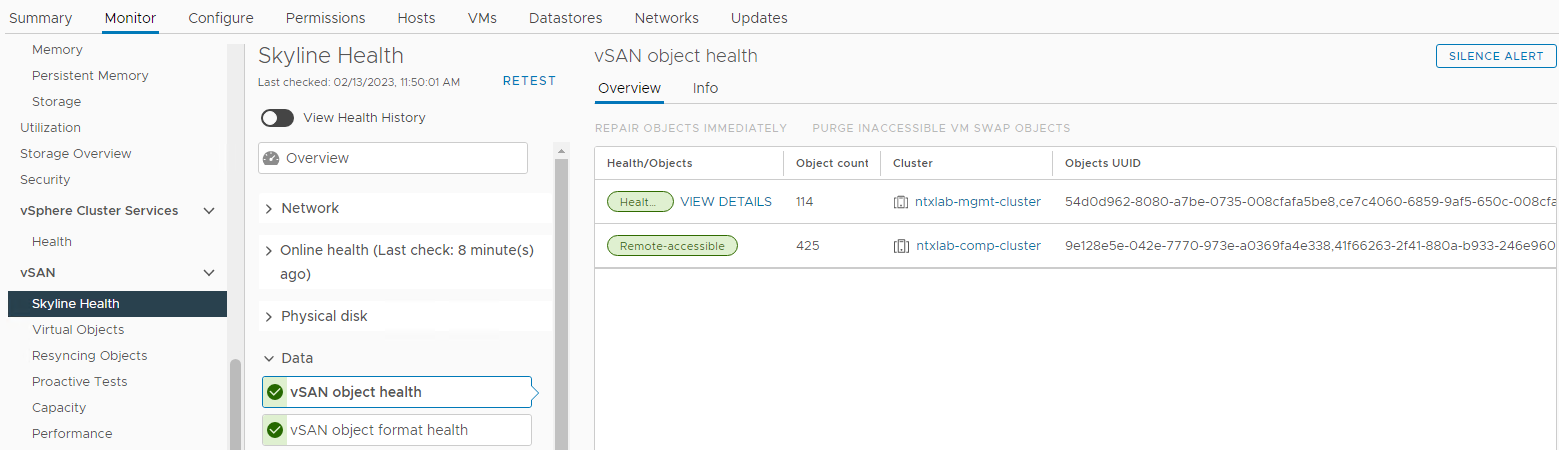
POZNÁMKA: Je důležité ověřit, zda neexistují žádné nepřístupné objekty. Nepřístupný objekt znamená, že "chybí všechny kopie objektu". Pokud vyjmete nebo vyměníte disk, může to způsobit DL.
Dalším krokem je shromáždění dalších informací o problému prostřednictvím rozhraní příkazového řádku a kontrola protokolů:
Kontrola stavu fyzického disku vSAN z rozhraní příkazového řádku:
Připojení přes SSH k dotčenému hostiteli a spuštění následujících příkazů:
vdq -qH
Zkontrolujte "IsPDL" (trvalá ztráta zařízení). Pokud je roven 1, disk je ztracen.
Příklad:
DiskResults:
DiskResult[0]:
Name: naa.600508b1001c4b820b4d80f9f8acfa95
VSANUUID: 5294bbd8-67c4-c545-3952-7711e365f7fa
State: In-use for VSAN
ChecksumSupport: 0
Reason: Non-local disk
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 0
<<truncated>>
DiskResult[18]:
Name:
VSANUUID: 5227c17e-ec64-de76-c10e-c272102beba7
State: In-use for VSAN
ChecksumSupport: 0
Reason: None
IsSSD?: 0
IsCapacityFlash?: 0
IsPDL?: 1
vdq -iH
Zkontrolujte, zda ve skupině disků nechybí nějaký disk.
Příklad:
Mappings: DiskMapping[0]: SSD: naa.58ce38ee2016ffe5 MD: naa.5002538a4819e3e0 DiskMapping[2]: SSD: naa.58ce38ee2016fe55 MD: naa.5002538a48199ca0 MD: naa.5002538a48199e20 MD: naa.5002538a48199e00
esxcli vsan storage list
Zkontrolujte, zda "In CMMDS". Pokud je hodnota false, komunikace je ztracena na disku.
Příklad:
Device: Unknown
Display Name: Unknown
Is SSD: false
VSAN UUID: 529cadbc-acd1-b588-8643-68336d5512d6
VSAN Disk Group UUID:
VSAN Disk Group Name:
Used by this host: false
In CMMDS: false
On-disk format version: <Unknown>
Deduplication: false
Compression: false
Checksum:
Checksum OK: false
Is Capacity Tier: false
for i in `esxcli storage core device list | grep ^naa` ; do echo $i; esxcli storage core device smart get -d $i; done.
Zkontrolujte chyby čtení/zápisu pomocí příkazu smart get.
