Turno abierto: La verificación previa de actualización de OCP falló por un error del nodo de drenaje de simulacro
Summary: La comprobación previa de la actualización de OCP falló por un error en el nodo de drenaje de simulacro, debido a que algunas VM no se pueden migrar activas o algunos pods no se pueden expulsar. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Durante la comprobación previa de la LCM, podría haber una falla en el nodo de drenaje de simulacro que bloqueará el proceso de la LCM.
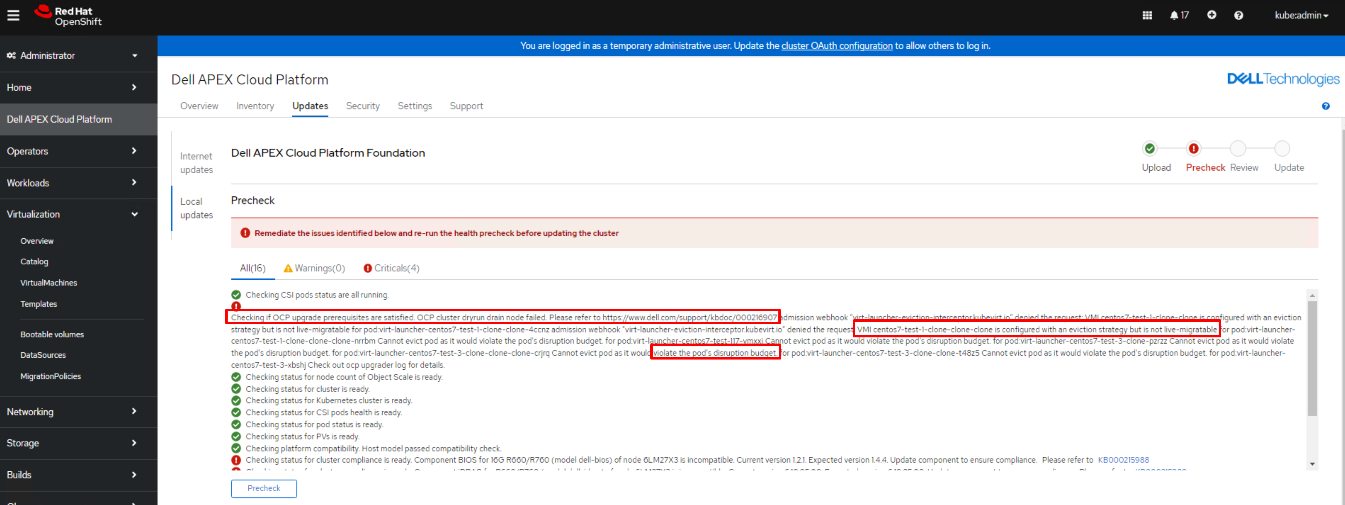
El mensaje de error puede incluir, entre otros, los siguientes escenarios:
El mensaje de error puede incluir, entre otros, los siguientes escenarios:
- Situación 1: "VMI XXXXXX está configurado con una estrategia de expulsión, pero no se puede migrar en vivo".
- Situación 2: "No se puede desalojar el pod, ya que violaría el presupuesto de interrupción del pod".
- Situación 3: No se encontró "pods xxx" para pod:xxxxxxxxxxxx
Cause
Causa raíz del escenario 1: La VM está configurada con un volumen de almacenamiento ReadWriteOnce (RWO) que no se puede migrar en vivo en el nodo de generación de informes de errores.
Causa raíz del escenario 2: El ajuste "PodDistruptionBudget" del pod se configura como "minAvailable: 1", Bloqueará el proceso de expulsión de pods.
Causa raíz de Senario 3: El trabajo programado de Openshift iniciará un pod y el pod finalizará después de que se complete el trabajo. Por lo tanto, existe la posibilidad de que el pod no se pueda encontrar durante el paso del nodo de drenaje de simulacro de comprobación previa.
Causa raíz del escenario 2: El ajuste "PodDistruptionBudget" del pod se configura como "minAvailable: 1", Bloqueará el proceso de expulsión de pods.
