Openshift: Sprawdzanie wstępne uaktualnienia OCP nie powiodło się z powodu błędu węzła opróżniania przebiegu próbnego
Summary: Wstępna kontrola uaktualnienia OCP nie powiodła się z powodu błędu węzła opróżniania przebiegu próbnego, ponieważ nie można przeprowadzić migracji niektórych maszyn wirtualnych na żywo lub nie można eksmitować niektórych zasobników. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Podczas wstępnej kontroli LCM może wystąpić awaria węzła opróżniania przebiegu próbnego, która zablokuje proces LCM.
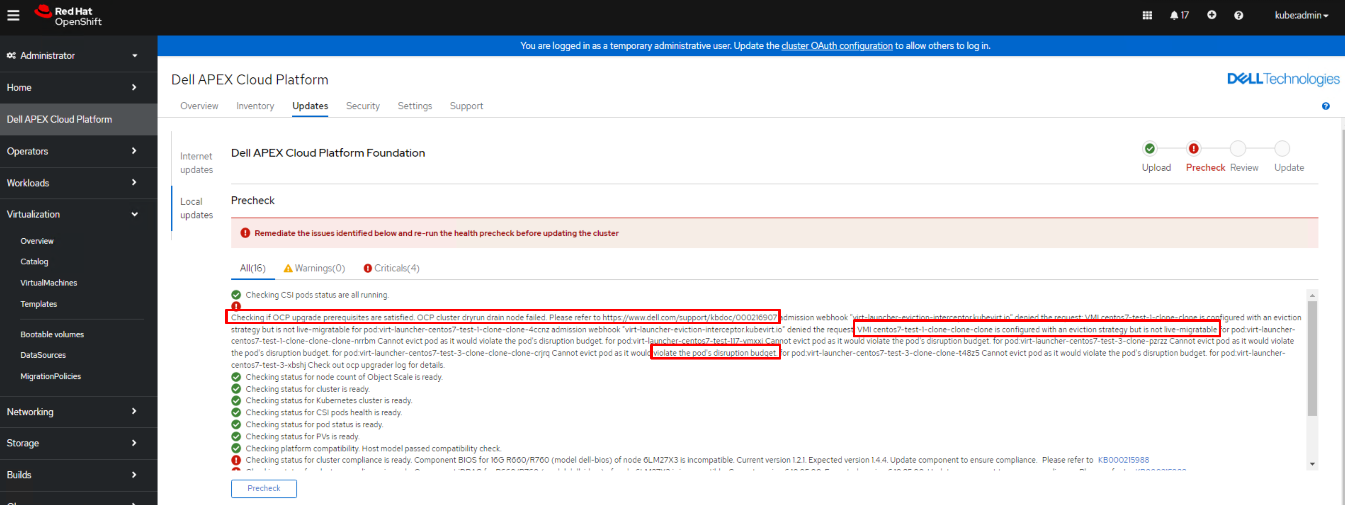
Komunikat o błędzie może obejmować między innymi następujące scenariusze:
Komunikat o błędzie może obejmować między innymi następujące scenariusze:
- Scenariusz 1: "VMI XXXXXX jest skonfigurowany ze strategią eksmisji, ale nie można go migrować na żywo".
- Scenariusz 2: "Nie można eksmitować kapsuły, ponieważ naruszyłoby to budżet zakłócenia kapsuły".
- Scenariusz 3: Nie znaleziono "pods xxx" dla pod:xxxxxxxxxxxx
Cause
Główna przyczyna scenariusza 1: Maszyna wirtualna jest skonfigurowana z woluminem pamięci masowej ReadWriteOnce (RWO), którego nie można migrować na żywo w węźle raportowania błędów.
Główna przyczyna scenariusza 2: Ustawienie zasobnika "PodDistruptionBudget" jest skonfigurowane jako "minAvailable: 1", Zablokuje to proces eksmisji zasobników.
Senario 3 główna przyczyna: Zaplanowane zadanie Openshift uruchomi zasobnik, a zasobnik zostanie zakończony po zakończeniu zadania. Istnieje więc szansa, że zasobnik nie zostanie znaleziony podczas wstępnego sprawdzania kroku węzła opróżniania przebiegu próbnego.
