
Contrairement à ce qu’on pourrait penser, une intelligence artificielle n’est pas exempte de préjugés. Par ses choix de conception, un développeur peut involontairement biaiser la neutralité de son IA et en modifier le comportement. Comment éviter cela ?
Laissez-moi vous présenter Norman. Non, pas le youtubeur. Le psychopathe. Norman ne voit pas le monde de la même manière que vous et moi (espérons-le du moins). Son esprit est entièrement tourné vers la mort et la souffrance. Toute sa vie, Norman n’a connu que la violence. Heureusement, Norman est une intelligence artificielle. La première IA psychopathe au monde, fruit du travail d’une équipe d’ingénieurs du MIT. Les chercheurs l’ont exposée aux contenus issus d’une sous-section du forum Reddit, où les internautes partagent des photos et vidéos de personnes trouvant la mort. Ils l’ont ensuite soumis au test de Rorschach et comparé ses réponses à celle d’un réseau neuronal plus traditionnel. Les résultats ne se sont pas fait attendre. Là où l’IA standard perçoit un parapluie ou des oiseaux sur un arbre, Norman voit des hommes abattus ou électrocutés.
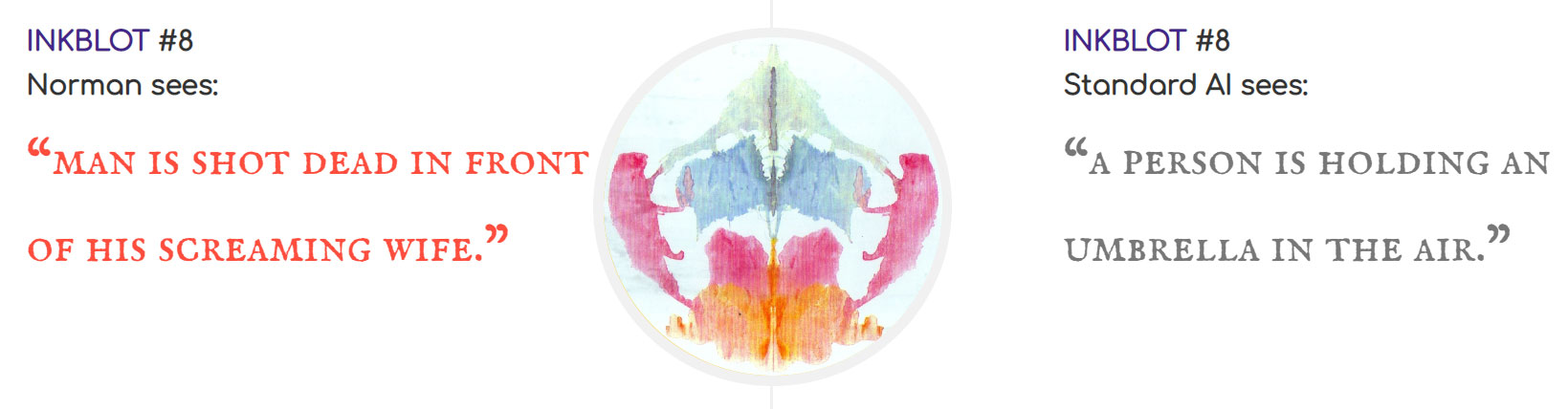
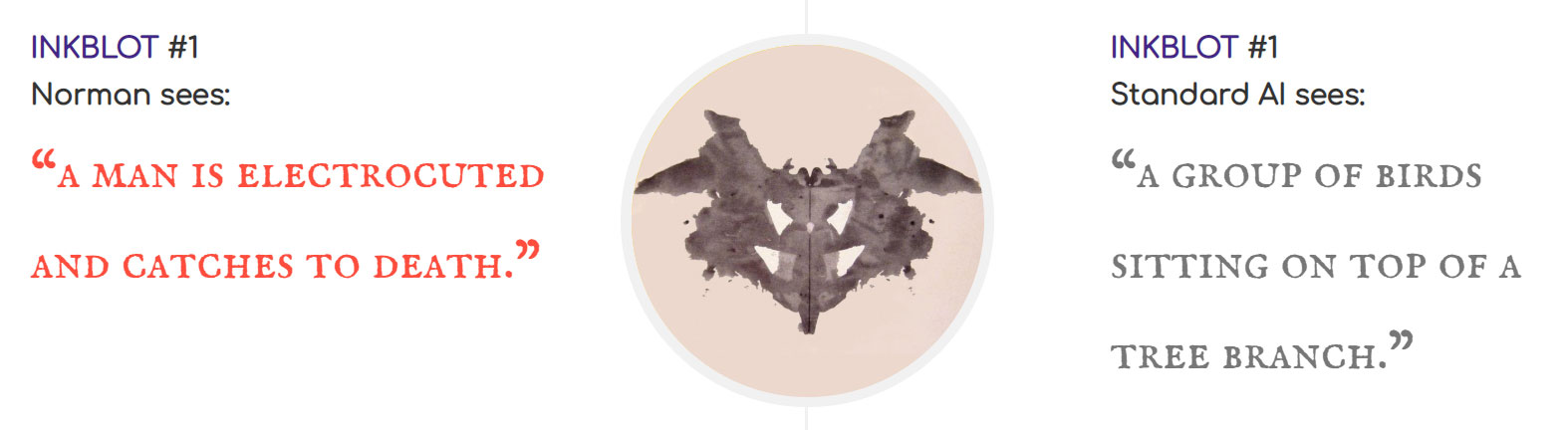
Le mythe de la neutralité
Pourquoi donner naissance à un tel programme ? Pour démontrer le danger des biais algorithmiques. La création d’une intelligence artificielle passe par une étape dite d’entraînement. Grâce à un processus de machine learning, ou apprentissage machine, on va nourrir l’IA de données qui vont lui servir de référence. Si vous souhaitez mettre au point une IA capable de reconnaître des visages par exemples, vous allez l’alimenter avec des millions de photos de