Turno aberto: Falha na pré-verificação de upgrade do OCP devido a erro de nó de drenagem dryrun
Summary: Falha na pré-verificação de upgrade do OCP devido ao erro de nó de drenagem dryrun, porque algumas VMs não podem ser migradas em tempo real ou algum pod não pode ser removido.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Durante a pré-verificação do LCM, pode haver uma falha no nó de drenagem dryrun que bloqueará o processo de LCM.
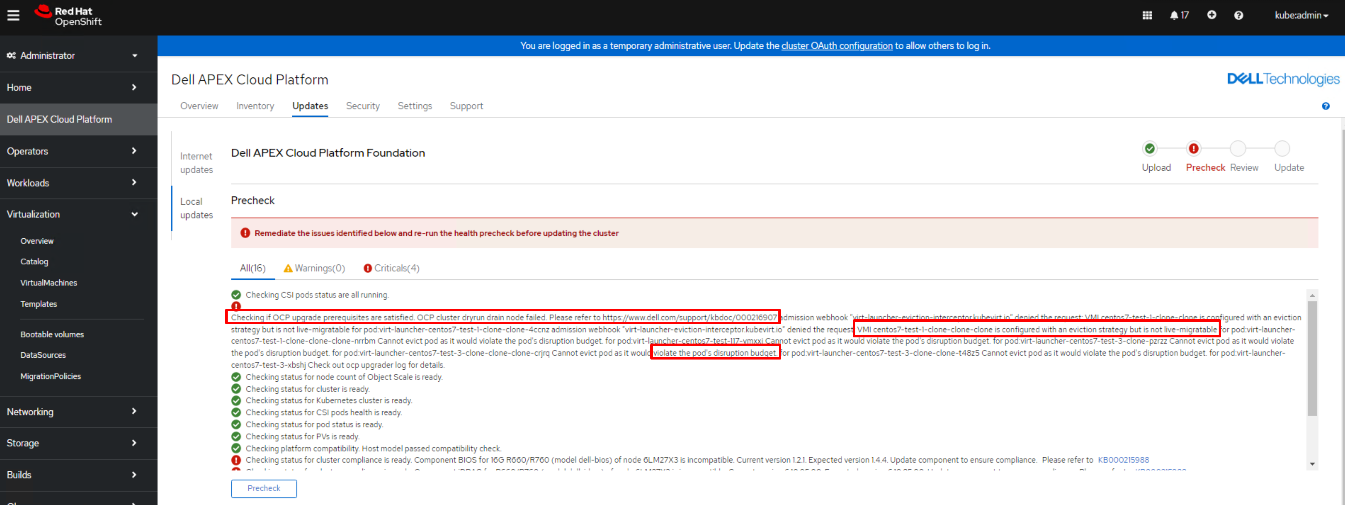
A mensagem de erro pode incluir, mas não se limitar aos seguintes cenários:
A mensagem de erro pode incluir, mas não se limitar aos seguintes cenários:
- Cenário 1: "O VMI XXXXXX está configurado com uma estratégia de remoção, mas não é passível de migração em tempo real."
- Cenário 2: "Não posso despejar o pod, pois isso violaria o orçamento de interrupção do pod."
- Cenário 3: "pods xxx" não encontrado para pod:xxxxxxxxxxxx
Cause
Causa raiz do cenário 1: A VM é configurada com o volume de armazenamento ReadWriteOnce(RWO) que não pode ser migrado em tempo real no nó de geração de relatórios de erros.
Causa raiz do cenário 2: A configuração do pod "PodDistruptionBudget" é definida como "minAvailable: 1", Isso bloqueará o processo de remoção do pod.
Causa raiz do Senario 3: O trabalho agendado do Openshift iniciará um pod e o pod será encerrado após a conclusão do trabalho. Portanto, há uma chance de que o pod não possa ser encontrado durante a etapa de pré-verificação dryrun drenando o nó.
Causa raiz do cenário 2: A configuração do pod "PodDistruptionBudget" é definida como "minAvailable: 1", Isso bloqueará o processo de remoção do pod.
