Openshift: Předběžná kontrola upgradu OCP selhala kvůli chybě uzlu dryrun drainu
Summary: Předběžná kontrola upgradu OCP selhala kvůli chybě vyprázdnění uzlu dryrun, protože některé virtuální počítače nelze migrovat za provozu nebo některé pody nelze vyřadit.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Během předběžné kontroly LCM může dojít k selhání uzlu vypouštění nanečisto, což zablokuje proces LCM.
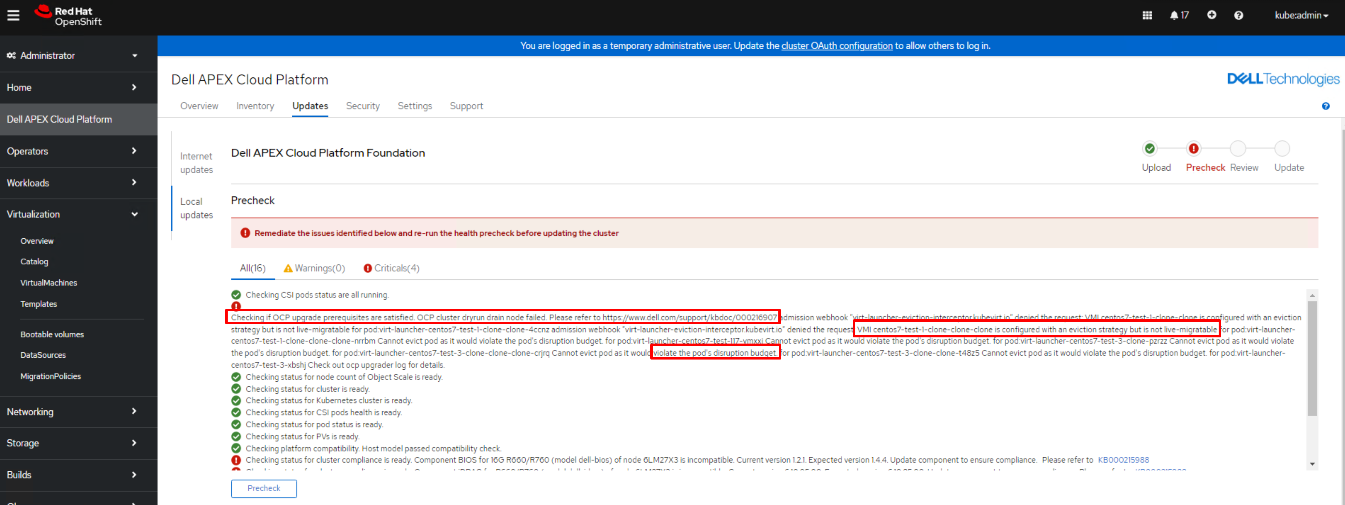
Chybová zpráva může obsahovat mimo jiné následující scénáře:
Chybová zpráva může obsahovat mimo jiné následující scénáře:
- 1. scénář: "VMI XXXXXX je nakonfigurován se strategií vyřazení, ale nelze jej migrovat za provozu."
- 2. scénář: "Nelze vystěhovat modul, protože by to porušilo rozpočet modulu na narušení."
- Scénář 3: "lusky xxx" nenalezeny pro pod:xxxxxxxxxxxx
Cause
Hlavní příčina scénáře 1: Virtuální počítač je nakonfigurovaný se svazkem úložiště ReadWriteOnce (RWO), který nelze migrovat za provozu na uzlu zasílání zpráv o chybách.
Hlavní příčina scénáře 2: Nastavení podDistruptionBudget je nakonfigurované jako "minAvailable: 1", Zablokuje proces vyřazení podů.
Hlavní příčina Senario 3: Naplánovaná úloha Openshift spustí pod a pod se po dokončení úlohy ukončí. Proto je možné, že pod nebude možné najít během kroku vyprazdňování uzlu dryrun před kontrolou.
Hlavní příčina scénáře 2: Nastavení podDistruptionBudget je nakonfigurované jako "minAvailable: 1", Zablokuje proces vyřazení podů.
