Turno aperto: Controllo preliminare dell'aggiornamento OCP non riuscito per errore del nodo di drain dryrun
Summary: Controllo preliminare dell'aggiornamento OCP non riuscito per un errore del nodo di drain dryrun, a causa dell'impossibilità di eseguire la migrazione live di alcune macchine virtuali o dell'impossibilità di rimuovere alcuni pod. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Durante il controllo preliminare LCM, potrebbe verificarsi un guasto del nodo di svuotamento dryrun che bloccherà il processo LCM.
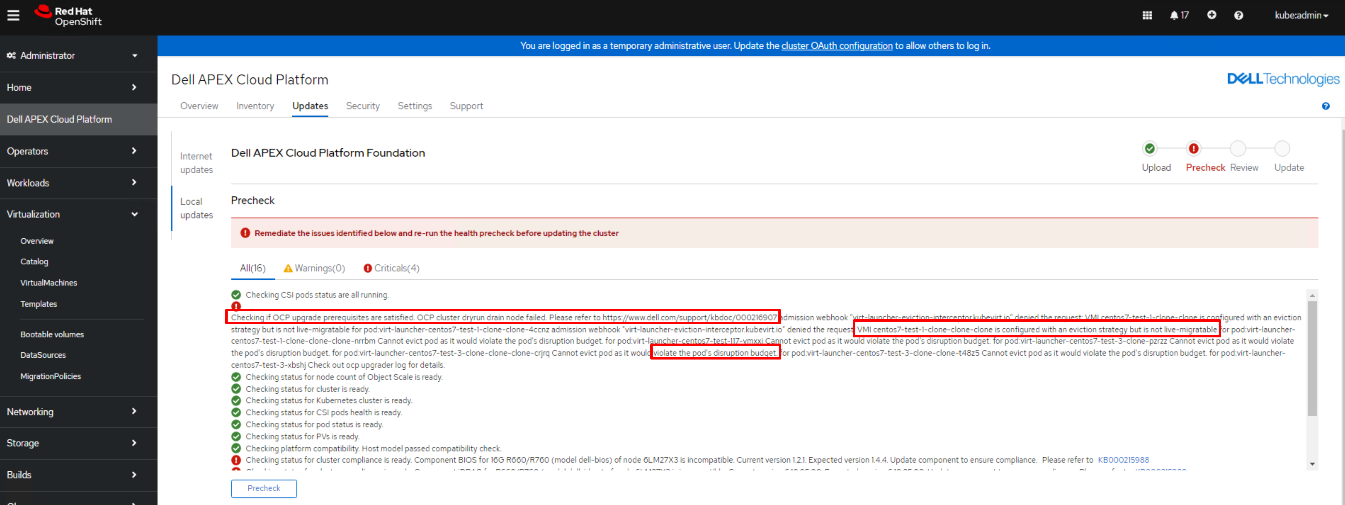
Il messaggio di errore potrebbe includere, a titolo esemplificativo, i seguenti scenari:
Il messaggio di errore potrebbe includere, a titolo esemplificativo, i seguenti scenari:
- Scenario 1: "VMI XXXXXX è configurato con una strategia di rimozione, ma non è possibile eseguire la migrazione in tempo reale".
- Scenario 2: "Non è possibile sfrattare il pod in quanto violerebbe il budget di interruzione del pod."
- Scenario 3: "Pod XXX" non trovato per pod:XXXXXXXXXXXXX
Cause
Scenario 1 root cause: La VM è configurata con un volume di storage ReadWriteOnce(RWO) di cui non è possibile eseguire la migrazione in tempo reale sul nodo di segnalazione degli errori.
Scenario 2 root cause: L'impostazione "PodDistruptionBudget" del pod è configurata come "minAvailable: 1", Bloccherà il processo di sfratto del pod.
Causa principale di Senario 3: Il lavoro pianificato OpenShift avvierà un pod e il pod verrà terminato al completamento del processo. Quindi c'è la possibilità che il pod non possa essere trovato durante il passaggio del nodo di drenaggio dryrun di controllo preliminare.
