Article Number: 000145606
Enabling AI Workloads in HPC Environments
Summary: C4140, Horovod, conda, NGC, HPC, AI, ResNet-50
Article Content
Symptoms
Building GPU enabled Distributed distributed TensorFlow training with Horovod and NCCL
By John Lockman, Dell HPC and AI Innovation Lab
Resolution
Current Artificial Intelligence (AI) and data science software stacks are alarmingly complex. Perhaps even more alarming to the new user is the speed with which these stacks are evolving – monthly updates to multiple stack layers is not uncommon. AI software stacks can have deep intrinsic interdependencies between multiple libraries, which in many cases makes them significantly more fragile than traditional HPC stacks. Researchers and data scientists are tackling this software problem with modern systems based on Docker and Kubernetes to take advantage of optimized prebuilt containers. Currently, not all researchers have access to these container-based solutions and are using traditional HPC clusters.
HPC resources have traditionally been a sort of software time capsule: Once an HPC cluster is brought online, it is likely that the only subsequent updates made over its lifetime will be OS security fixes. This means AI users most likely will not find the latest versions of compilers and libraries needed to stay current with the newest versions of the software required for their projects.
Fortunately two Python package-management projects have become the de facto standards for solving this issue. The Python Package Index (PyPI) provides pip as a package manager (https://pypi.org/project/pip/), while Anaconda, Inc. (https://www.anaconda.com/) provides two solutions based on the conda package manager. Both approaches seek to simplify the process by which normal users (i.e., non-root) may freely manage their own local Python environments while staying safely inside the access provided by their HPC administrators.
The goal of this article is to provide current HPC users with instructions on how to quickly build a robust environment for evaluating and developing modern AI deep learning stacks. Starting with how to use Anaconda and pip together in building a complex user-space software environment. Then, walking through an example of using this environment to run a GPU accelerated distributed TensorFlow training application using Horovod. Finally, we present the results of running the ResNet-50 benchmark with the Conda environment.
Anaconda, Inc. provides two conda-based solutions: Anaconda and Miniconda. Anaconda adopts a "kitchen sink" approach and installs over 720 popular Python packages, whereas Miniconda opts for a minimalist approach. The demonstration below has been explicitly written for Miniconda. The team at Anaconda, Inc. has already made a bewildering number of packages available, so what could possibly necessitate the use of a second package manager?
In a perfect world, a single package manager would completely enable you to build an ideal Python AI data science environment containing every required dependency for successfully building, testing, and/or deploying GPU accelerated environment to distributed TensorFlow training. As mentioned above, however, the AI data science software stack is huge and dynamic.
In the current world, a single package manager seems to guarantee that at least one required package isn’t available – or still only has a previous version. The argument for a mixed conda/pip Python AI development environment is simple: It reduces the number of AI engineering hours collectively spent on maintaining Python environments and helps maintain focus on the actual workload.
Before You Begin:
This example documents one process to build a working multi-node, multi-GPU Python environment suitable for training many relevant AI models at-scale on HPC infrastructure. This specific case demonstrates how to build a GPU accelerated TensorFlow environment with conda, and how to add Uber’s Horovod using NCCL without breaking the conda environment. NCCL (NVIDIA Collective Communications Library) is a software library from Nvidia that provides multi-GPU and multi-node collective communication primitives. Horovod (https://github.com/uber/horovod) is a large-scale distributed GPU training platform that provides a means to utilize multiple compute nodes via Message Passing Interface (MPI) for distributed neural network training. While this was written and tested for TensorFlow, the process of building Python environments for other popular AI frameworks proceeds in an similar manner.
Be aware that there are caveats to simultaneously using conda and pip: https://www.anaconda.com/blog/developer-blog/using-pip-in-a-conda-environment/
Specifically, running conda after pip can potentially overwrite or break pip-installed packages. Conversely, it is also possible for pip to disrupt an installed conda environment.
Recommendation: Build the conda environment FIRST, THEN install pip packages. ALWAYS.
Depending on the specifics of your situation, you may prefer/be required to edit your login files in a unique way, for example by:
- Adding entries to your PATH and LD_LIBRARY_PATH
- Loading system environment modules – for instance, loading CUDA version 10.0 might be accomplished on your system with a command like: module load cuda10.0.
The top directory of many popular AI GitHub repositories contains a file called requirements.txt, which contains a list of additional Python packages upon which the developers’ code depends. Considering the above recommendation (conda then pip), you must decide upon the most expedient method by which to incorporate these packages into your HPC-AI environment. It is worth empirically trying a few variations on these basic instructions to converge to a robust environment for each specific AI repo – one size does not currently fit all.
Building GPU enabled distributed TensorFlow training with Horovod and NCCL
- Prerequisites: The Python environment MUST be built on a node with functional GPU hardware.
- CUDA driver: NVIDIA GPU-specific software layer
- OpenMPI: MPI for high-speed network fabrics such as InfiniBand and Omni-Path.