Główna przyczyna scenariusza 2: Ustawienie zasobnika "PodDistruptionBudget" jest skonfigurowane jako "minAvailable: 1", Zablokuje to proces eksmisji zasobników.
Senario 3 główna przyczyna: Zaplanowane zadanie Openshift uruchomi zasobnik, a zasobnik zostanie zakończony po zakończeniu zadania. Istnieje więc szansa, że zasobnik nie zostanie znaleziony podczas wstępnego sprawdzania kroku węzła opróżniania przebiegu próbnego.
Resolution
Rozwiązanie scenariusza 1
1. Zatrzymaj wystąpienie maszyny wirtualnej przed zmianą jego ustawień PV.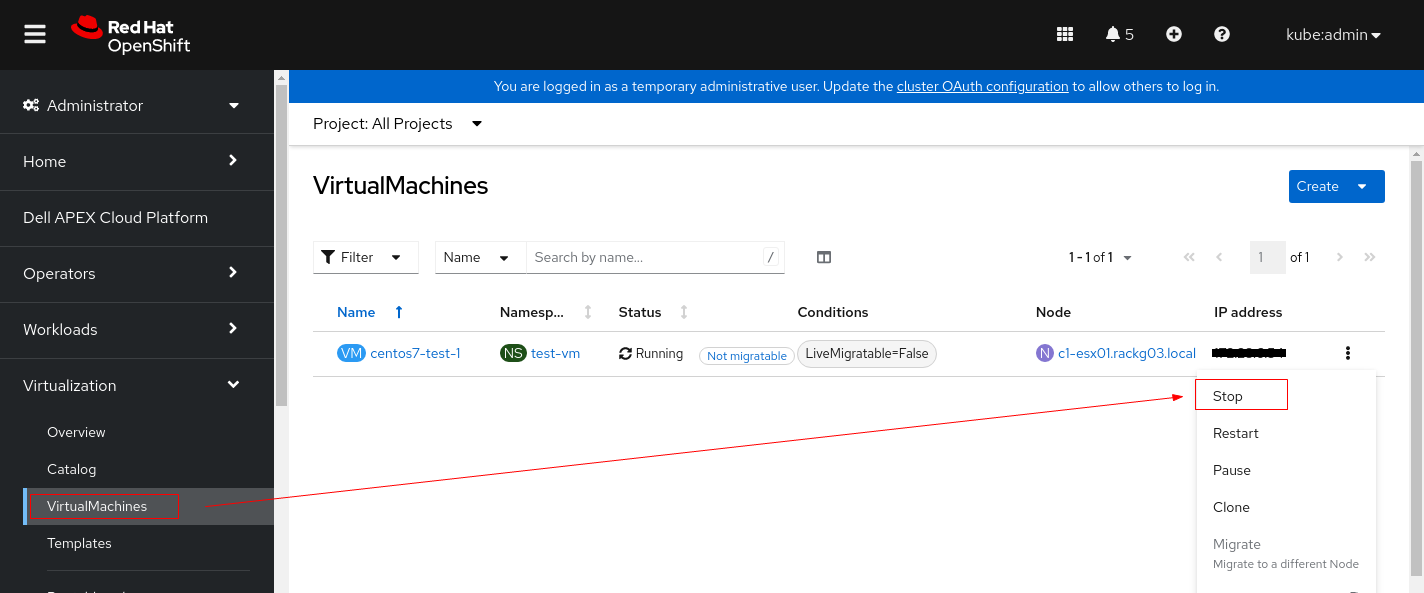
2. Kliknij maszynę wirtualną i przełącz się na kartę YAML.
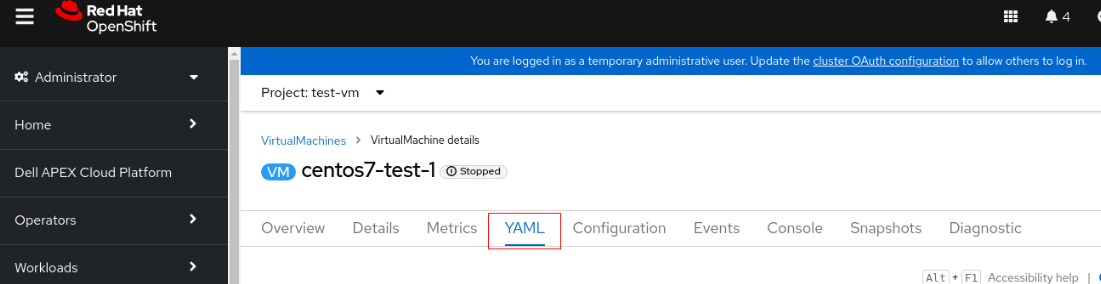
3. Zmień accessModes z "ReadWriteOnce" na "ReadWriteMany".
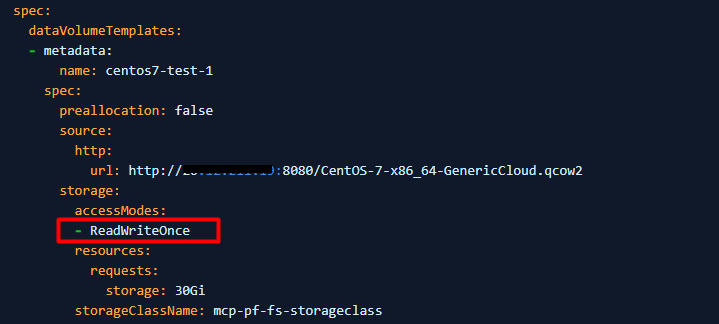