Scenario 2 root cause: L'impostazione "PodDistruptionBudget" del pod è configurata come "minAvailable: 1", Bloccherà il processo di sfratto del pod.
Causa principale di Senario 3: Il lavoro pianificato OpenShift avvierà un pod e il pod verrà terminato al completamento del processo. Quindi c'è la possibilità che il pod non possa essere trovato durante il passaggio del nodo di drenaggio dryrun di controllo preliminare.
Resolution
Risoluzione dello scenario 1
1. Arrestare l'istanza della VM prima di modificarne le impostazioni PV.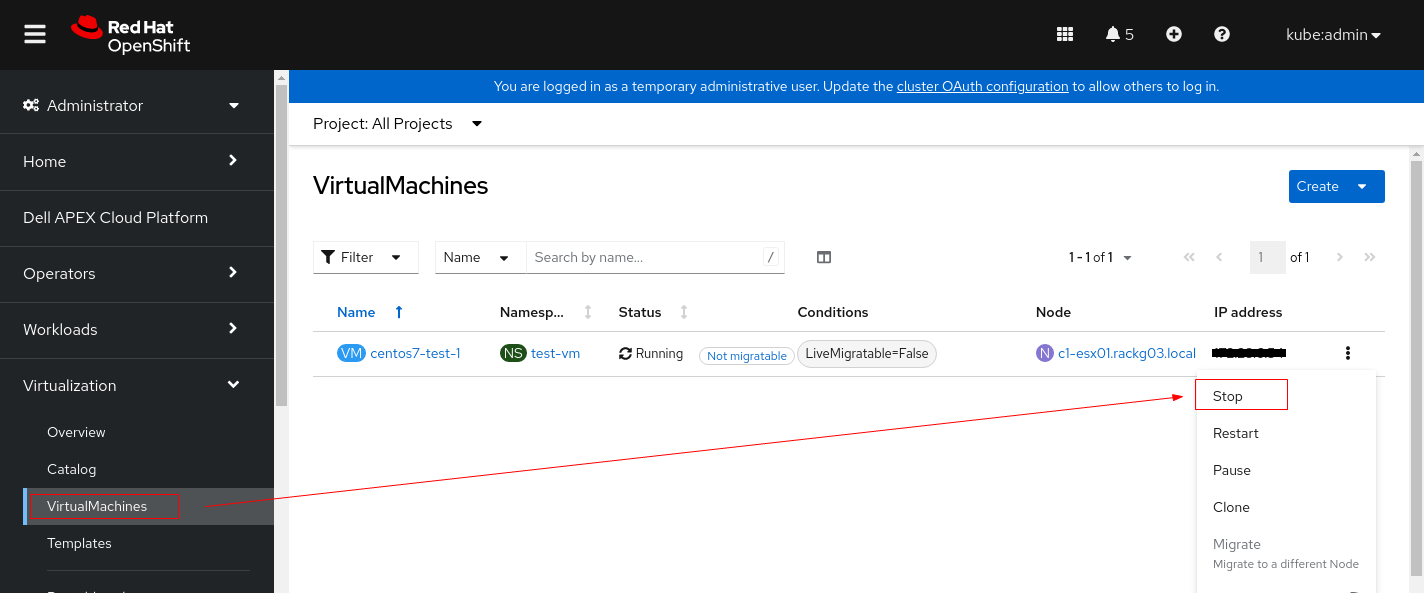
2. Cliccare sulla VM e passare alla scheda YAML.