Hlavní příčina Senario 3: Naplánovaná úloha Openshift spustí pod a pod se po dokončení úlohy ukončí. Proto je možné, že pod nebude možné najít během kroku vyprazdňování uzlu dryrun před kontrolou.
Resolution
Řešení scénáře 1
1. Před změnou nastavení PV zastavte instanci virtuálního počítače.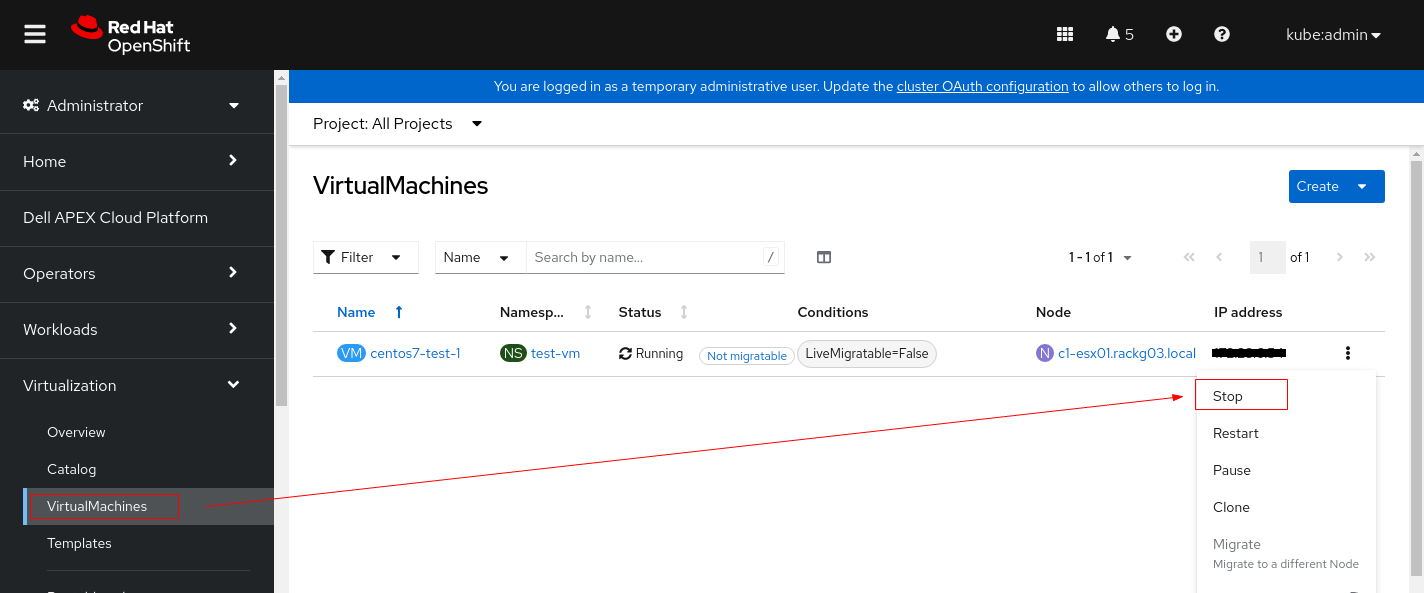
2. Klikněte na virtuální počítač a přepněte na kartu YAML.
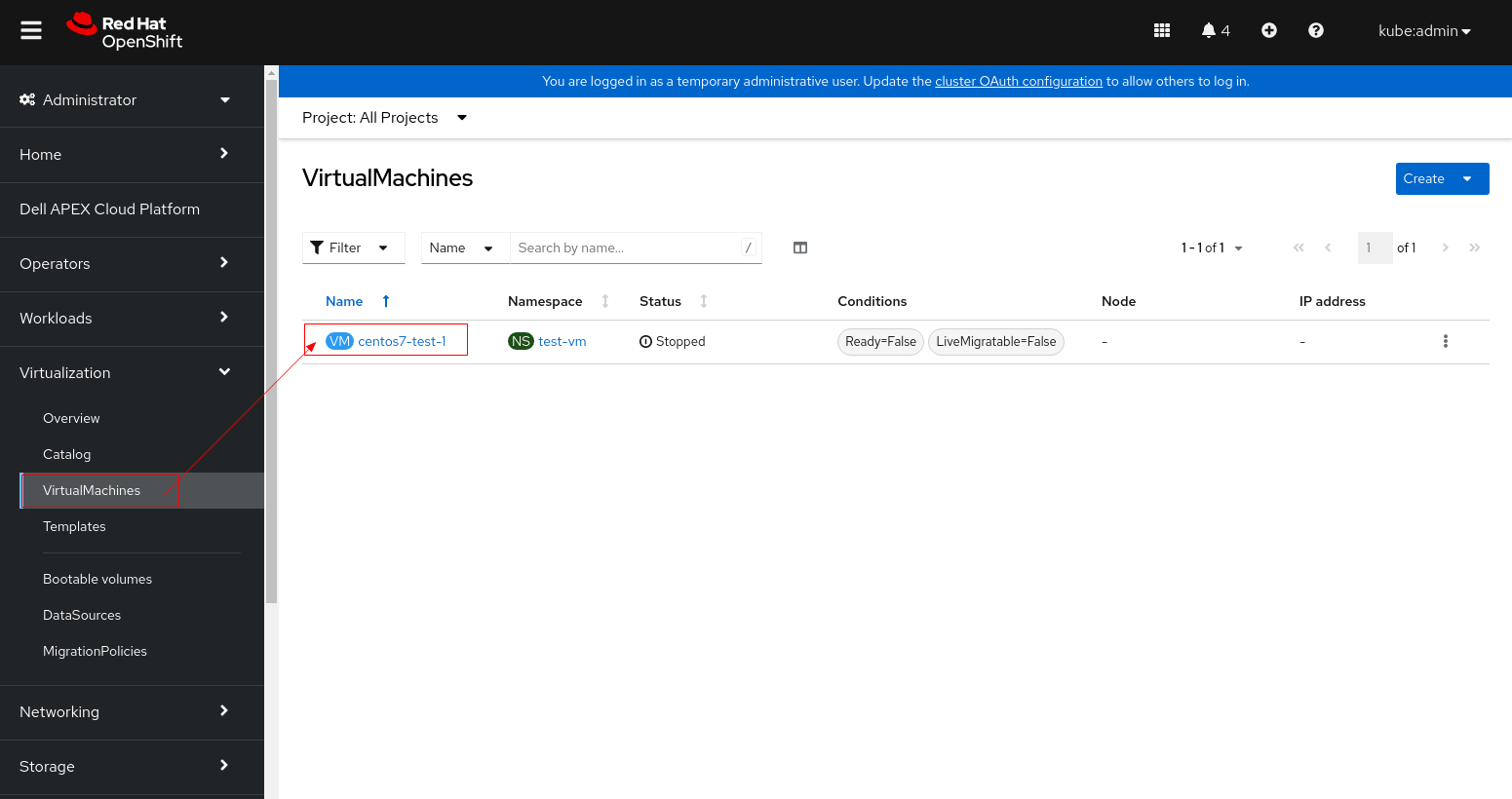
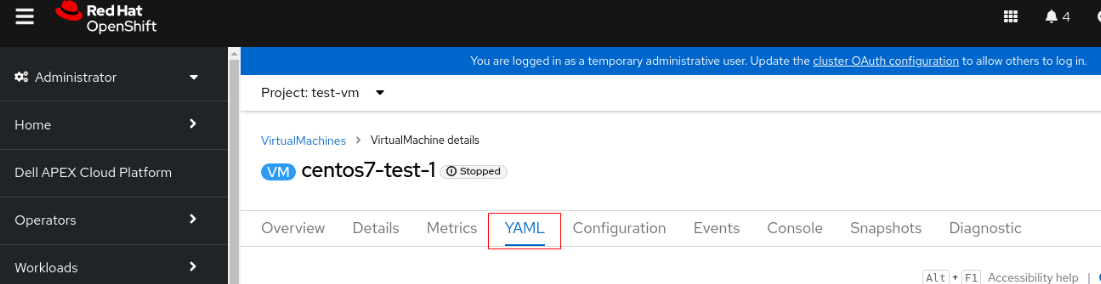
3. Změňte accessModes z "ReadWriteOnce" na "ReadWriteMany".