4. Jeśli PV nie można ustawić na ReadWriteMany (maszyna wirtualna nie może uruchomić użycia ReadWriteMany), ustaw wartość evictionStrategy z "LiveMigrate" na "None".
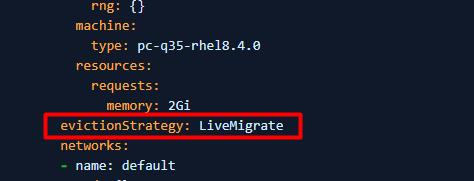
Uwaga: Wykonaj krok 3 lub 4, który dotyczy Twojego środowiska. Nie musisz wykonywać obu kroków.
5. Kliknij przycisk Save i uruchom ponownie maszynę wirtualną.
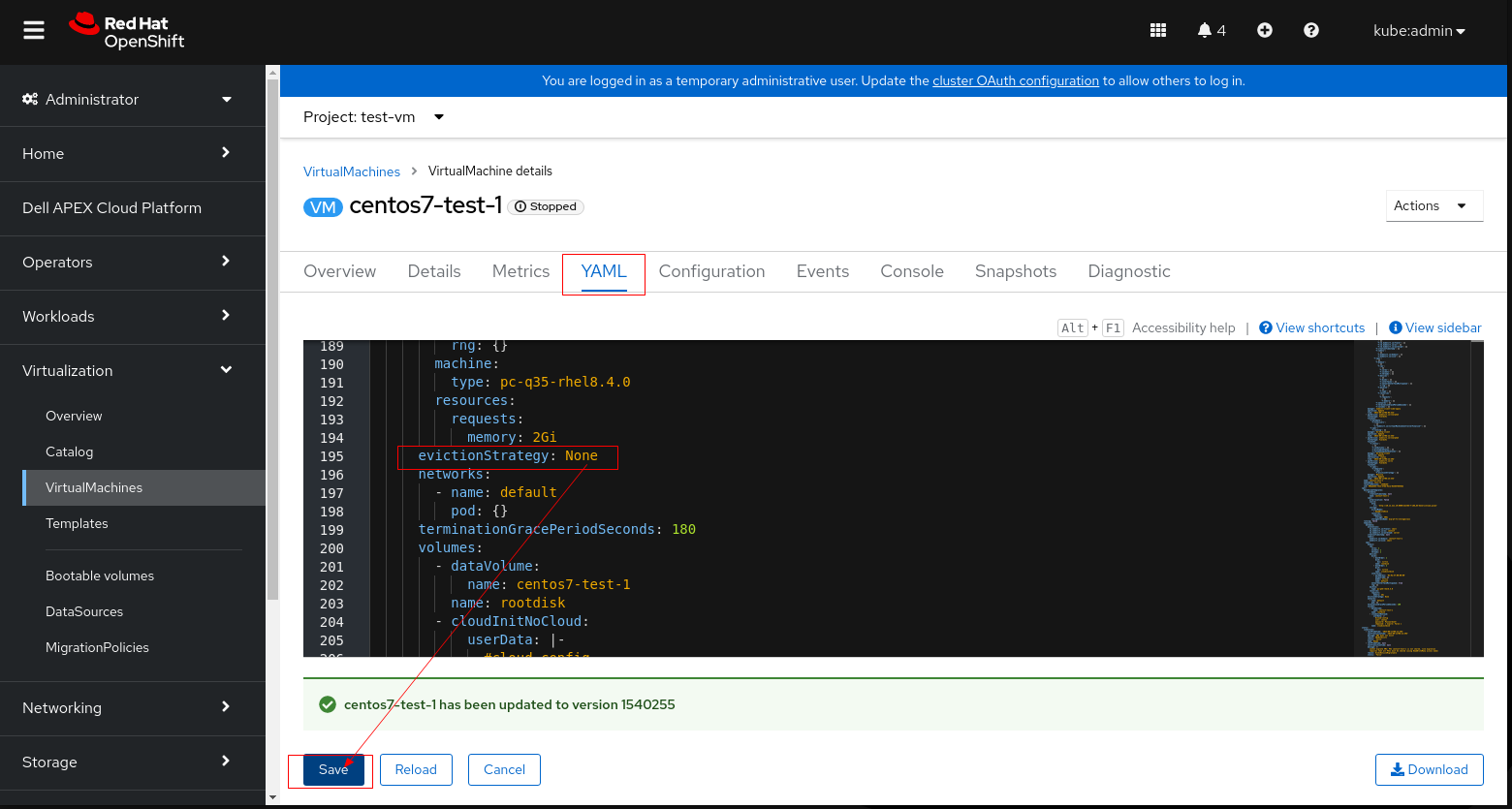
6. Ponów próbę wstępnego sprawdzenia LCM i kontynuuj uaktualnianie.
Rozwiązanie scenariusza 2
Wykonaj jedną z poniższych procedur, która ma zastosowanie do Twojego środowiska.
Procedura 1: Ręcznie usuń zasobniki, których nie można eksmitować.
- Uruchom poniższe polecenie, aby usunąć zasobniki, których nie można eksmitować, i pozwól im ponownie utworzyć je w różnych węzłach.
$ oc delete pod <pod_name> -n <pod_namespace>
- Ponów próbę wstępnego sprawdzenia LCM i kontynuuj uaktualnianie.
Procedura 2: Jeśli zasobnik nie może zostać usunięty ręcznie, popraw zasobnik, którego wartość "PodDisruptionBudget" jest skonfigurowana jako "minAvailable: 1"
- Uruchom poniższe polecenie, aby sprawdzić wartość zasobnika "PodDisruptionBudget"
Na przykład:
$ oc get pdb <pdb_name> -n <pod_namespace> NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE <pdb_name> 1 N/A 0 18h
- Jeśli dane wyjściowe polecenia pokazują, że wartość "MIN AVAILABLE" wynosi "1", popraw wartość PodDisruptionDisruptionBudget minAvailable do "0" za pomocą poniższego polecenia.
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":0}}'
- Ponów próbę wstępnego sprawdzenia LCM i kontynuuj uaktualnianie.
