PowerFlex: 리소스 경합 문제 해결
요약: PowerFlex 리소스 경합 문제 및 문제 해결
이 문서는 다음에 적용됩니다.
이 문서는 다음에 적용되지 않습니다.
이 문서는 특정 제품과 관련이 없습니다.
모든 제품 버전이 이 문서에 나와 있는 것은 아닙니다.
증상
PowerFlex 프로세스가 다른 소프트웨어 또는 하드웨어 구성 요소와 리소스 경합을 겪을 때 PowerFlex 프로세스의 비정상적인 동작이 발생합니다.
이러한 증상은 다양하고 다양할 수 있습니다. 다음은 증상 및 결과의 일부 목록입니다
MDM 문제:
- MDM 프로세스가 중단되고 다른 MDM과의 통신이 끊어지면 MDM 소유권 장애 조치가 발생합니다.
From exp.0:
Panic in file /emc/svc_flashbld/workspace/ScaleIO-RHEL7/src/mos/umt/mos_umt_sched_thrd.c, line 1798, function mosUmtSchedThrd_SuspendCK, PID 36721.Panic Expression ALWAYS_ASSERT Scheduler guard seems to be dead.
From trc.*
24/02 15:54:16.087919 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x106d9360(0) in scheduler 0x7fff580c4880, running UMT 0x7f39ad00ceb8, found to be stuck.
24/02 15:54:16.088226 ad417eb8:actorLoop_IsSchedThredStuck:10932: Stuck scheduler thread identified
24/02 15:54:16.088253 ad417eb8:actor_Loop:11257: Lost quorum. ourVoters: 0 votersOwnedByOther: [0,0]
24/02 15:54:16.088299 ---Planned crash, reason: Lost quorum, going down to let another MDM become master ---
- MDM 프로세스가 일정 시간 동안 지속적으로 연결 해제되었다가 다시 연결됩니다.
2017-02-23 14:00:43.241 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 14:00:43.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-23 23:05:25.852 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-23 23:05:26.422 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
2017-02-24 15:54:16.141 MDM_CLUSTER_LOST_CONNECTION WARNING The MDM, ID 089012db4d536880, lost connection
2017-02-24 15:54:16.238 MDM_CLUSTER_CONNECTED INFO The MDM, ID 089012db4d536880, connected
SDS 문제:
- SDS는 일정 시간 동안 지속적으로 연결을 끊었다가 다시 연결합니다.
2017-02-15 13:18:16.881 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-16 03:37:37.327 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-16 03:39:54.300 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
2017-02-17 04:03:41.757 SDS_DECOUPLED ERROR SDS: siosds2 (id: 1eb052fe00000001) decoupled.
2017-02-17 04:09:13.604 SDS_RECONNECTED INFO SDS: siosds2 (ID 1eb052fe00000001) reconnected
- SDS는 다른 SDS 노드와의 연결 끊김과 관련하여 trc 파일에 진동 오류를 표시할 수 있습니다.
14/02 19:13:24.096983 1be7eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.196814 1be7eb8:contNet_OscillationNotif:01675: Con 1eb053000000000b - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 19:13:24.296713 1be7eb8:contNet_OscillationNotif:01675: Con 1eb0530000000007 - Oscillation of type 5 (RPC_LINGERED_1SEC) reported
14/02 21:48:43.917218 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000007 - Oscillation of type 1 (SOCKET_DOWN) reported
14/02 21:48:43.917296 afb28eb8:contNet_OscillationNotif:01675: Con 1eb052fe00000005 - Oscillation of type 1 (SOCKET_DOWN) reported
- SDS는 trc 파일에서 교착 상태 또는 중단된 스레드를 표시할 수 있습니다.
14/02 19:13:24.147938 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148113 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 19:13:24.148121 9aa4eeb8:netPath_IsKaNeeded:01789: DEBUG ASSERT, Reason:Socket deadlocked. Crashing.
14/02 20:52:54.097765 242f0eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:43.510602 7fa30eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 21:48:44.776713 1b67ceb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
14/02 02:44:41.532007 e2239eb8:contNet_OscillationNotif:01675: Con 1eb052fd00000001 - Oscillation of type 3 (RCV_KA_DISCONNECT) reported
14/02 02:44:43.799135 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0de10(0) in scheduler 0x7fff01bec400, running UMT 0x7f94e221eeb8, found to be stuck.
14/02 02:44:43.799155 0:schedThrdGuard_SampleLivnes:01463: WARNING: pThread 0x1a0e050(1) in scheduler 0x7fff01bec400, running UMT 0x7f94e2227eb8, found to be stuck.
14/02 02:44:43.799257 e0e38eb8:cont_IsSchedThredStuck:01678: Stuck scheduler thread identified
14/02 02:44:43.799267 e0e38eb8:kalive_StartIntr:00346: KA aborted due to stuck sched thread
- SDS는 trc 파일에서 "오류 분기"를 표시할 수 있습니다.
01/09 00:37:51.329020 0x7f1001c58eb0:mosDbg_BackTraceAllOsThreads:00673: Error forking.
