

Generative AI (GenAI) has crashed the world of computing, and our customers want to start working with large language models (LLMs) to develop innovative new capabilities to drive productivity, efficiency and innovation in their companies. Dell Technologies has the world’s broadest AI infrastructure portfolio that spans from cloud to client devices, all in one place*—providing end-to-end AI solutions and services designed to meet customers wherever they are in their AI journey. Dell also offers hardware solutions engineered to support AI workloads, from workstation PCs (mobile and fixed) to servers for high-performance computing, data storage, cloud native software-defined infrastructure, networking switches, data protection, HCI and services. But one of the biggest questions from our customers is how to determine whether a PC can work effectively with a particular LLM. We’ll try to help answer that question and provide some guidance on configuration choices that users should consider when working with GenAI.
First, consider some basics on what is helpful to handle an LLM in a PC. While AI routines can be processed in the CPU or a new class of dedicated AI circuitry called an NPU, NVIDIA RTX GPUs currently hold the pole position for AI processing in PCs with dedicated circuits called Tensor cores. RTX Tensor cores are designed to enable mixed precision mathematical computing that is at the heart of AI processing. But performing the math is only part of the story, LLMs have the additional consideration of available memory space given their potential memory footprint. To maximize performance of AI in the GPU, you want the LLM processing to fit into the GPU VRAM. NVIDIA’s line of GPUs is scalable across both the mobile and fixed workstation offerings to provide options for the number of Tensor cores and GPU VRAM, so a system can be easily sized to fit. Keep in mind that some fixed workstations can host multiple GPUs expanding capacities even further.
There are an increasing number and variety of LLMs coming onto the market, but one of the most important considerations for determining hardware requirements is the parameter size of the LLM selected. Take Meta AI’s Llama-2 LLM. It is available in three different parameter sizes—seven, 13 and 70 billion parameters. Generally, with higher parameter sizes, one can expect greater accuracy from the LLM and greater applicability for general knowledge applications.
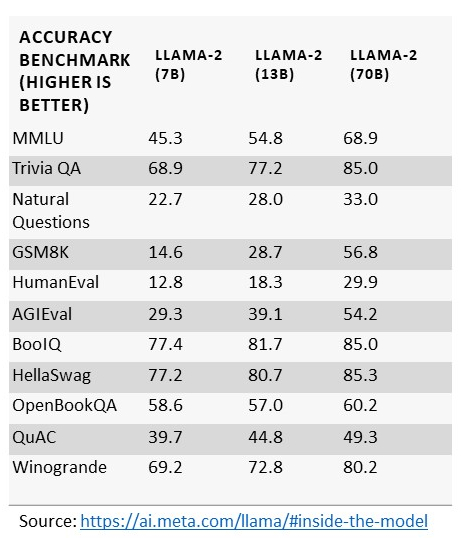
Whether a customer’s goal is to take the foundation model and run it as is for inferencing or to adapt it to their specific use case and data, they need to be aware of the demands the LLM will put on the machine and how to best manage the model. Developing and training a model against a specific use case using customer-specific data is where customers have seen the greatest innovation and return on their AI projects. The largest parameter size models can come with extreme performance requirements for the machine when developing new features and applications with the LLMs, so data scientists have developed approaches that help reduce the processing overhead and manage the accuracy of the LLM output simultaneously.
Quantization is one of those approaches. It is a technique used to reduce the size of LLMs by modifying the math precision of their internal parameters (i.e., weights). Reducing the bit precision has two impacts to the LLM, reducing the processing footprint and memory requirements and also impacting the output accuracy of the LLM. Quantization can be viewed as analogous to JPEG image compression where applying more compression can create more efficient images, but applying too much compression can create images that may not be legible for some use cases.
Let’s look at an example of how quantizing an LLM can reduce the required GPU memory.

To put this into practical terms, customers who want to run the Llama-2 model quantized at 4-bit precision have a range of choices in the Dell Precision workstation range.

Running at higher precision (BF16) ramps the requirements, but Dell has solutions that can serve any size LLM and whatever precision needed.

Given the potential impacts to output accuracy, another technique called fine-tuning can improve accuracy by retraining a subset of the LLM’s parameters on your specific data to improve the output accuracy for a specific use case. Fine-tuning adjusts the weight of some parameters trained and can accelerate the training process and improve output accuracy. Combining fine-tuning with quantization can result in application-specific small language models that are ideal to deploy to a broader range of devices with even lower AI processing power requirements. Again, a developer who wants to fine-tune an LLM can be confident using Precision workstations as a sandbox in that process for building GenAI solutions.
Another technique to manage the output quality of LLMs is a technique called Retrieval-Augmented Generation (RAG). This approach provides up-to-date information in contrast to conventional AI training techniques, which are static and dated by the information used when they were trained. RAG creates a dynamic connection between the LLM and relevant information from authoritative, pre-determined knowledge sources. Using RAG, organizations have greater control over the generated output, and users have better understanding of how the LLM generates the response.
These various techniques in working with LLMs are not mutually exclusive and often deliver greater performance efficiency and accuracy when combined and integrated.
In summary, there are key decisions regarding the size of the LLM and which techniques can best inform the configuration of the computing system needed to work effectively with LLMs. Dell Technologies is confident that whatever direction our customers want to take on their AI journey, we have solutions, from desktop to data center, to support them.
*Based on Dell analysis, August 2023.