- Poczekaj, aż uaktualnienie się zakończy i MCO będzie dostępne, uruchom poniższe polecenie, aby sprawdzić, czy wszystko jest w porządku.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Na przykład:
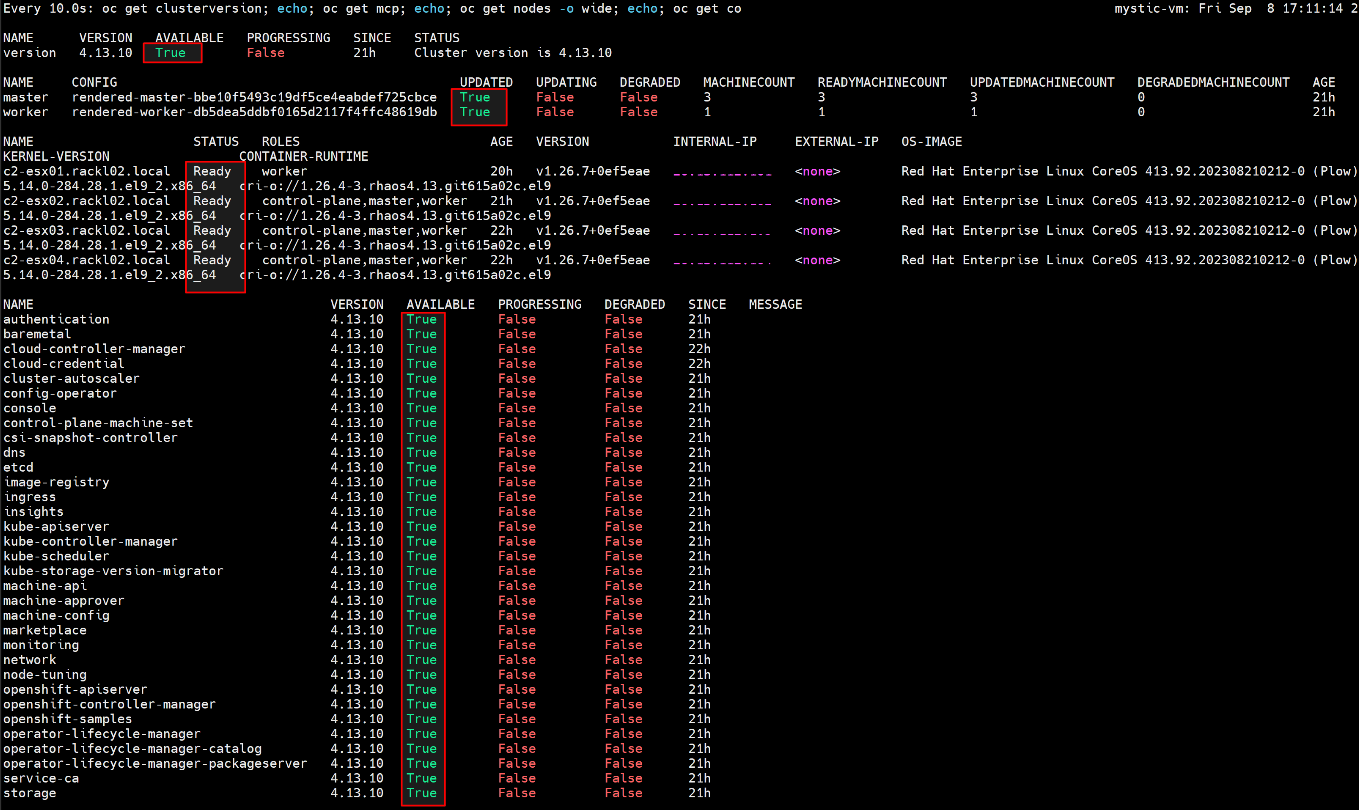
- Po zakończeniu uaktualniania OCP przywróć wartość minimalnej dostępności PodDisruptionBudget do "1"
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":1}}'
Procedura 3: Jeśli poprawianie błędu trafienia zasobnika "PodDisruptionBudget.policy "<pdb_name>" jest nieprawidłowe: spec: Dostęp zabroniony: aktualizacje specyfikacji poddisruptionbudget są zabronione.", wykonaj poniższe kroki, aby obejść ten problem.
- Utwórz kopię zapasową elementu PodDisruptionBudget, który jest skonfigurowany z "minAvailable: 1"
$ oc get pdb <pdb_name> -n <pod_namespace> -o yaml > <pdb_name>_backup.yaml
- Usuń element PodDisruptionBudget, który jest skonfigurowany z "minAvailable: 1"
$ oc delete pdb <pdb_name> -n <pod_namespace>
- Ponów próbę wstępnego sprawdzenia LCM i kontynuuj uaktualnianie.