- 필요한 메모리를 할당하지 못해 SDS를 시작할 수 없습니다.
다음은 exp 로그 파일에 보고됩니다.
07/09 00:41:52.713502 Panic in file /data/build/workspace/ScaleIO-SLES12-2/src/mos/usr/mos_utils.c, line 235, function mos_AllocPageAlignedOrPanic, PID 25342.Panic Expression pMem != ((void *)0) .
- OS는 /var/log/messages 또는 시스템 이벤트 로그에서도 일부 증상이 있을 수 있습니다.
/var/log/messages:
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683555] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683561] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683566] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:25:08 ScaleIO-192-168-1-2 kernel: [7461116.683570] TCP: Possible SYN flooding on port 7072. Sending cookies.
Feb 14 13:27:39 ScaleIO-192-168-1-2 kernel: [7461266.566145] sched: RT throttling activated
"포트 7072의 SYN 플러딩" 메시지는 네트워크 데이터 패킷이 이 호스트의 SDS로 전송되고 있으며 SDS가 해당 포트의 패킷을 수락할 수 없음을 의미합니다. SDS는 기본적으로 포트 7072를 사용합니다.
"RT throttling activated"는 OS 스케줄러가 CPU를 많이 차지하고 다른 스레드를 굶주리게 하는 일부 실시간 스레드를 식별했다는 메시지입니다. OS는 이러한 실시간 작업을 제한하고 OS가 중단되거나 충돌하는 것을 방지하기 위해 이 작업을 수행합니다.
SDC 문제:
SDS가 자주 연결을 끊거나 SDC에 충분히 신속하게 대응하지 못하고 소유한 IO 블록을 계속 처리하려고 시도하는 경우에도 SDC에서 IO 오류가 발생할 수 있습니다.
영향
위의 증상은 CLUSTER_DEGRADED뿐만 아니라 DATA_DEGRADED, DATA_FAILED 이벤트를 유발할 수 있습니다.
원인
위의 모든 증상이 일치하는 경우 CPU 또는 메모리 리소스 부족 문제일 가능성이 높습니다. MDM 또는 SDS 프로세스에서 CPU와 메모리가 부족할 수 있는 실행 중인 타사 애플리케이션 또는 프로세스를 찾습니다.
가상 환경에서 CPU 성능이 좋지 않은 경우가 몇 번 있었습니다. 이 문제는 SVM이 동일한 리소스 풀에 정의되어 있기 때문에 발생합니다.
이러한 경우 리소스 풀 아래에 SVM을 두지 말고 SVM에 정의된 대로 전용 리소스를 사용하는 것이 좋습니다.
해결
PowerFlex 구성 요소(MDM, SDS, SDC)가 성능 설정에 맞게 조정되었는지 확인합니다. 여기에서 성능 "미세 조정" 및 "문제 해결" 가이드를 참조하십시오.
구성 검토:
- 먼저 SVM CPU 및 RAM 설정이 모범 사례에 부합하는지 확인합니다.
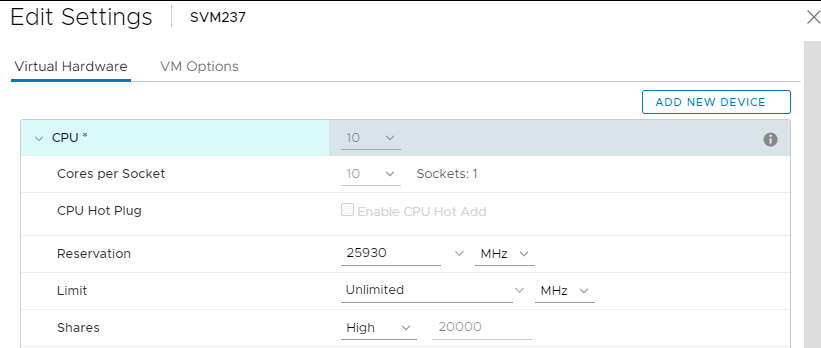
- SVM CPU 설정: (즉석에서 설정 가능)
- 소켓당 코어: 모두 하나의 소켓에 있으므로 "소켓"의 값은 "1"입니다. (전체 코어 수는 호스팅하는 SDS의 요구 사항에 따라 결정됩니다. 올플래시, FG, DASCache, CloudLink, 3.5 등은 모두 CPU 요구 사항에 영향을 미칩니다(증가).
- 예약: 드롭다운에서 "Maximum" 값을 선택합니다.
- 공유: 높음
- 다음과 같이 표시되어야 합니다.