Causa raiz do Senario 3: O trabalho agendado do Openshift iniciará um pod e o pod será encerrado após a conclusão do trabalho. Portanto, há uma chance de que o pod não possa ser encontrado durante a etapa de pré-verificação dryrun drenando o nó.
Resolution
Resolução do cenário 1
1. Interrompa a instância da VM antes de alterar suas configurações de PV.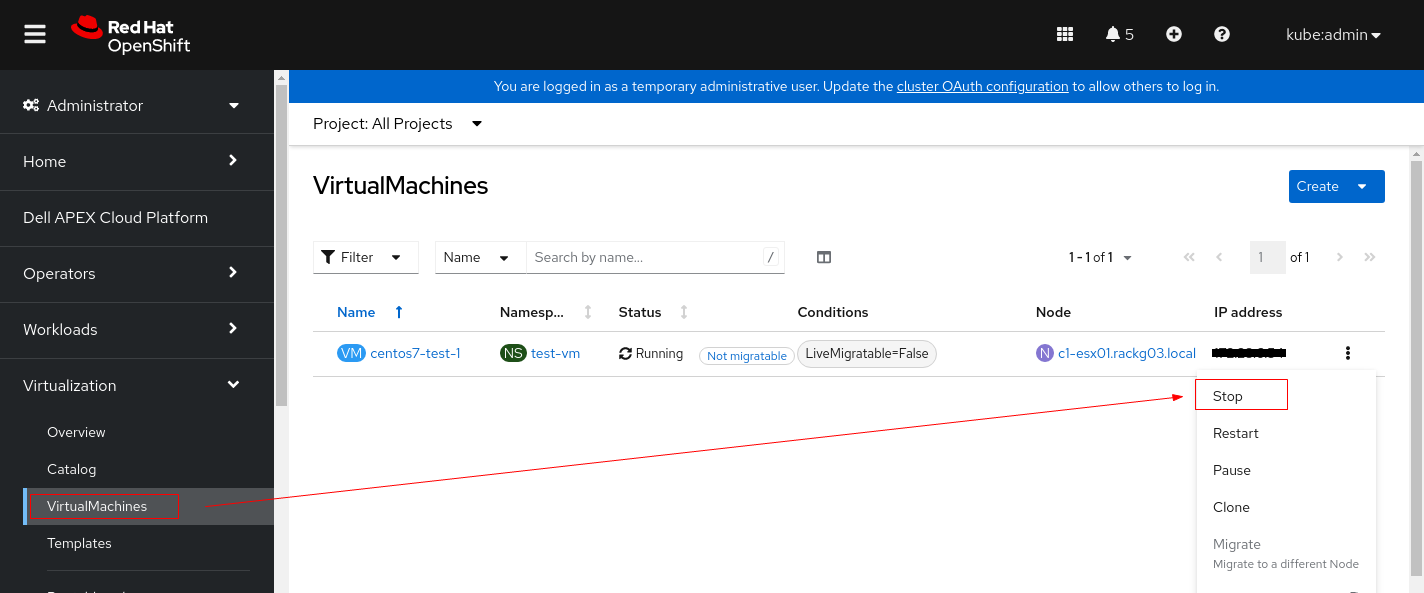
2. Clique na VM e alterne para a guia YAML.
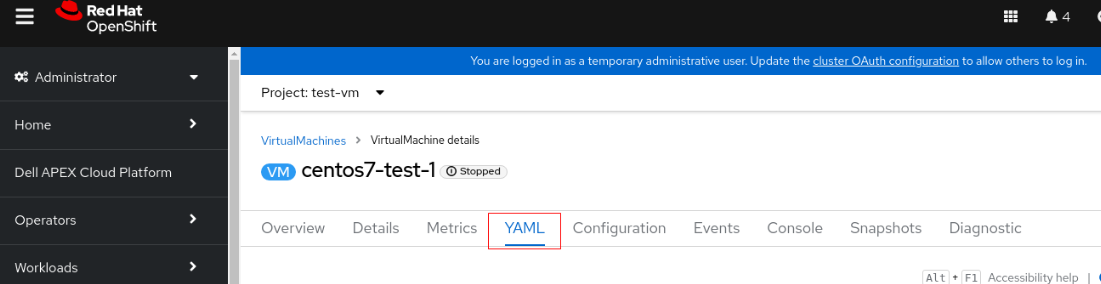
3. Altere accessModes de "ReadWriteOnce" para "ReadWriteMany".
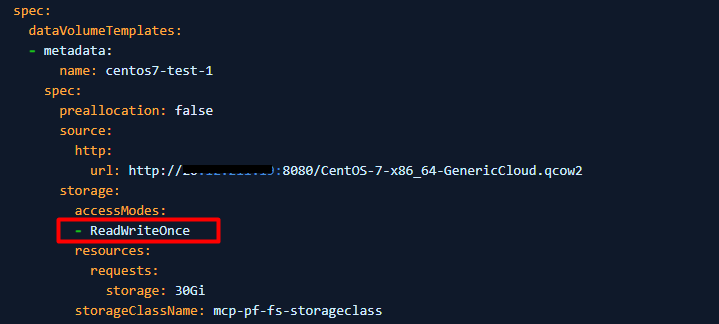
4. Se PV não puder ser definido como ReadWriteMany (a VM não pode iniciar usando ReadWriteMany), defina evictionStrategy de "LiveMigrate" para "None".