Causa raíz de Senario 3: El trabajo programado de Openshift iniciará un pod y el pod finalizará después de que se complete el trabajo. Por lo tanto, existe la posibilidad de que el pod no se pueda encontrar durante el paso del nodo de drenaje de simulacro de comprobación previa.
Resolution
Resolución de escenario 1
1. Detenga la instancia de VM antes de cambiar su configuración de PV.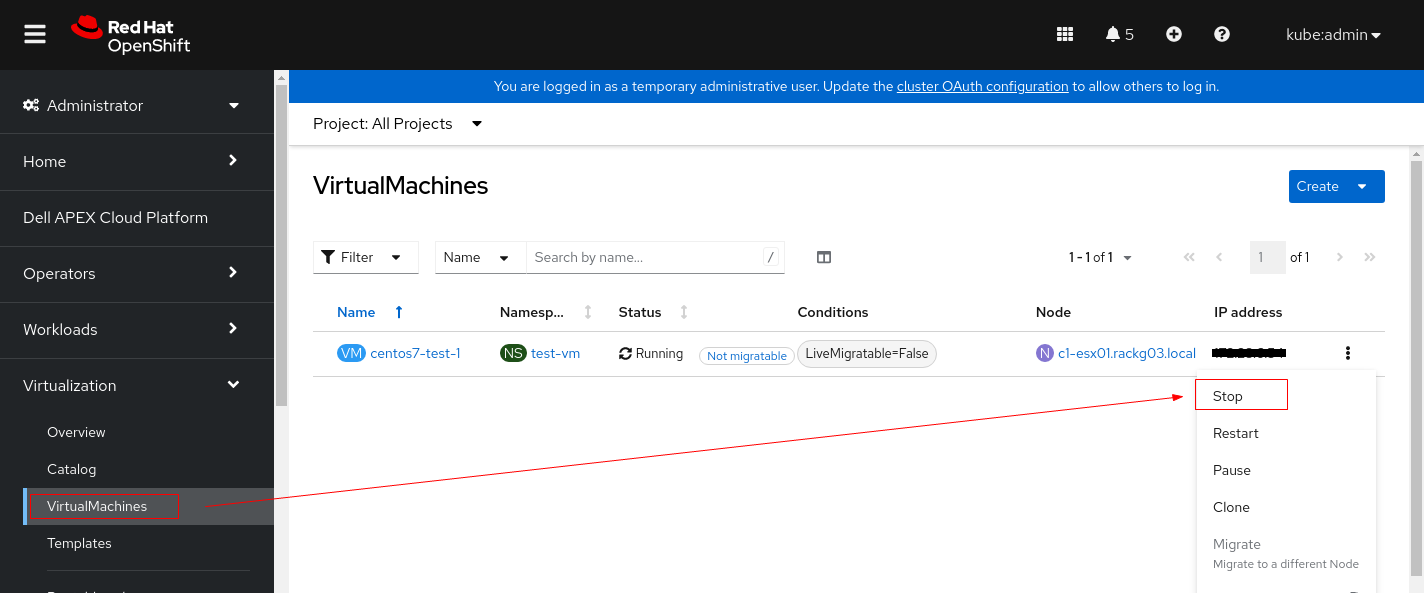
2. Haga clic en la máquina virtual y cambie a la pestaña YAML.
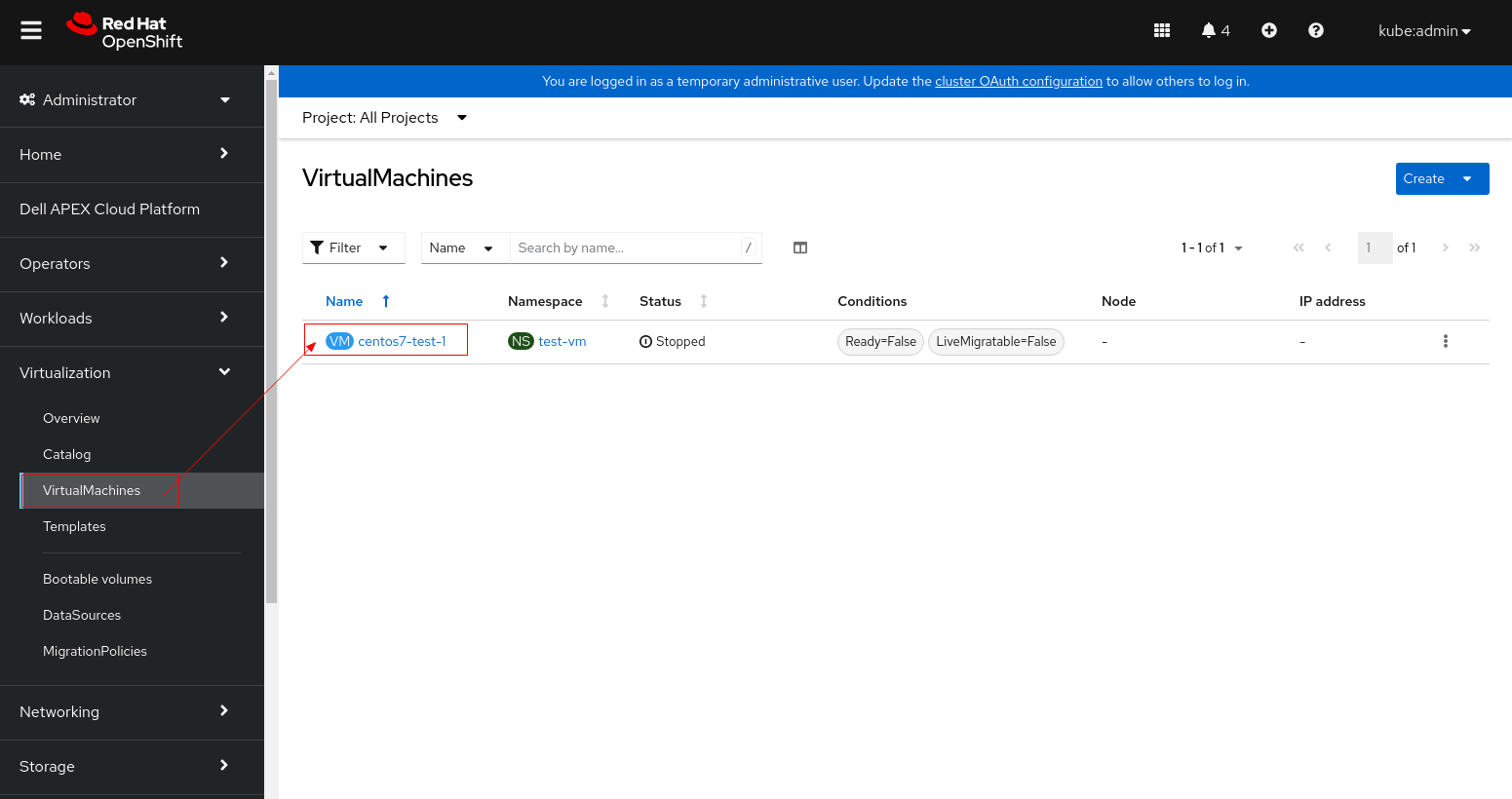
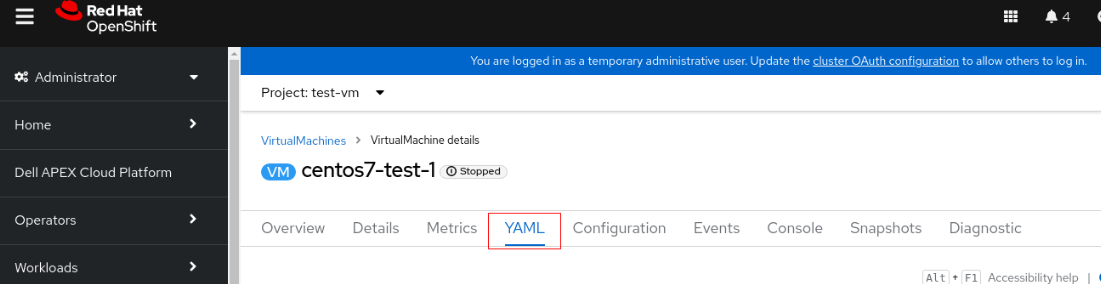