Příklad:
naa.55cd2e404c1f35a1 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 86 Read Error Count 130 39 130 133 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 26 Uncorrectable Sector Count 100 0 100 0
naa.55cd2e404c1f35a5 Parameter Value Threshold Worst Raw -------------------------- ----- --------- ----- --- Health Status OK N/A N/A N/A Media Wearout Indicator 100 0 100 10 Read Error Count 130 39 130 53 Power-on Hours 100 0 100 110 Power Cycle Count 100 0 100 106 Drive Temperature 100 0 100 27 Uncorrectable Sector Count 100 0 100 0
esxcli vsan storage list | grep "VSAN Disk Group UUID:" | sort | uniq -c
Zkontrolujte dostupné skupiny disků.
Příklad:
2 VSAN Disk Group UUID: 5203424c-ee56-497d-75d1-fcf73ae997cb 2 VSAN Disk Group UUID: 52af8e5c-77d1-b552-3310-ec5fef09edf4
while true;do echo " ****************************************** "; echo "" > /tmp/resyncStats.txt ;cmmds-tool find -t DOM_OBJECT -f json |grep uuid |awk -F \" '{print $4}' |while read i;do pendingResync=$(cmmds-tool find -t DOM_OBJECT -f json -u $i|grep -o "\"bytesToSync\": [0-9]*,"|awk -F " |," '{sum+=$2} END{print sum / 1024 / 1024 / 1024;}');if [ ${#pendingResync} -ne 1 ]; then echo "$i: $pendingResync GiB";fi;done |tee -a /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |awk '{sum+=$2} END{print sum}');echo "Total: $total GiB" |tee -aa /tmp/resyncStats.txt;total=$(cat /tmp/resyncStats.txt |grep Total);totalObj=$(cat /tmp/resyncStats.txt|grep -vE " 0 GiB|Total"|wc -l);echo "`date +%Y-%m-%dT%H:%M:%SZ` $total ($totalObj objects)" >> /tmp/totalHistory.txt; echo `date `; sleep 60; done
Zkontrolujte, zda probíhají probíhající nebo zaseknuté operace opětovné synchronizace.
Příklad:
Total: 0 GiB Mon Feb 13 17:32:06 UTC 2023
Stisknutím kláves Ctrl+C příkaz k zastavení.
cmmds-tool find -f python | grep CONFIG_STATUS -B 4 -A 6 | grep 'uuid\|content' | grep -o 'state\\\":\ [0-9]*' | sort | uniq -c
Zkontrolujte stav komponent.
Healthy -- state 7
Inaccessible -- state 13
Absent or Degraded -- state 15
Příklad:
425 state\": 7
Jak pomocí rozhraní příkazového řádku zjistit, kde se vadný disk SSD nebo PEVNÝ DISK nachází:
Seznam všech dostupných zařízení:
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa"
Příklad:
naa.5000c500852df8d3 naa.55cd2e404c1f35a1 naa.55cd2e404c1f35a5 naa.5000c500852dd5e7
Zkontrolujte umístění pomocí jednotlivých naa. disků ze seznamu:
esxcli storage core device physical get -d
Příklad:
esxcli storage core device physical get -d naa.5000c500852df8d3 esxcli storage core device physical get -d naa.55cd2e404c1f35a1 esxcli storage core device physical get -d naa.55cd2e404c1f35a5 esxcli storage core device physical get -d naa.5000c500852dd5e7 Physical Location: enclosure 65535 slot 0 Physical Location: enclosure 65535 slot 1 Physical Location: enclosure 65535 slot 2 Physical Location: enclosure 65535 slot 3
Jak identifikovat vadný pevný disk nebo disk SSD, pokud chybí název zařízení:
Je možné, že vadný disk není rozpoznán a nelze jej identifikovat pomocí odpovídajícího čísla naa. V tomto scénáři je potřeba vyhledat všechny disky a ten, který není fyzicky umístěný, by byl ten, který selže.
Zde je skript, který lze použít k provedení úlohy o něco rychleji:
echo "=============Physical disks placement=============="
echo ""
esxcli storage core device list | grep "naa" | awk '{print $1}' | grep "naa" | while read in; do
echo "$in"
esxcli storage core device physical get -d "$in"
sleep 1
echo "===================================================="
done
Protokoly relevantní pro vSAN pro problémy související s úložištěm:
/var/log/vmkernel.log
Problémy se čtením a zápisem na disky vSAN, prezenčními signály hostitele vSAN, PDL, kódy zjišťování SCSI a požadavky I/O (čtení/zápis) a informace o členství v clusteru.
Příklad:
2021-06-22T12:02:08.408Z cpu30:1001397101)ScsiDeviceIO: PsaScsiDeviceTimeoutHandlerFn:12834: TaskMgmt op to cancel IO succeeded for device naa.55cd2e404b7736d0 and the IO did not complete. WorldId 0, Cmd 0x28, CmdSN = 0x428.Cancelling of IO will be 2021-06-22T12:02:08.408Z cpu30:1001397101)retried.