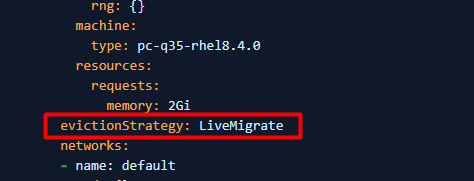
Nota: Execute a etapa 3 ou 4 que se aplica ao seu ambiente, não precisa executar as duas etapas.
5. Clique em Save e reinicie a VM.
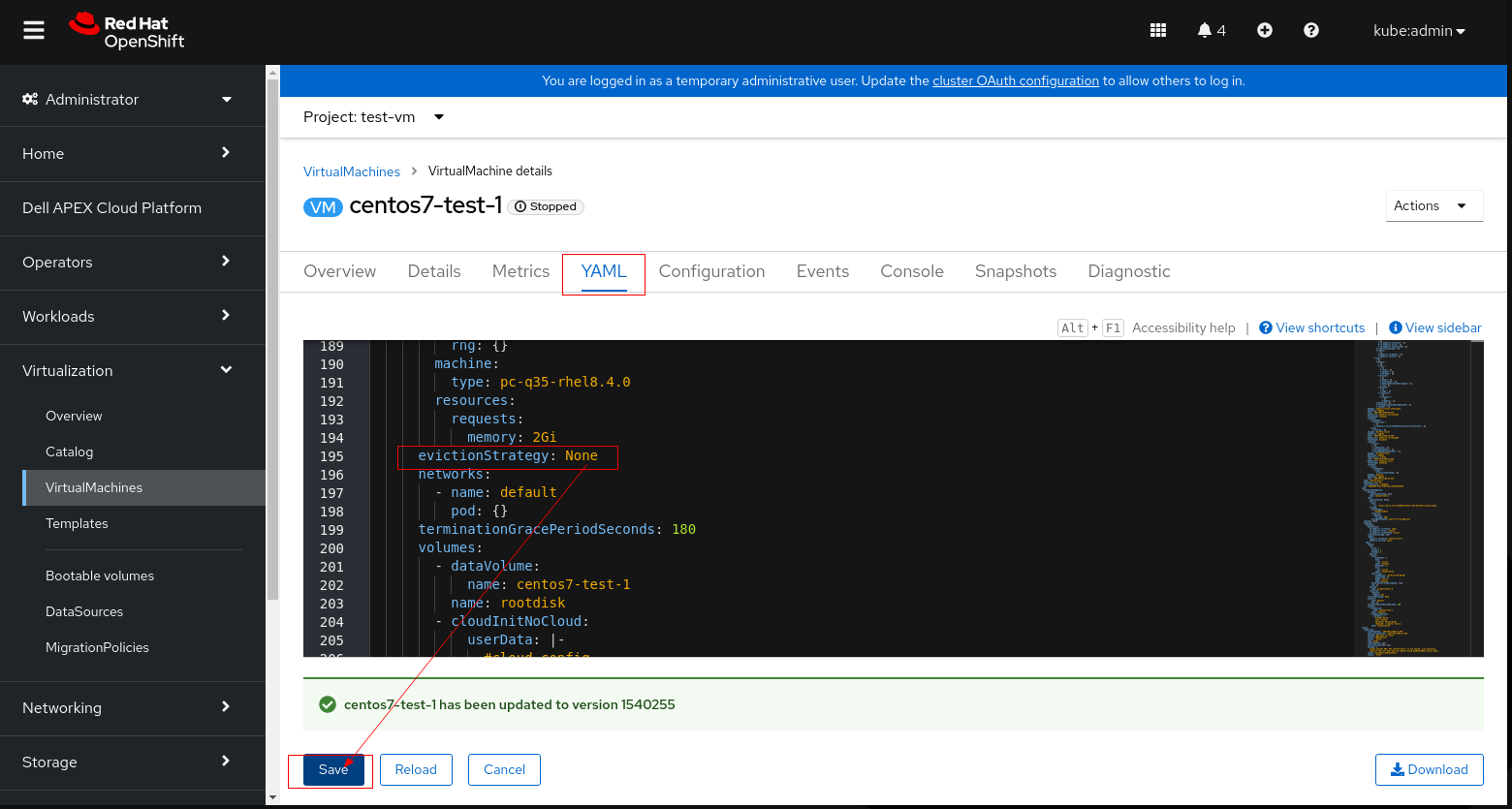
6. Repita a pré-verificação do LCM e prossiga com o upgrade.
Resolução do cenário 2
Execute um dos procedimentos a seguir que se aplica ao seu ambiente.
Procedimento 1: Exclua manualmente os pods que não podem ser removidos.
- Execute o comando abaixo para excluir os pods que não podem ser removidos e permitir que eles sejam criados novamente em nós diferentes.
$ oc delete pod <pod_name> -n <pod_namespace>
- Repita a pré-verificação do LCM e prossiga com o upgrade.
Procedimento 2: Se o pod não puder ser excluído manualmente, corrija o pod cujo "PodDisruptionBudget" está configurado como "minAvailable: 1"
- Execute o comando abaixo para verificar o valor "PodDisruptionBudget" do pod
Por exemplo:
$ oc get pdb <pdb_name> -n <pod_namespace> NAME MIN AVAILABLE MAX UNAVAILABLE ALLOWED DISRUPTIONS AGE <pdb_name> 1 N/A 0 18h
- Se a saída do comando mostrar que "MIN AVAILABLE" é "1", corrija o valor minAvailable de PodDisruptionBudget para "0" usando o comando abaixo.
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":0}}'
- Repita a pré-verificação do LCM e prossiga com o upgrade.