3. Cambie accessModes de "ReadWriteOnce" a "ReadWriteMany".
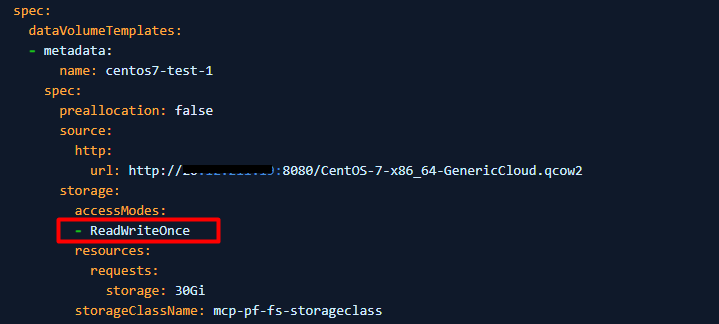
4. Si PV no se puede configurar en ReadWriteMany (la VM no puede comenzar a usar ReadWriteMany), configure evictionStrategy de "LiveMigrate" a "None".
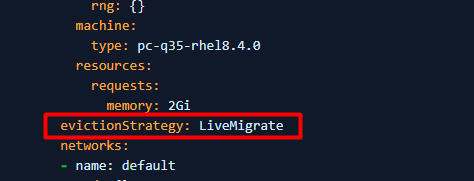
Nota: Realice el paso 3 o 4 que corresponda a su entorno, no es necesario realizar ambos pasos.
5. Haga clic en guardar y reinicie la máquina virtual.
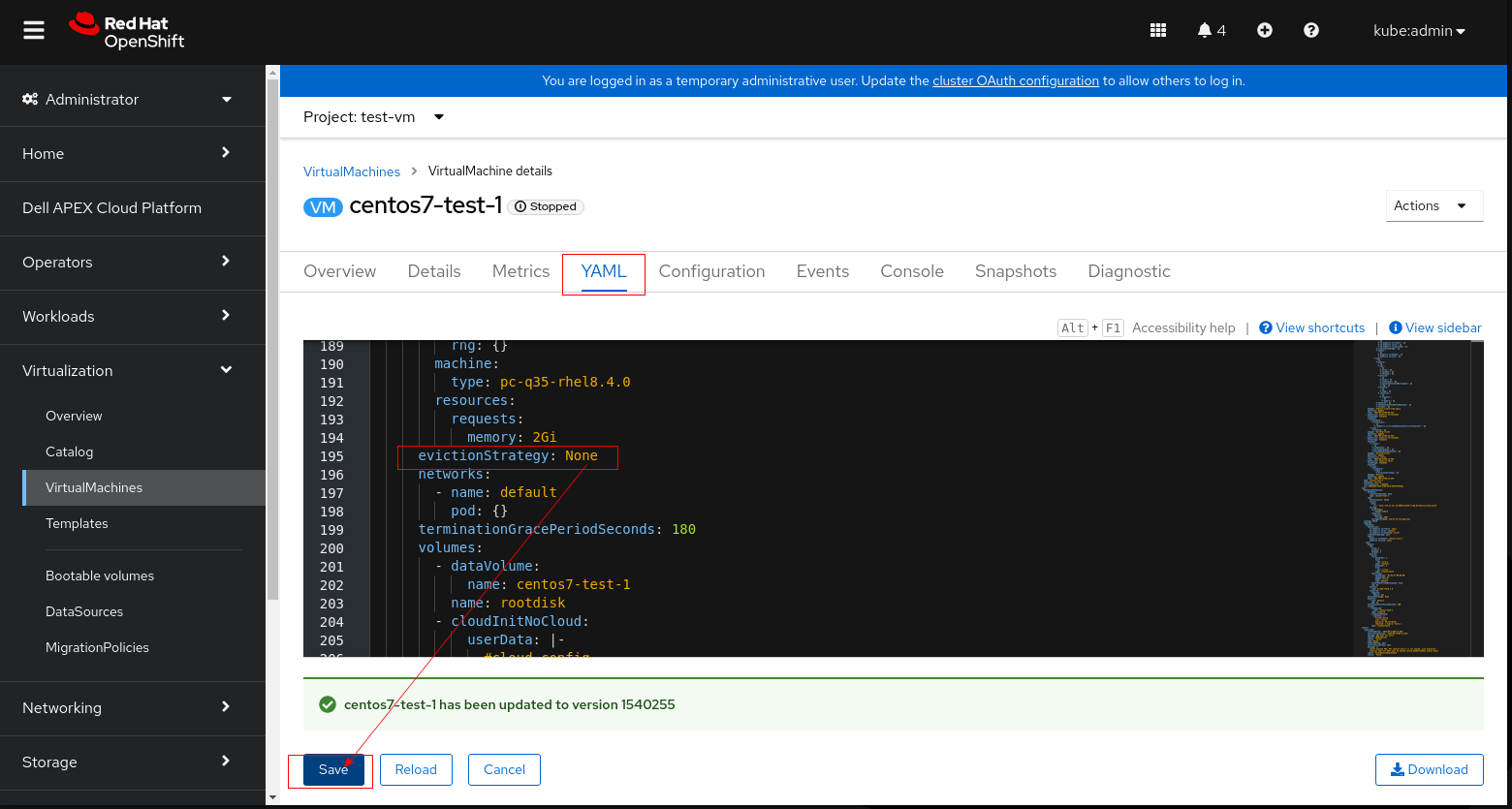
6. Vuelva a intentar la comprobación previa de la LCM y continúe con la actualización.
Resolución de la situación 2
Realice uno de los siguientes procedimientos que corresponda a su entorno.
Procedimiento 1: Elimine manualmente las cápsulas que no se pueden expulsar.
- Ejecute el siguiente comando para eliminar los pods que no se pueden expulsar y permita que se vuelvan a crear en diferentes nodos.
$ oc delete pod <pod_name> -n <pod_namespace>
- Vuelva a intentar la comprobación previa de la LCM y continúe con la actualización.
Procedimiento 2: Si el pod no se puede eliminar manualmente, aplique un parche al pod cuyo "PodDisruptionBudget" esté configurado como "minAvailable: 1"
- Ejecute el siguiente comando para comprobar el valor "PodDisruptionBudget" del pod
Por ejemplo:
$ oc get pdb <pdb_name> -n <pod_namespace> NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE <pdb_name> 1 N/A 0 18h
- Si el resultado del comando muestra que "MIN AVAILABLE" es "1", aplique un parche el valor minAvailable de PodDisruptionBudget a "0" mediante el siguiente comando.
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":0}}'
- Vuelva a intentar la comprobación previa de la LCM y continúe con la actualización.