personnes, afin qu’elle apprenne à distinguer les différentes morphologies et l’ensemble des caractéristiques physiques qui distinguent un être humain d’un autre. C’est de cette étape clé que dépend la qualité de l’IA. Plus les données sur lesquelles elle s’appuie seront nombreuses, plus elle sera précise dans ses réponses. Nombreuses, mais aussi variées. Car c’est également dans ce processus que peuvent apparaître des biais.
Contrairement à ce qu’on pourrait penser, une intelligence artificielle n’est pas un système totalement neutre. Elle base en effet ses prises de décisions sur les éléments et règles qu’on lui a préalablement dictés. Les développeurs peuvent alors inconsciemment orienter leur IA dans une certaine direction. Si l’exemple de Norman a volontairement été poussé à l’extrême par les chercheurs américains, d’autres cas réels sont apparus au cours des derniers mois. Des géants comme Google ou Microsoft, disposant pourtant d’un très haut niveau d’expertise sur ces questions, sont tombés dans le piège.
Quand l’humain projette ses propres défaillances
Le problème du biais algorithmique est qu’il ne s’agit justement pas d’un « simple » challenge technique. On peut légitimement supposer que les développeurs des GAFA cités plus haut ont un bagage technique solide. Le biais trouve son origine dans la culture des organisations et dans la personnalité même des concepteurs : leur parcours, leurs valeurs, leurs connaissances, leur culture… À la base d’une IA se trouvent des personnes qui ont fait des choix, mis en place des critères, établi des règles, sélectionné des données et écarté d’autres. Si l’erreur est humaine, on la retrouve donc très logiquement dans l’IA.