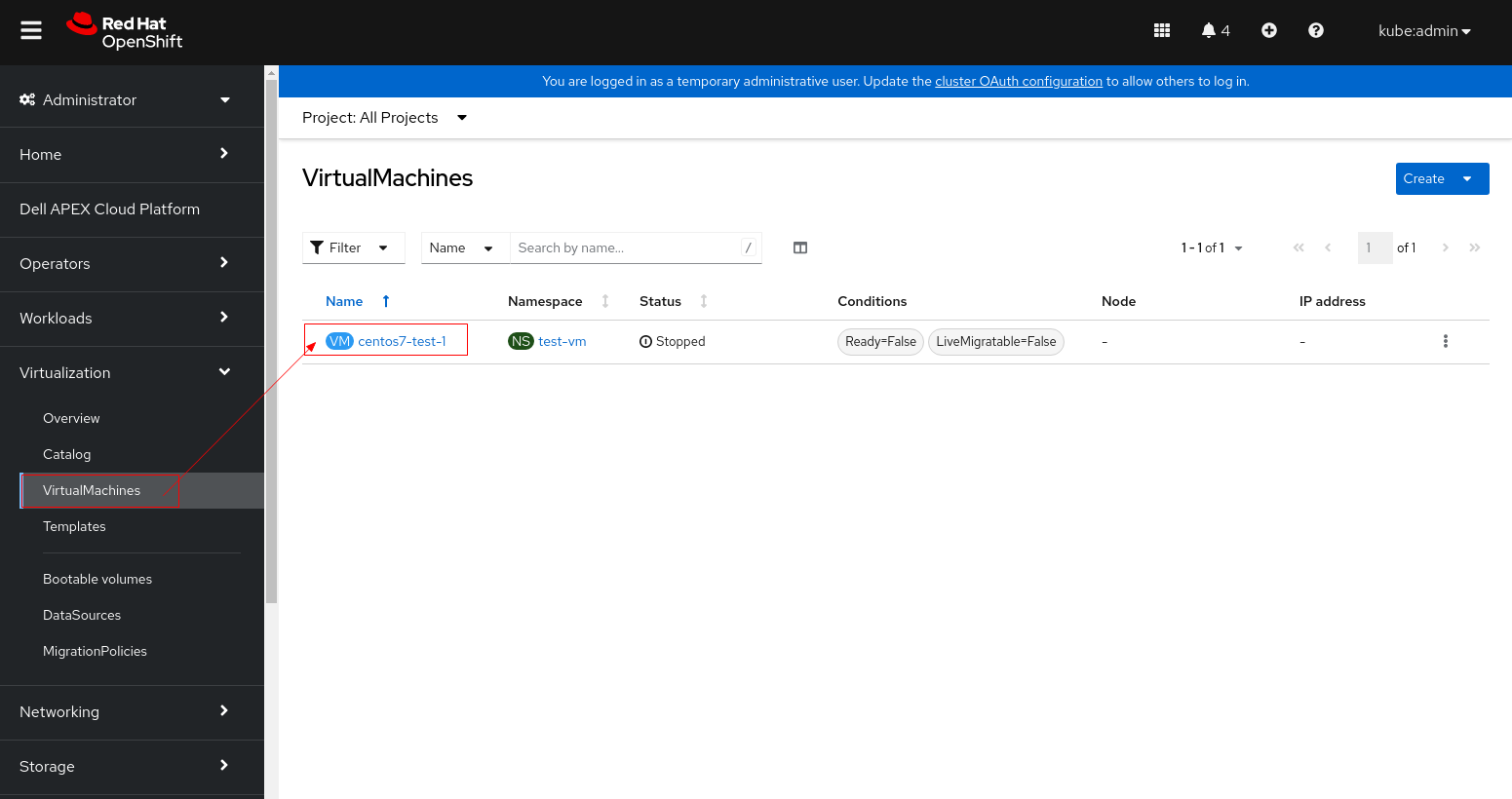
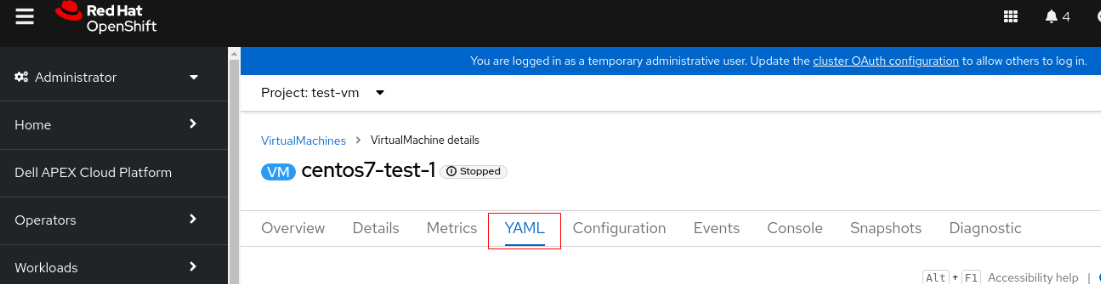
3. Modificare accessModes da "ReadWriteOnce" a "ReadWriteMany".
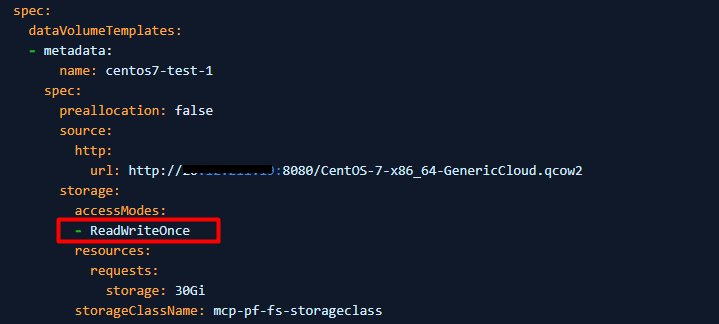
4. Se PV non può essere impostato su ReadWriteMany (la macchina virtuale non può iniziare a utilizzare ReadWriteMany), impostare evictionStrategy da "LiveMigrate" su "None".
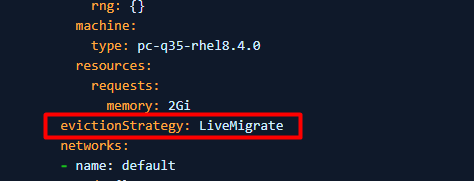
Nota: Eseguire il passaggio 3 o 4 che si applica al proprio ambiente, non è necessario eseguire entrambi i passaggi.
5. Cliccare su Save e riavviare la VM.
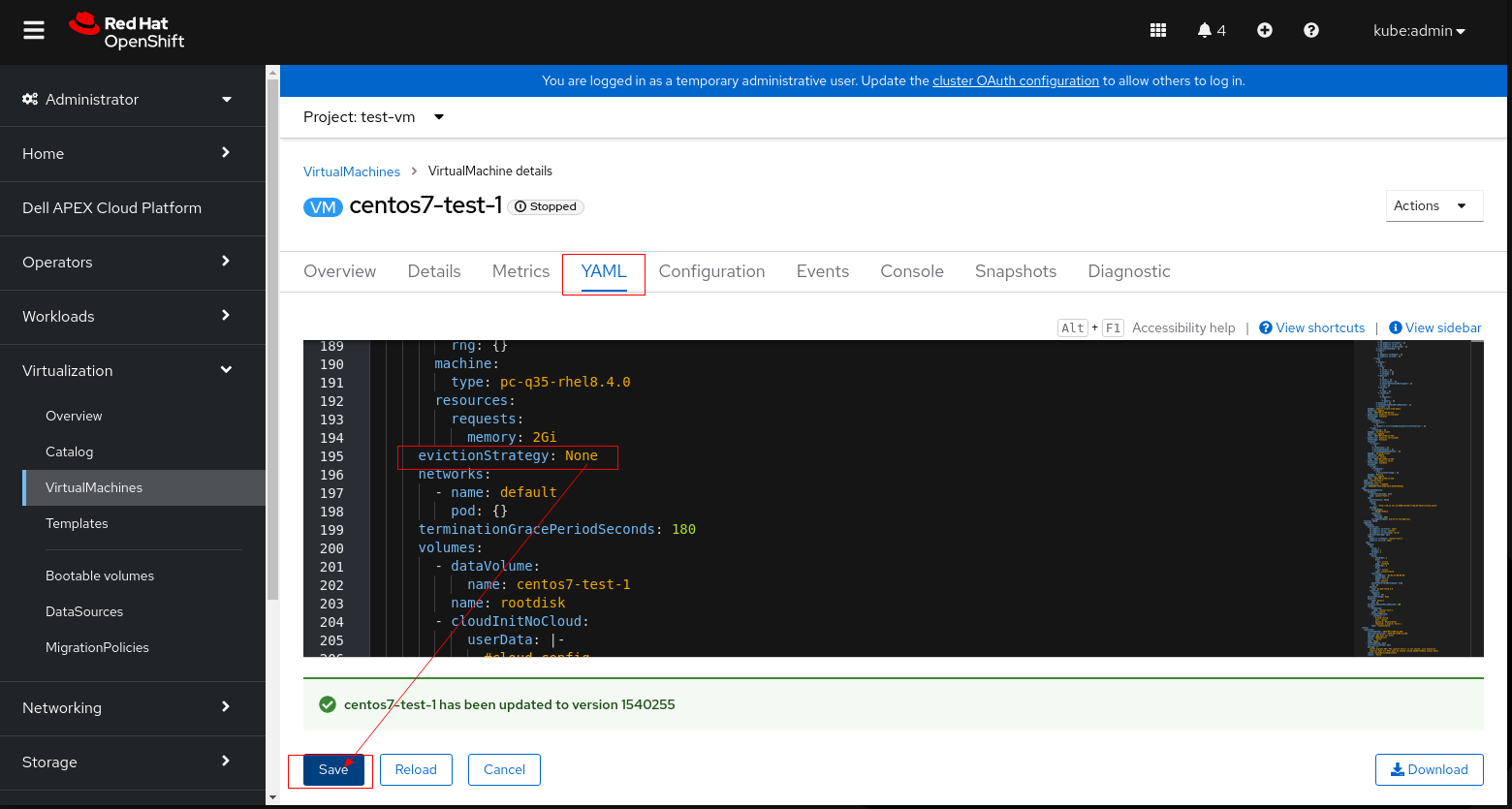
6. Riprovare il controllo preliminare LCM e procedere con l'aggiornamento.
Risoluzione dello scenario 2
Eseguire una delle seguenti procedure applicabili all'ambiente in uso.
Procedura 1: Eliminare manualmente i pod o i pod che non possono essere rimossi.
- Eseguire il comando seguente per eliminare i pod o i pod che non possono essere rimossi e consentire loro di ricrearli in nodi diversi.
$ oc delete pod <pod_name> -n <pod_namespace>
- Riprovare il controllo preliminare LCM e procedere con l'aggiornamento.
Procedura 2: Se il pod non può essere eliminato manualmente, applicare una patch al pod il cui "PodDisruptionBudget" è configurato come "minAvailable: 1"
- Eseguire il comando riportato di seguito per controllare il valore "PodDisruptionBudget" del pod
Ad esempio:
$ oc get pdb <pdb_name> -n <pod_namespace> NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE <pdb_name> 1 N/A 0 18h
- Se l'output del comando mostra che "MIN AVAILABLE" è "1", correggere il valore minAvailable di PodDisruptionBudget su "0" eseguendo il comando riportato di seguito.
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":0}}'
- Riprovare il controllo preliminare LCM e procedere con l'aggiornamento.