- SVM CPU 설정: (즉석에서 설정 가능)
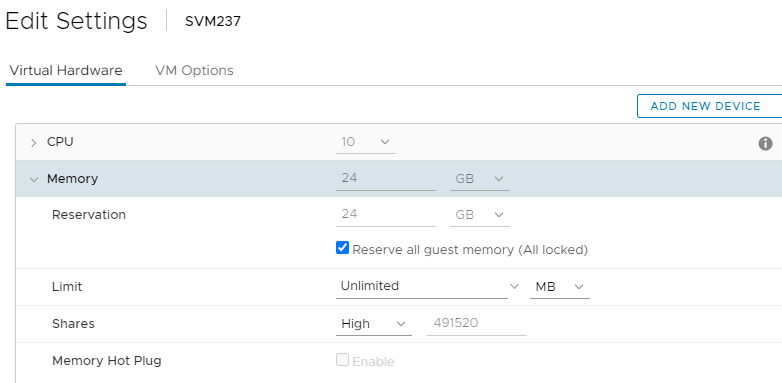
b. SVM RAM 설정: (즉석에서 설정 가능)
- "Reserve all guest memory (All locked)"를 선택합니다.
- 공유: 높음
- 다음과 같이 표시되어야 합니다.
c. 게스트 내 SVM OS 메모리 오버커밋 설정: (재부팅 필요)
-
- sysctl -a|grep overcommit을 실행하여 오버커밋 설정이 올바른지 확인합니다.
# sysctl -a|grep overcommit vm.overcommit_memory = 2 vm.overcommit_ratio = 100 -
위 값을 설정하지 않으면 일부 SVM 메모리를 SDS 프로세스에 사용할 수 없게 됩니다. /etc/sysctl.conf를 편집하고 위의 값을 편집/추가하여 이 문제를 해결합니다.
- SDS를 유지 보수 모드로 전환하고 SVM을 재부팅하여 설정을 적용합니다
- 재부팅 후 "cat /etc/sysctl.conf|grep overcommit"을 실행하여 확인합니다.
- 유지 보수 모드 종료
- sysctl -a|grep overcommit을 실행하여 오버커밋 설정이 올바른지 확인합니다.
- 로그에서 찾으려면 다음을 수행합니다.
- SVM 구성(vmsupport):
-
올바르게 구성된 SVM의 .vmx 파일에는 다음이 포함됩니다.
-
- SVM 구성(vmsupport):
sched.cpu.units = "mhz"
sched.cpu.affinity = "all"
sched.cpu.min = "25930" (nonzero value that's equal to core speed * the # of cores allocated)
sched.cpu.shares = "high"
sched.mem.min = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.minSize = "24576" (nonzero value that's a full allocation of configured memory)
sched.mem.shares = "high"
cpuid.coresPerSocket = "10" (value equal to total # of cores allocated, so they're all in one socket)
sched.mem.pin = "TRUE"
- 잘못된(오래된) SVMconfigs에는 다음이 있습니다.
sched.cpu.min = "0"
sched.cpu.shares = "normal"
sched.mem.pin = "FALSE"
sched.mem.shares = "normal"
cpuid.coresPerSocket = "4" (value less than total # of cores allocated, usually 1/2 or 1/4)
게스트 내 OS 구성(getinfo):
-
올바르게 구성된 메모리 오버커밋:
파일 서버/sysctl.txt에는 다음이 포함됩니다.
vm.overcommit_memory = 2
vm.overcommit_ratio = 100
-
PowerFlex는 메모리에서 고속으로 실행하기 위해 각 서비스에 상당한 양의 RAM을 사용합니다. 따라서 PowerFlex 서비스를 오프로드하는 데 사용되는 스왑 사용을 지원하지 않습니다.
HCI 솔루션의 스토리지 전용 및 SVM에 대해 예상되는 기본 설정은 오버커밋 메모리 2입니다. 이렇게 하면 커널이 메모리를 초과 구독하지 않고 스왑 설정을 사용하지 않고 commit_as 값이 사용 가능/사용 가능한 총 메모리보다 크지 않습니다.
100의 비율은 사용 중인 스왑을 차단하기 위한 더 많은 제어를 위해 스왑도 사용되지 않도록 합니다.
-
잘못 구성된 메모리 오버커밋:
파일 서버/sysctl.txt에 다음이 포함됩니다.
vm.overcommit_memory = 0 (value not 2)
vm.overcommit_ratio = 50 (value less than 95)
다른 가능한 해결 방법:
- CPU/메모리 리소스 부족의 원인이 되는 애플리케이션을 중지하거나 애플리케이션 공급업체에 리소스 소모를 완화하기 위한 업데이트를 확인하십시오.
- CPU/메모리 추세 분석 도구(top/sar/cron 작업 등)를 사용하여 리소스를 사용하는 애플리케이션을 찾습니다. 문제가 발생하는 시기와 책임자를 표시하는 데 필요한 세분화를 얻기 위해 1초 간격을 사용하는 것이 좋습니다
- 호스트 CPU 및/또는 메모리를 업그레이드하여 더 많은 리소스 제공
- 컨버지드 시스템이 아닌 2계층 설정으로 재설계(SDS/SDC가 동일한 호스트에 있는 경우)
추가 정보
문서 속성
문서 번호: 000167765
문서 유형: Solution
마지막 수정 시간: 05 5월 2026
버전: 6
다른 Dell 사용자에게 질문에 대한 답변 찾기
지원 서비스
디바이스에 지원 서비스가 적용되는지 확인하십시오.