Prenons un nouvel exemple. À la fin des années 70 (déjà), l’école de médecine Saint George de l’université de Londres décidait, pour simplifier son processus de recrutement, de mettre au point un programme informatique chargé de faire le tri entre les CV qu’il recevait et de sélectionner les candidats qui seraient reçus en entretien. Pour cela, on avait intégré à l’intelligence artificielle l’historique des précédentes candidatures. À partir de là, l’IA avait identifié les caractéristiques d’une bonne et d’une mauvaise candidature. En 1979, entre 90 et 95 % des candidats sélectionnés par le modèle correspondaient à ceux choisis par le comité de recrutement. Face à une telle corrélation, décision a été prise en 1982 de laisser l’intelligence artificielle effectuer seule ce premier niveau de sélection. Ce n’est que quatre années plus tard que des médecins ont tiré le signal d’alarme. Le système écartait en effet bien plus volontiers de la sélection les personnes issues de minorités ethniques et les femmes. Des dizaines de personnes se sont vu opposer un refus sur ces seuls critères.
L’arme de la diversité
Cette histoire, racontée en détail dans le British Medical Journal, est très révélatrice de deux caractéristiques fondamentales du biais. Il est inconscient et profondément humain. Inconscient, car l’objectif n’était pas de procéder à une discrimination dissimulée. La mise en place de cette technologie répondait à un véritable besoin organisationnel. Ce sont les médecins eux-mêmes qui se sont aperçus des dérives de leur système et qui ont collaboré à l’enquête de la Commission pour l’égalité raciale, qui a reconnu l’établissement coupable de discrimination raciale et sexuelle. Humain, car comme le souligne très justement le journal, « le programme n’a pas introduit un nouveau biais ». En se conformant aux recrutements effectués par le passé, il n’a fait que reproduire des pratiques malheureusement déjà en place. L’intelligence artificielle, en cherchant à imiter les mécanismes du cerveau humain, peut également en reproduire les faiblesses.
Les chercheurs du MIT à l’origine du projet Norman abonde dans ce sens. « Lorsque les gens parlent d’algorithmes d’intelligence artificielle biaisés et injustes, le coupable n’est souvent pas l’algorithme lui-même, mais les données biaisées qui l’ont alimenté », soulignent-ils. Alors que l’intelligence artificielle est de plus en plus utilisée (et notamment par les services RH), le danger du biais est plus que jamais d’actualité. Deux leviers peuvent être exploités pour en limiter autant que possible les effets.
- Diversité des sources
On l’a vu, la qualité des données est un enjeu absolument fondamental. L’intelligence artificielle doit disposer d’une vision la plus complète possible de son sujet pour fonder une réflexion juste. Pour limiter les carences dans les jeux de données utilisées, il est donc nécessaire de pouvoir s’appuyer sur une infrastructure puissante de collecte, capable de récupérer la donnée au plus près de la source, d’analyse, à même de la traiter le plus efficacement possible, mais aussi de stockage, en mesure d’évoluer au même rythme que les besoins. Car une intelligence artificielle n’est jamais un système achevé mais un processus continu, dont l’acuité n’aura de cesse d’augmenter à mesure que grandiront les sources qui l’alimentent. Tout espoir n’est donc pas perdu pour Norman.
- Diversité des profils
Les entreprises les plus inclusives sont les plus performantes. Selon une étude Deloitte, plus la diversité des talents est grande, plus l’organisation est susceptible d’atteindre ou de dépasser ses objectifs business. Ce principe général s’applique à l’intelligence artificielle. Plus les professionnels qui travaillent sur la conception de l’IA sont issus d’horizons différents, plus leur vision sera riche, leurs apports hétérogènes, leurs méthodologies variées et donc le risque d’une conception biaisée, faible. Si l’intelligence artificielle n’est pas nouvelle, beaucoup d’entreprises ont encore une connaissance relativement mince de technologies comme le machine learning et le deep learning et doivent donc passer par des recrutements pour espérer les exploiter à leur avantage. Il serait dommage de reproduire la même erreur que l’IA de Saint George.