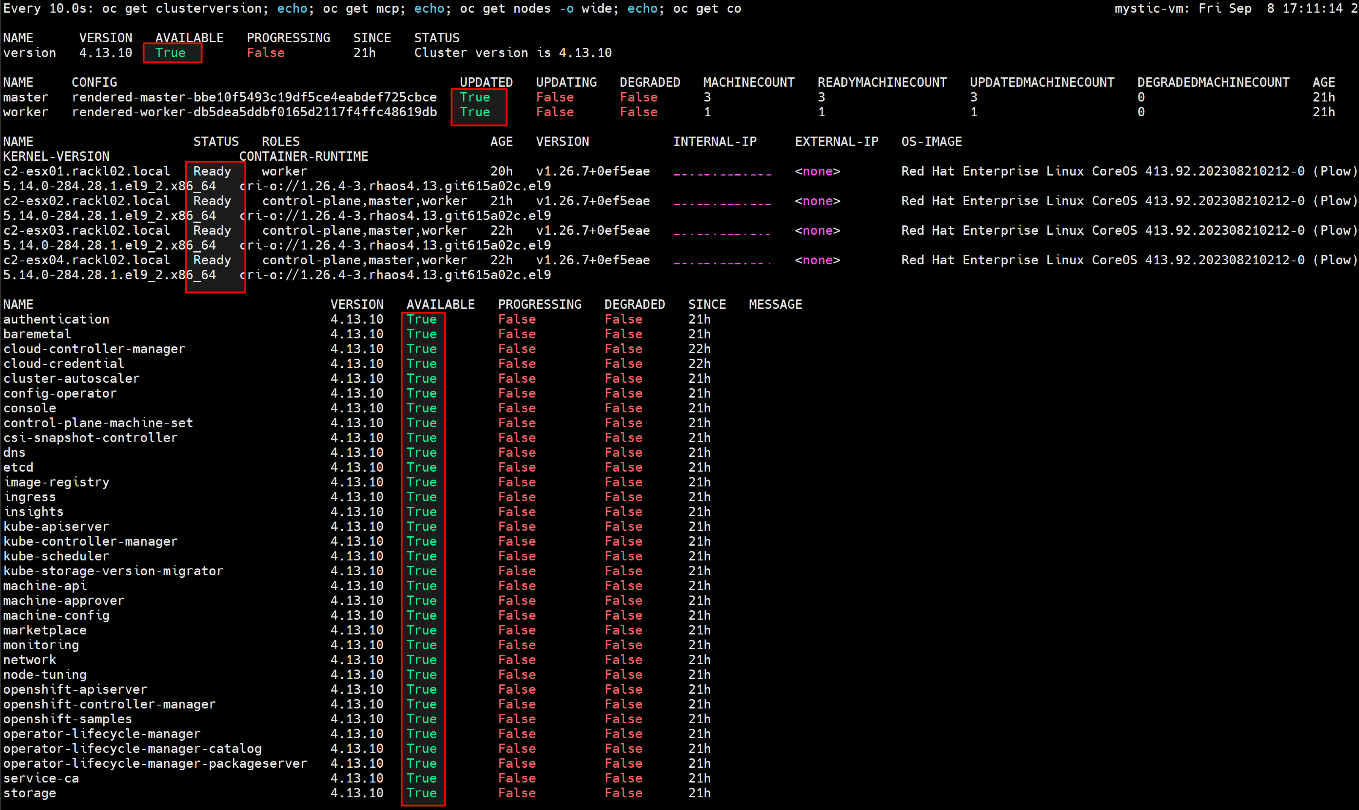
- Aguarde até que o upgrade seja concluído e o MCO esteja disponível, execute o comando abaixo para verificar se está tudo certo.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Por exemplo:
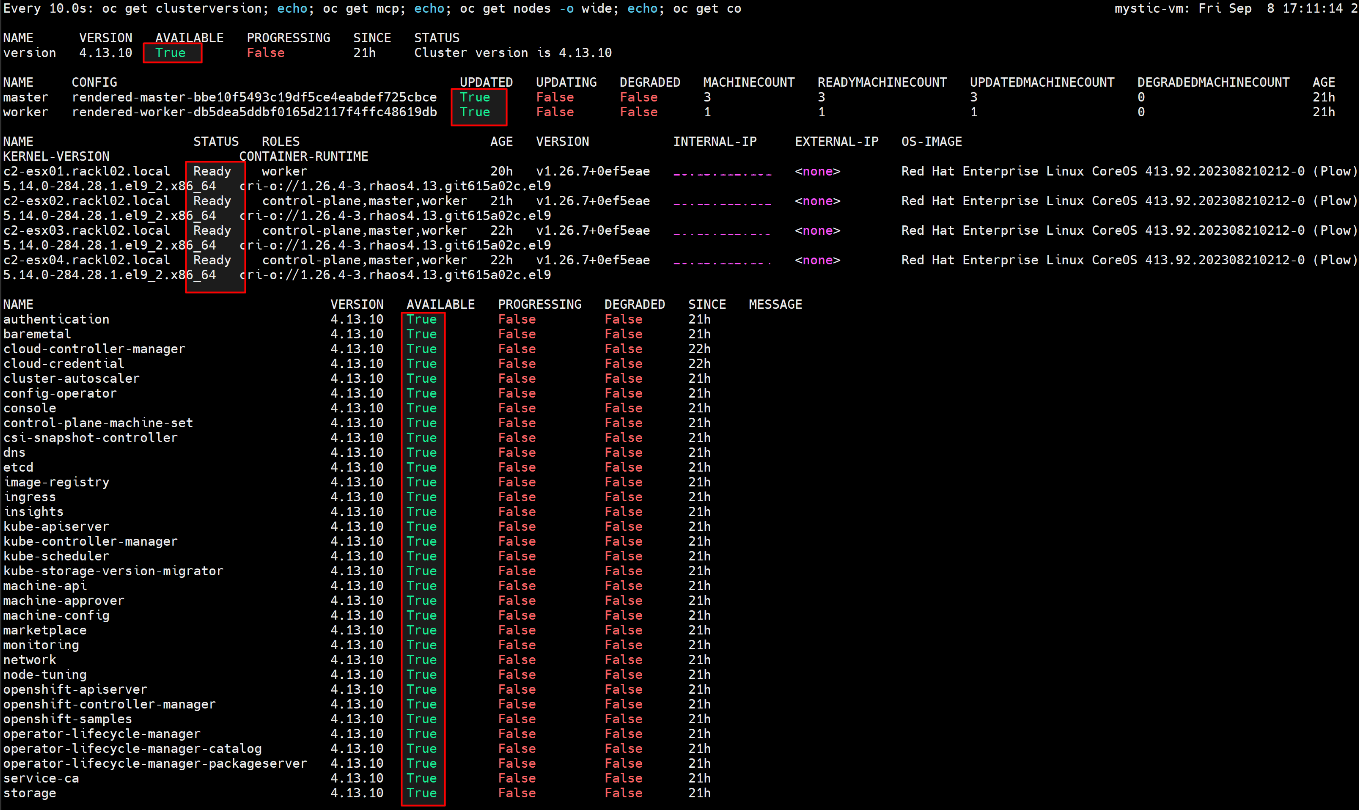
- Depois que o upgrade do OCP for concluído, restaure o valor minAvailable de PodDisruptionBudget para "1"
$ oc patch pdb <pdb_name> -n <pod_namespace> --type=merge -p '{"spec":{"minAvailable":1}}'
Procedimento 3: Se corrigir o erro de pod hit "PodDisruptionBudget.policy "<pdb_name>" for inválido: spec: Proibido: as atualizações nas especificações podDisruptionBudget são proibidas.", siga as etapas abaixo para solução temporária.
- Faça backup do PodDisruptionBudget configurado com "minAvailable: 1"
$ oc get pdb <pdb_name> -n <pod_namespace> -o yaml > <pdb_name>_backup.yaml
- Remova o PodDisruptionBudget configurado com "minAvailable: 1"
$ oc delete pdb <pdb_name> -n <pod_namespace>
- Repita a pré-verificação do LCM e prossiga com o upgrade.
- Aguarde até que o upgrade seja concluído e o MCO esteja disponível, execute o comando abaixo para verificar se está tudo certo.
$ watch -n10 "oc get clusterversion; echo; oc get mcp; echo; oc get nodes -o wide; echo; oc get co"
Por exemplo:
- Depois que o upgrade do OCP for concluído, restaure o arquivo yaml de backup.
$ oc create -f <pdb_name>_backup.yaml -n <pod_namespace>
Resolução do cenário 3
Basta repetir a pré-verificação do LCM, que deve passar desta vez.
Additional Information
Verifique abaixo o documento do Openshift para obter mais informações sobre volumes de armazenamento para discos de máquina virtual.
Affected Products
APEX Cloud Platform for Red Hat OpenShiftArticle Properties
Article Number: 000216907
Article Type: Solution
Last Modified: 18 Feb 2026
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.