- Poczekaj, aż uaktualnienie się zakończy i MCO będzie dostępne, uruchom poniższe polecenie, aby sprawdzić, czy wszystko jest w porządku.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Na przykład:
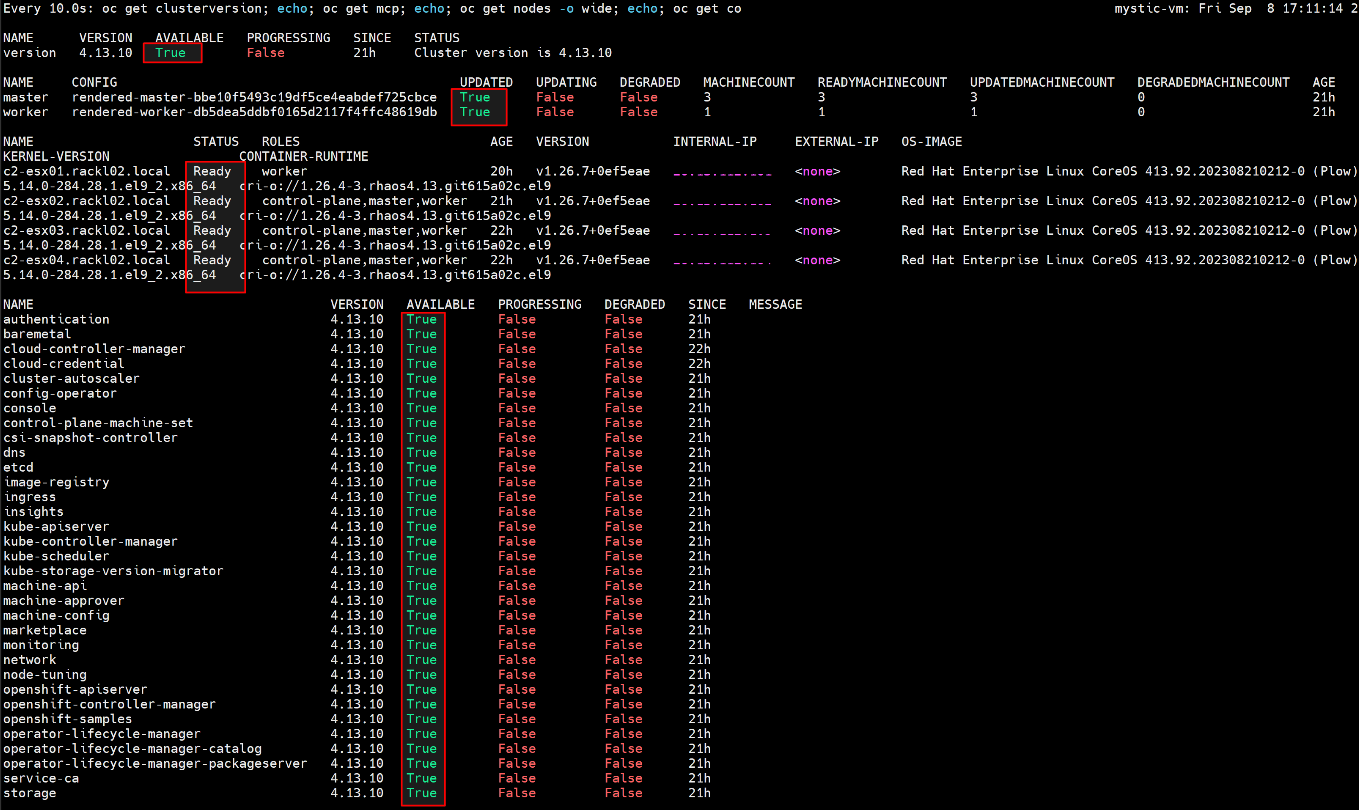
- Po zakończeniu uaktualniania OCP przywróć plik yaml kopii zapasowej.
$ oc create -f <pdb_name>_backup.yaml -n <pod_namespace>
Rozwiązanie scenariusza 3
Po prostu ponów próbę wstępnej kontroli LCM, tym razem powinna zakończyć się pomyślnie.
Additional Information
Sprawdź poniższy dokument Openshift, aby uzyskać więcej informacji na temat woluminów pamięci masowej dla dysków maszyn wirtualnych.
Affected Products
APEX Cloud Platform for Red Hat OpenShiftArticle Properties
Article Number: 000216907
Article Type: Solution
Last Modified: 18 Feb 2026
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.