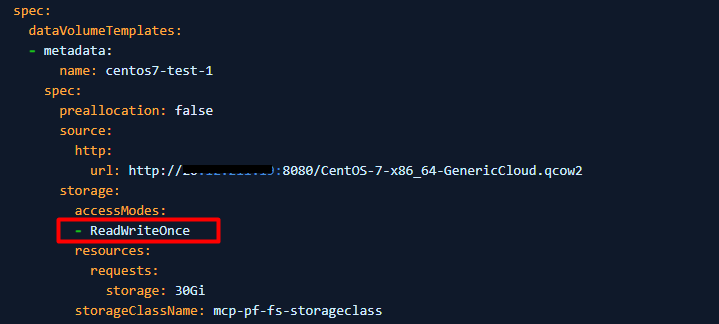
4. Pokud PV nelze nastavit na ReadWriteMany (virtuální počítač nemůže spustit use ReadWriteMany), nastavte evictionStrategy z "LiveMigrate" na "None".
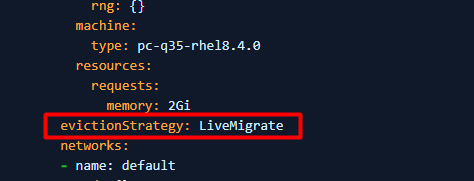
Poznámka: Proveďte krok 3 nebo 4, které se vztahují na vaše prostředí, nemusíte provádět oba kroky.
5. Klikněte na Uložit a restartujte virtuální počítač.
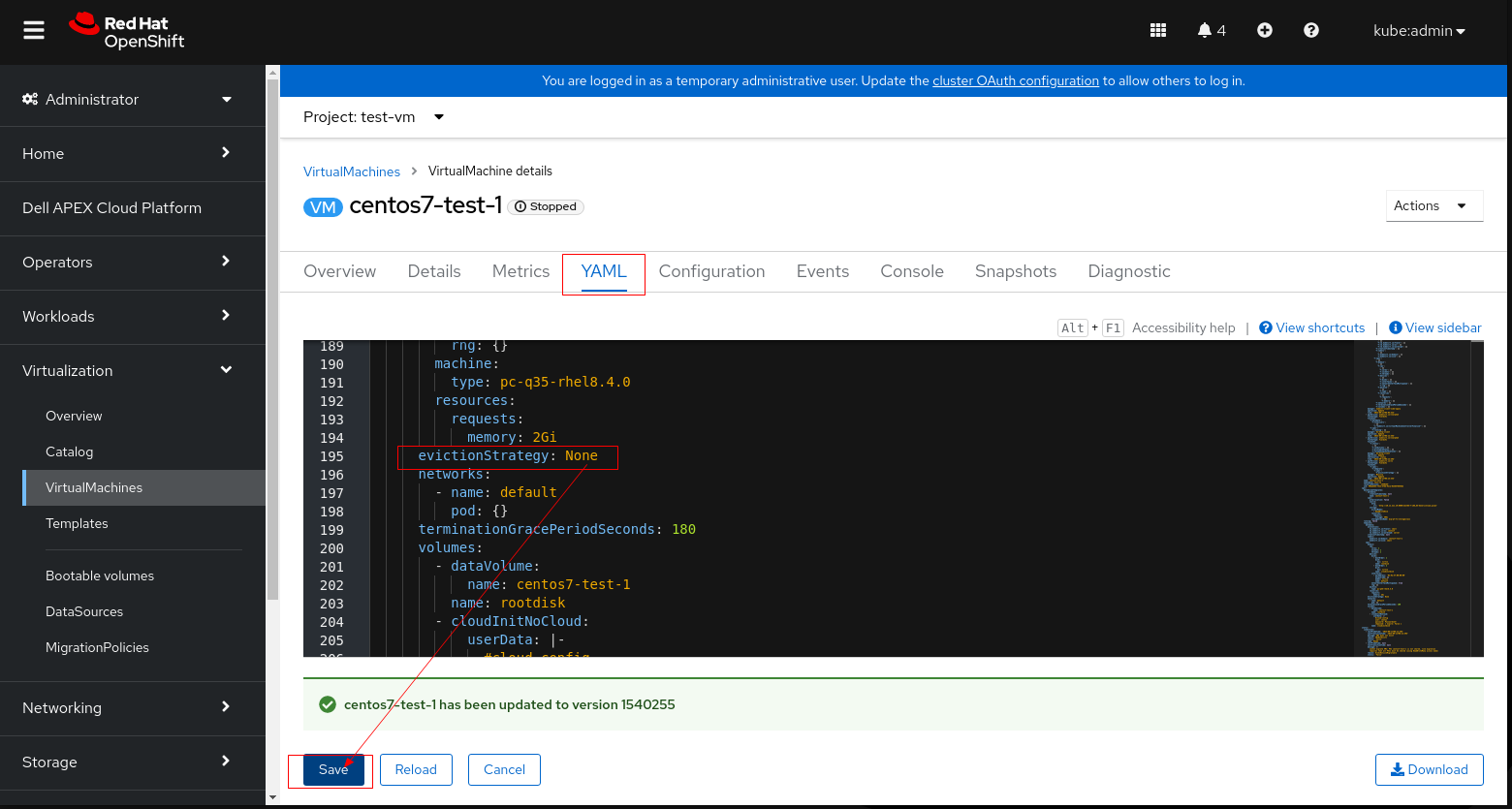
6. Opakujte předběžnou kontrolu nástroje LCM a pokračujte v upgradu.
Řešení scénáře 2
Proveďte jeden z následujících postupů, které platí pro vaše prostředí.
Postup 1: Ručně odstraňte pod/pody, které nelze vyřadit.
- Spuštěním níže uvedených příkazů odstraňte pody nebo pody, které nelze vyřadit, a nechte je znovu vytvořit v různých uzlech.
$ oc delete pod <pod_name> -n <pod_namespace>
- Opakujte předběžnou kontrolu nástroje LCM a pokračujte v upgradu.
Postup 2: Pokud se pod nedá ručně odstranit, opravte pod, jehož "PodDisruptionBudget" je nakonfigurovaný jako "minAvailable: 1"
- Spuštěním níže uvedeného příkazu zkontrolujte hodnotu "PodDisruptionBudget".
Například:
$ oc get pdb <pdb_name> -n <pod_namespace> NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE <pdb_name> 1 N/A 0 18h
- Pokud se ve výstupu příkazu zobrazí hodnota "MIN AVAILABLE" je "1", opravte hodnotu PodDisruptionBudget minAvailable na hodnotu "0" pomocí následujícího příkazu.
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":0}}'
- Opakujte předběžnou kontrolu nástroje LCM a pokračujte v upgradu.