/var/log/vobd.log
Zprávy o stavu disku, trvale ztracených discích zařízení (PDL), latenci disku a hlášeních o tom, kdy hostitel vstoupí do režimu údržby a ukončí jej.
Příklad:
2022-05-31T11:42:46.065Z: [vSANCorrelator] 10605891965954us: [vob.vsan.lsom.devicerepair] vSAN device 521a74ce-c980-c16c-ff3d-38a036233daf is being repaired due to I/O failures, and will be out of service until the repair is complete. If the device is part of a dedup disk group, the entire disk group will be out of service until the repair is complete. 2022-05-31T11:42:46.065Z: [vSANCorrelator] 10606062774178us: [esx.problem.vob.vsan.lsom.devicerepair] Device 521a74ce-c980-c16c-ff3d-38a036233daf is in offline state and is getting repaired
/var/log/vsandevicemonitord.log
Pomůže vám určit, jestli byl disk označený jako není v pořádku kvůli nadměrnému zahlcení protokolů nebo latencím vstupně-výstupních operací.
Příklad:
INFO vsandevicemonitord WARNING - WRITE Average Latency on VSAN device naa.50000xxxxxxxx has exceeded threshold value 2000000 us 2 times. INFO vsandevicemonitord Tier 2 (naa.50000xxxxxxxx) as unhealthy
Additional Information
Podívejte se na toto video:
VMware: Průvodce odstraňováním problémů s fyzickým diskem vSAN
Délka: 00:10:19 (hh:mm:ss)
Je-li k dispozici, lze jazyková nastavení titulků (titulků) zvolit pomocí ikony CC v tomto přehrávači videa.
Toto video můžete také zhlédnout na YouTube.
Affected Products
PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650, PowerEdge R650xs
, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, VMware ESXi 6.7.X, VMware ESXi 7.x, VMware ESXi 8.x, VMware VSAN, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node, VxRail 460 and 470 Nodes, VxRail D560, VxRail D560F, VxRail E460, VxRail E560, VxRail E560F, VxRail E560N, VxRail E660, VxRail E660F, VxRail E660N, VxRail E665, VxRail E665F, VxRail E665N, VxRail G560, VxRail G560F, VxRail P470, VxRail P570, VxRail P570F, VxRail P580N, VxRail P670F, VxRail P670N, VxRail P675F, VxRail P675N, VxRail S470, VxRail S570, VxRail S670, VxRail V470, VxRail V570, VxRail V570F, VXRAIL V670F, VxRail VD-4510C, VxRail VD-4520C, VxRail VE-660, VxRail VE-6615, VxRail VE-670, VxRail VP-760, VxRail VP-7625, VxRail VP-770
...
Products
VxRail, PowerEdge C6420, PowerEdge C6520, PowerEdge C6525, PowerEdge C6615, PowerEdge C6620, PowerEdge M640 (for PE VRTX), PowerEdge R440, PowerEdge R450, PowerEdge R540, PowerEdge R550, PowerEdge R640, PowerEdge R6415, PowerEdge R650
, PowerEdge R650xs, PowerEdge R6515, PowerEdge R6525, PowerEdge R660, PowerEdge R660xs, PowerEdge R6615, PowerEdge R6625, PowerEdge R740, PowerEdge R740XD, PowerEdge R740XD2, PowerEdge R7415, PowerEdge R7425, PowerEdge R750, PowerEdge R750XA, PowerEdge R750xs, PowerEdge R7515, PowerEdge R7525, PowerEdge R760, PowerEdge R760XA, PowerEdge R760xd2, PowerEdge R760xs, PowerEdge R7615, PowerEdge R7625, PowerEdge R840, PowerEdge R860, PowerEdge R940, PowerEdge R940xa, PowerEdge R960, PowerEdge T430, PowerEdge T440, PowerEdge T550, PowerEdge T560, PowerEdge T630, PowerEdge T640, Dell EMC vSAN C6420 Ready Node, Dell EMC vSAN MX740c Ready Node, Dell EMC vSAN MX750c Ready Node, Dell vSAN Ready Node MX760c, Dell EMC vSAN R440 Ready Node, Dell EMC vSAN R640 Ready Node, Dell EMC vSAN R6415 Ready Node, Dell EMC vSAN R650 Ready Node, Dell EMC vSAN R6515 Ready Node, vSAN Ready Node R660, Dell vSAN R6615 Ready Node, Dell EMC vSAN R740 Ready Node, Dell EMC vSAN R740xd Ready Node, Dell EMC vSAN R750 Ready Node, Dell EMC vSAN R7515 Ready Node, Dell EMC vSAN R760 Ready Node, Dell vSAN R7615 Ready Node, Dell vSAN Ready Node R7625, Dell EMC vSAN R840 Ready Node, Dell EMC vSAN T350 Ready Node
...
Article Properties
Article Number: 000209262
Article Type: How To
Last Modified: 29 May 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.