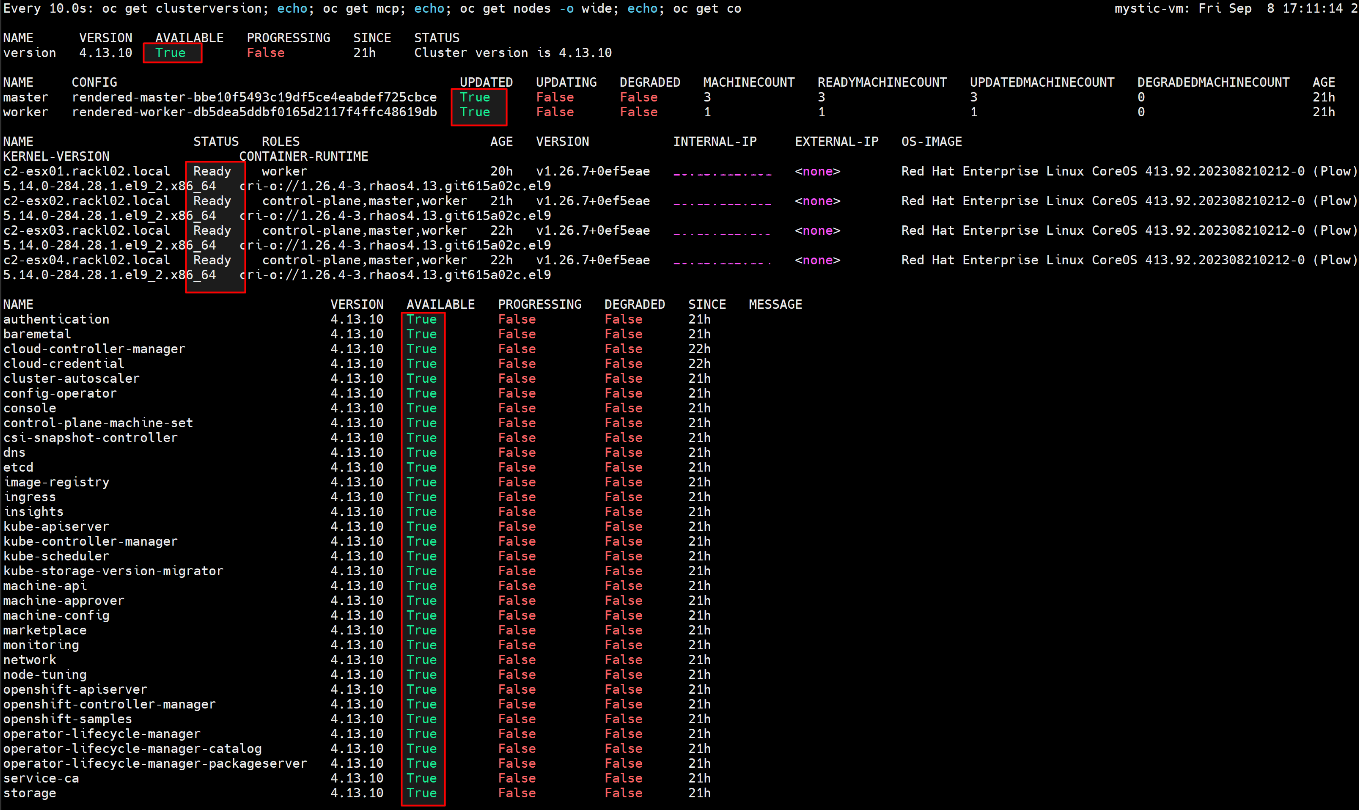
- Attendere il completamento dell'aggiornamento e la disponibilità dell MCO. Eseguire il comando seguente per verificare che tutto funzioni correttamente.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Ad esempio:
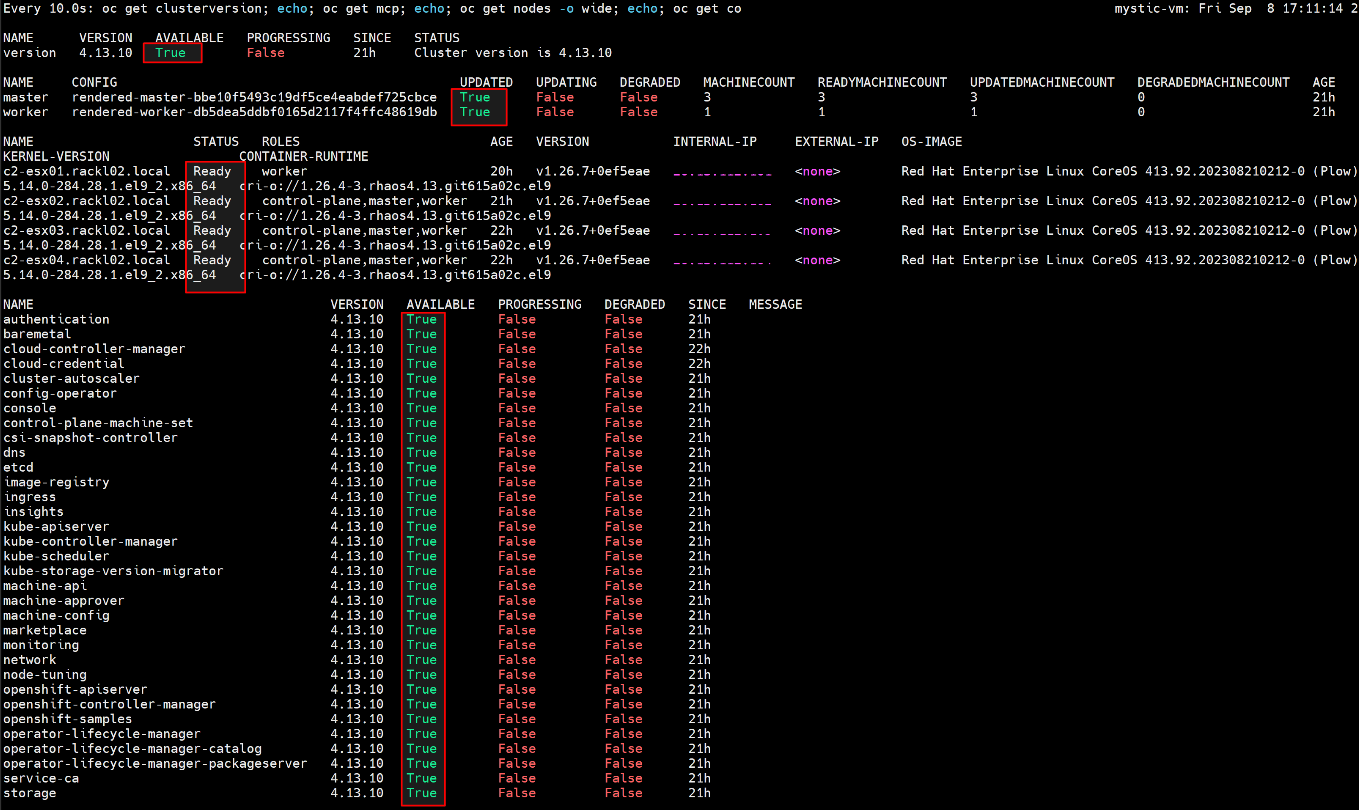
- Al termine dell'aggiornamento OCP, ripristinare il valore MinAvailable di PodDisruptionBudget su "1"
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":1}}'
Procedura 3: Se l'applicazione di patch all'errore pod hit "PodDisruptionBudget.policy "<pdb_name>" non è valida: specifica: Accesso consentito: gli aggiornamenti alla specifica poddisruptionbudget sono vietati.", segui i passaggi seguenti per la soluzione alternativa.
- Eseguire il backup di PodDisruptionBudget configurato con "minAvailable: 1"
$ oc get pdb <pdb_name> -n <pod_namespace> -o yaml > <pdb_name>_backup.yaml
- Rimuovere il PodDisruptionBudget configurato con "minAvailable: 1"
$ oc delete pdb <pdb_name> -n <pod_namespace>
- Riprovare il controllo preliminare LCM e procedere con l'aggiornamento.
- Attendere il completamento dell'aggiornamento e la disponibilità dell MCO. Eseguire il comando seguente per verificare che tutto funzioni correttamente.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Ad esempio:
- Al termine dell'aggiornamento OCP, ripristinare il file yaml di backup.
$ oc create -f <pdb_name>_backup.yaml -n <pod_namespace>
Risoluzione dello scenario 3
È sufficiente riprovare la verifica preliminare di LCM; questa volta dovrebbe avere esito positivo.
Additional Information
Per ulteriori informazioni sui volumi di storage per i dischi delle macchine virtuali, consultare il documento Openshift riportato di seguito.
Affected Products
APEX Cloud Platform for Red Hat OpenShiftArticle Properties
Article Number: 000216907
Article Type: Solution
Last Modified: 18 Feb 2026
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.