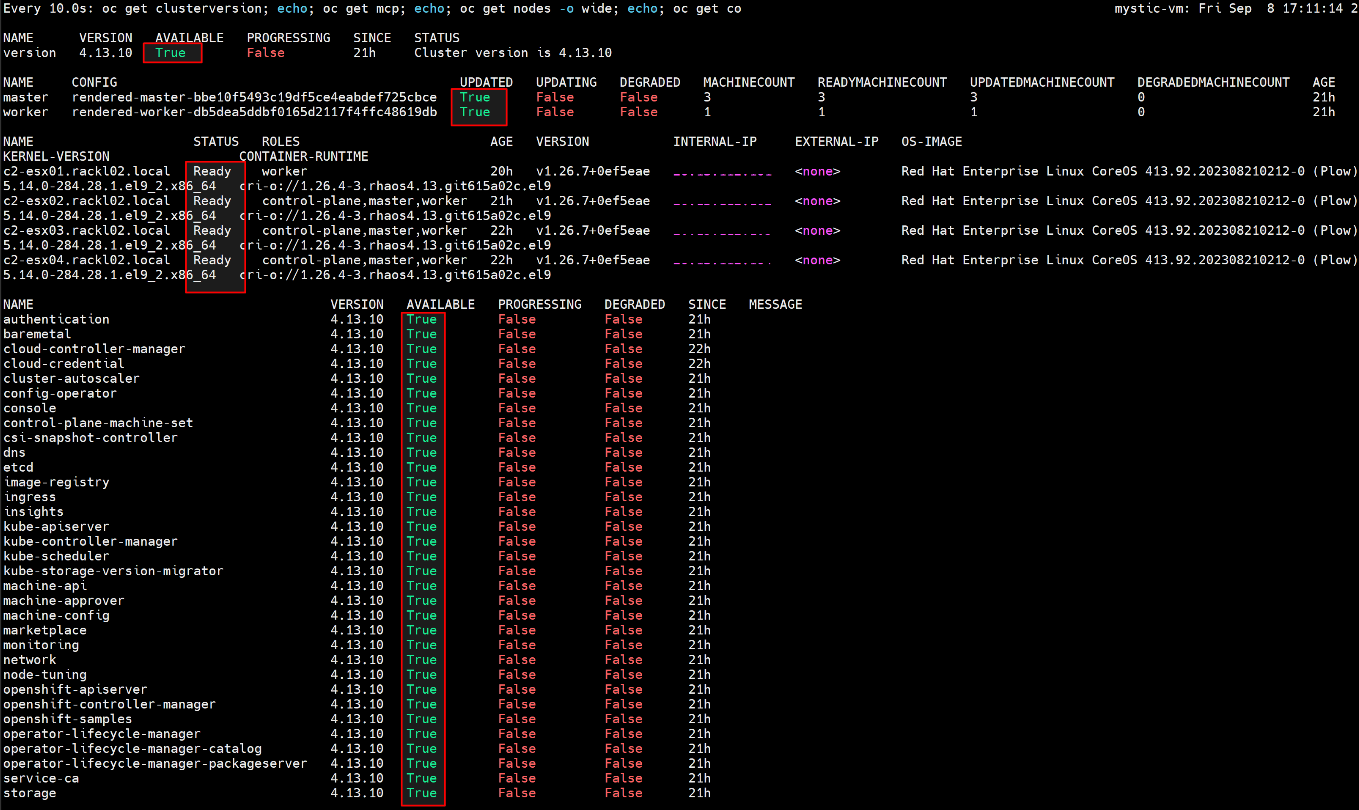
- Počkejte, až se upgrade dokončí a MCO bude k dispozici, spusťte níže uvedené příkazy a zkontrolujte, zda je vše v pořádku.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Například:
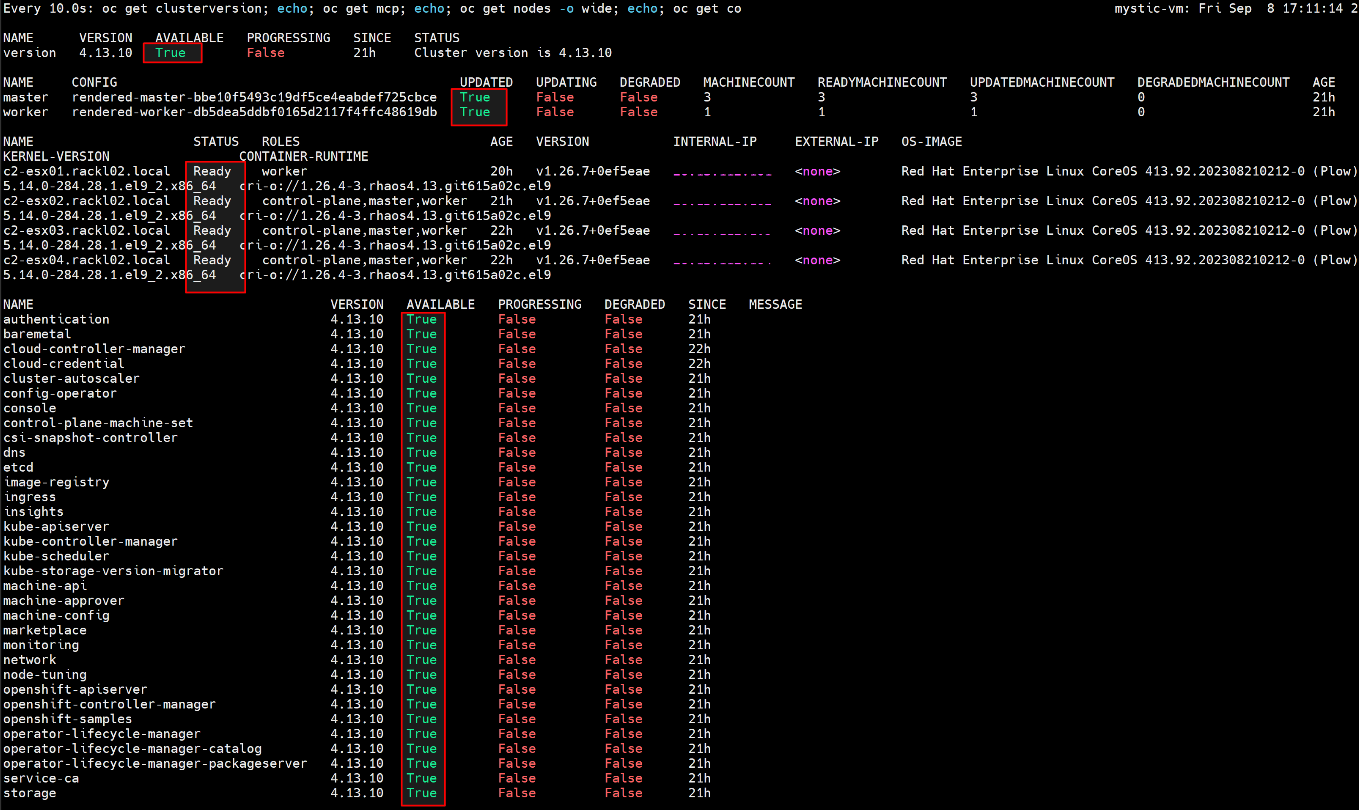
- Po dokončení upgradu OCP obnovte hodnotu PodDisruptionBudget minAvailable na hodnotu "1".
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":1}}'
Postup 3: Pokud oprava chyby "PodDisruptionBudget.policy<" "pdb_name>" je neplatná: spec: Zakázáno: aktualizace specifikace poddisruptionbudget jsou zakázány.", postupujte podle níže uvedených kroků pro alternativní řešení.
- Zálohujte PodDisruptionBudget, který je nakonfigurovaný na "minAvailable: 1"
$ oc get pdb <pdb_name> -n <pod_namespace> -o yaml > <pdb_name>_backup.yaml
- Odeberte PodDisruptionBudget, který je nakonfigurovaný na "minAvailable: 1"
$ oc delete pdb <pdb_name> -n <pod_namespace>
- Opakujte předběžnou kontrolu nástroje LCM a pokračujte v upgradu.
- Počkejte, až se upgrade dokončí a MCO bude k dispozici, spusťte níže uvedené příkazy a zkontrolujte, zda je vše v pořádku.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Například:
- Po dokončení upgradu OCP obnovte záložní soubor YAML.
$ oc create -f <pdb_name>_backup.yaml -n <pod_namespace>
Řešení scénáře 3
Jednoduše opakujte předběžnou kontrolu LCM, tentokrát by měla projít.
Additional Information
Další informace o svazcích úložiště pro disky virtuálních počítačů naleznete v dokumentu Openshift.
Affected Products
APEX Cloud Platform for Red Hat OpenShiftArticle Properties
Article Number: 000216907
Article Type: Solution
Last Modified: 18 Feb 2026
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.