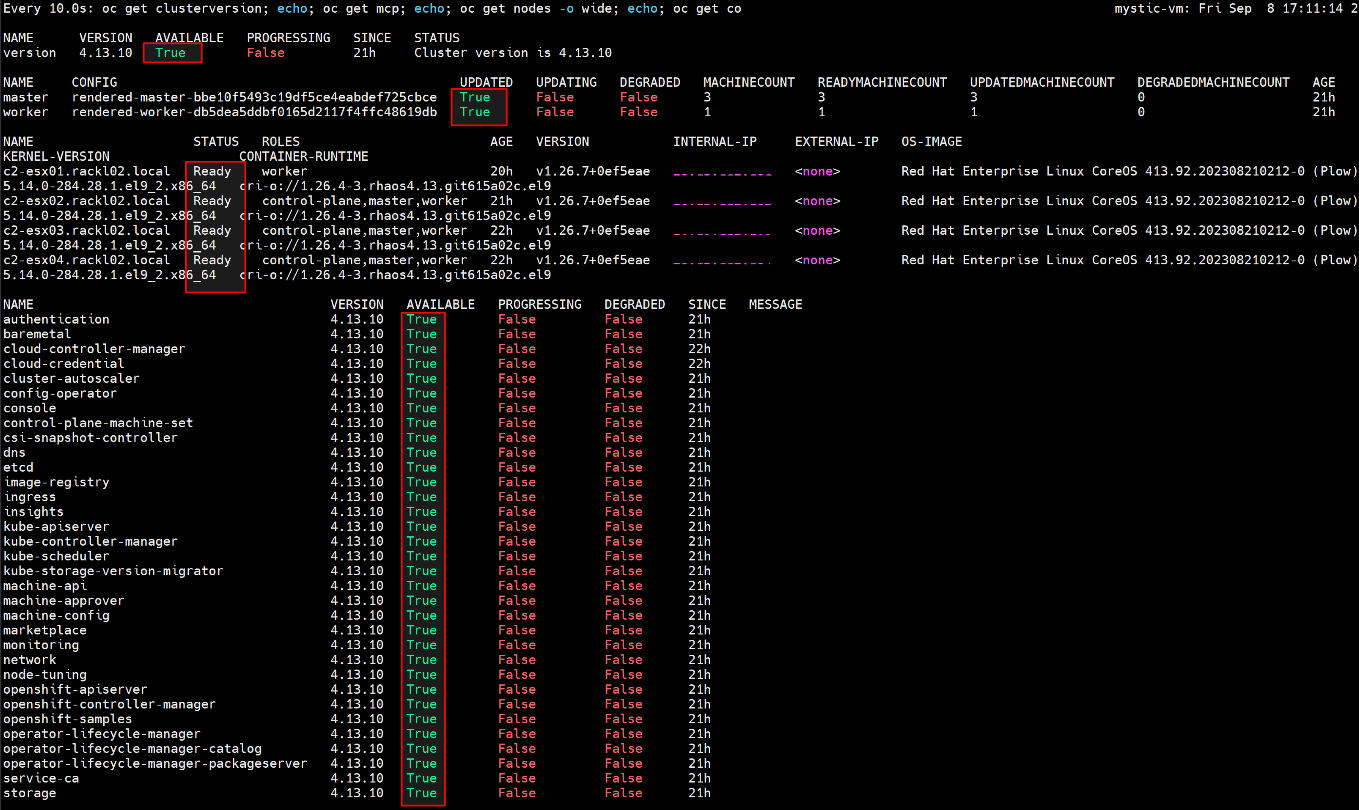
- Espere hasta que finalice la actualización y la MCO esté disponible, ejecute el siguiente comando para verificar que todo esté bien.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Por ejemplo:
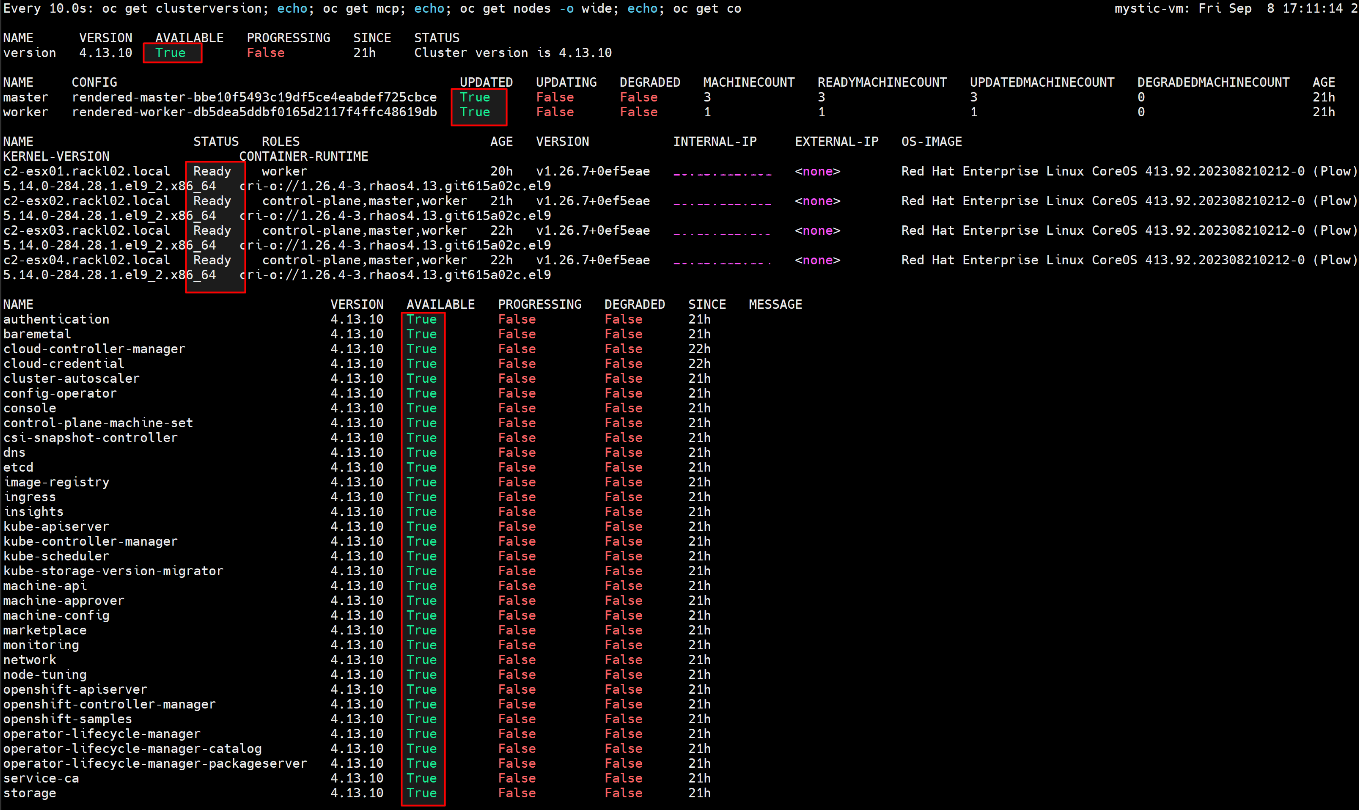
- Una vez finalizada la actualización de OCP, restaure el valor minAvailable de PodDisruptionBudget a "1"
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":1}}'
Procedimiento 3: Si la aplicación de parches al pod produjo el error "PodDisruptionBudget.policy "<pdb_name>" no es válido: especifique: Prohibido: se prohíben las actualizaciones de las especificaciones de PodDisruptionBudget.", siga los pasos que se indican a continuación para aplicar una solución alternativa.
- Respalde el PodDisruptionBudget que está configurado con "minAvailable: 1"
$ oc get pdb <pdb_name> -n <pod_namespace> -o yaml > <pdb_name>_backup.yaml
- Elimine el PodDisruptionBudget que está configurado con "minAvailable: 1"
$ oc delete pdb <pdb_name> -n <pod_namespace>
- Vuelva a intentar la comprobación previa de la LCM y continúe con la actualización.
- Espere hasta que finalice la actualización y la MCO esté disponible, ejecute el siguiente comando para verificar que todo esté bien.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Por ejemplo:
- Una vez finalizada la actualización de OCP, restaure el archivo yaml de respaldo.
$ oc create -f <pdb_name>_backup.yaml -n <pod_namespace>
Resolución del escenario 3
Simplemente vuelva a intentar la comprobación previa de LCM; esta vez debería pasar.
Additional Information
Consulte el siguiente documento de Openshift para obtener más información sobre los volúmenes de almacenamiento para discos de máquinas virtuales.
Affected Products
APEX Cloud Platform for Red Hat OpenShiftArticle Properties
Article Number: 000216907
Article Type: Solution
Last Modified: 18 Feb 2026
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.