- gcc: Needed to build Horovod, minimum version 7.2.0
- Install Miniconda. See https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html
- Create a new Conda environment, specifying its name and your preferred Python version. For example, this command creates a new Python 3.6.8 environment named "mynewenv":
conda create --name mynewenv python=3.6.8
- Activate the newly-created conda environment. In Linux, this is done with the command:
conda activate mynewenv
- Direct conda to install the GPU accelerated version 1.12.0 of TensorFlow. By default, conda calculates the full list of changes it needs make to satisfy the package installation request, then displays the list with a y/n prompt on whether it should proceed. The -y flag simply affirms this prompt in advance.
conda install -y tensorflow-gpu==1.12.0
- Download OS-agnostic NCCL version (tarfile):
- NVIDIA supports multiple installation scenarios.
- See https://docs.nvidia.com/deeplearning/sdk/nccl-install-guide/index.html
- In this example, we download the OS-agnostic local installer for CUDA 10.0.
- Extract the NCCL tarfile into any convenient directory for which you have read/write access. NCCL files are extracted into a new subdirectory with the same name as the installer. For this example, we just extract into our $HOME directory with command:
tar xvf nccl_2.3.7-1+cuda10.0_x86_64.txz
- Direct pip to build and install Horovod by issuing command:
HOROVOD_NCCL_HOME=$HOME/nccl_2.3.7-1+cuda10.0_x86_64/ \
HOROVOD_GPU_ALLREDUCE=NCCL \
pip install --upgrade-strategy only-if-needed --no-cache-dir horovod==0.15.1
Performance Verification
To verify the performance of the Conda environment we ran the Resnet50 benchmark on a traditional HPC cluster. The traditional HPC cluster is configured with EDR Infiniband and uses SLURM as its batch queue manager. The system is made up from a collection of Dell PowerEdge C4140 servers with Nvidia V100-SXM2 32GB GPUs. The ResNet50 benchmark was run using 1, 2, 4, and 8 GPUs. Tests were run with synthetic and real data.
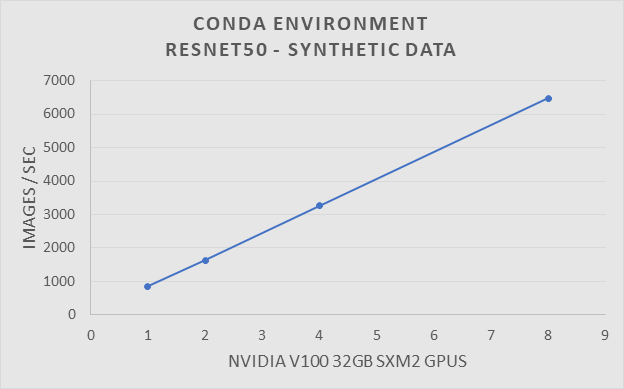
ResNet-50 benchmark using synthetic data with a Conda Environment on a traditional HPC system
| Platform |
PowerEdge C4140 |
| CPU |
2 x Intel® Xeon® Gold 6148 @2.4GHz |
| Memory |
384 GB DDR4 @ 2666MHz |
| Storage |
Lustre |
| GPU |
V100-SXM2 32GB |
| Operating System |
RHEL 7.4 x86_64 |
| Linux Kernel |
3.10.0-693.x86_64 |
| Network |
Mellanox EDR InfiniBand |
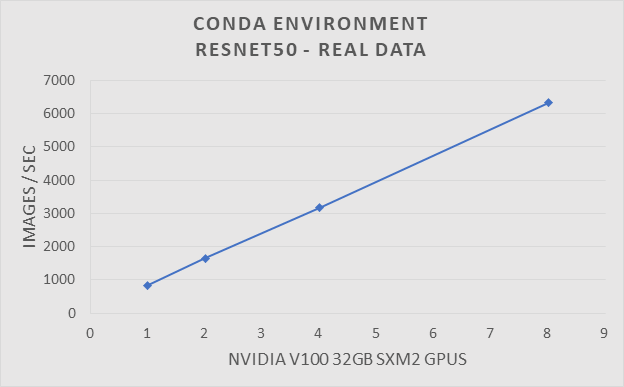
ResNet-50 benchmark using synthetic data with a Conda Environment on a traditional HPC system.
| Framework |
TensorFlow 1.12.0 |
| Horovod |
0.15.1 |
| MPI |
OpenMPI 4.0.1 |
| CUDA |
10.0 |
| NCCL |
2.3.7 |
| CUDNN |
7.6.0 |
| Python |
3.6.8 |
| Operating System |
RHEL 7.4 |
| GCC |
7.2.0 |
Summary:
The software stacks used for Deep Learning are complex, but researchers and system administrators shouldn’t have to worry about how to build them. Anaconda provides a method to quickly setup the complex software environment needed to do distributed training on a traditional HPC cluster. These results demonstrate that researchers can easily achieve expected performance without the knowledge of how to build the stack individually. Now traditional HPC clusters can run modern deep learning workloads in parallel to reduce time to solution.
Article Properties
Affected Product
High Performance Computing Solution Resources, Poweredge C4140
Last Published Date
21 Feb 2021
Version
3
Article Type
Solution