Avamar:備份效能行為與理論
Summary: 本文討論 Avamar 備份期間的行為,並協助說明 Avamar 用戶端備份效能。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
本文的目的是說明 Avamar 備份期間發生的情況,著重於協助讀者瞭解備份效能行為。
本文為下列文章的附屬文章:
Avamar 備份期間會發生什麼?
avtar 備份程序:
1) 將檔案和雜湊快取檔案載入至記憶體
2) 建立 VSS 快照 (在 Windows 上):
3) 遍曆數據集定義的所有檔 對於源數據集
中的所有檔,avtar 採用完整路徑並將其與類似 stat 的元數據相結合,以計算哈希以唯一標識檔。
如需更多詳細資訊,請參閱 Avamar:當 avtar 在檔案掃描階段讀取檔案時會發生什麼情況。
4) 將計算的哈希與本地用戶端緩存中的哈希進行比較 Avtar 在文件緩存
中查找檔的哈希。它會檢查它是否為新項目,或自上次備份後是否經過修改。
如果文件緩存查找成功,則檔存在且保持不變。
如果查找失敗,則檔是新的或已更改。必須讀取和處理
。如需更多資訊,請參閱 Avamar 用戶端 - 在 avtar 認為檔案已被修改之前,必須變更哪些內容?
5) 處理新檔案與修改檔案 對於任何新檔案或修改檔案
,avtar 必須:
Avtar 會透過網路將任何遺失雜湊的資料傳送至 Avamar 伺服器,以檢查其是否存在。這些要求
稱為「存在」。7) 資料會寫入 Avamar Server (如適用,亦可寫入 Data Domain)。
如需更詳細的工作流程,請參閱隨附 的Avtarprocess.pdf。
從效能角度看 Avamar 備份的概觀:
典型的文件處理性能約為每小時 100 GB,但最高可差到每小時 300 GB。這取決於環境。
雜湊會寫入用戶端快取檔案,並與 Avamar 伺服器上的雜湊進行比較,以檢查是否必須新增任何新資料。無論 Avamar 伺服器或 Data Domain 是目標儲存裝置,皆是如此。
Avamar 用戶端和伺服器之間的雜湊比較通常很快。如果 Avamar 伺服器是,他們不應成為備份的瓶頸;
由於哈希的大小僅為 20 位元組,因此此階段受網路延遲的影響大於網路頻寬。當雜湊到達 Avamar 伺服器時,資料節點磁碟子系統的一般負載和隨機搜尋效能,決定了擷取並與用戶端傳送的雜湊比較的速度。
關鍵資源:網路回應時間和 Avamar 資料節點隨機搜尋效能。
實體 Avamar 的隨機搜尋效能會隨著資料節點的數量和大小而擴充。與單節點系統相比,AVE 系統的性能較差。
階段 4.透過網路將新區塊傳送至 Avamar 伺服器或 Data Domain
當用戶端向伺服器發送一個新的唯一區塊(最大 64 KB)時,性能主要取決於網路頻寬。這主要影響基於WAN的用戶端,這些用戶端每天生成大量更改的數據。它還可能影響那些在擁塞的網路鏈路上運行的使用者。
以下示意圖顯示用戶端將資料傳送至 Avamar 系統和 Avamar - Data Domain 整合式系統的資料流程。
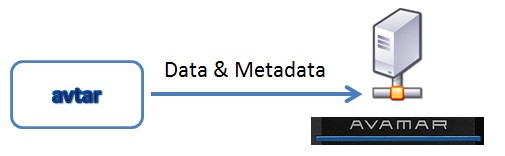
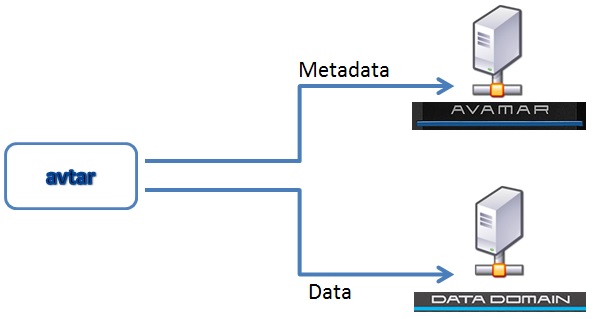
關鍵資源:用戶端和伺服器
之間的網路頻寬第 5 階段。寫入 Avamar Server 或 Data Domain
的資料備份資料必須寫入 Avamar 伺服器或 Data Domain 系統。
關鍵資源:Avamar 伺服器磁碟寫入效能和一般載入。
本文為下列文章的附屬文章:
Avamar 備份期間會發生什麼?
avtar 備份程序:
1) 將檔案和雜湊快取檔案載入至記憶體
2017-06-09 23:00:25 avtar Info <5586>: Loading cache files from C:\Program Files\avs\var 2017-06-09 23:00:25 avtar Info <8650>: Opening filename cache file 'C:\Program Files\avs\var\f_cache2.dat' 2017-06-09 23:00:25 avtar Info <5573>: - Loaded filename cache file (6,532,792 bytes) 2017-06-09 23:00:26 avtar Info <8650>: Opening hash cache file 'C:\Program Files\avs\var\p_cache.dat' 2017-06-09 23:00:28 avtar Info <5573>: - Loaded hash cache file (402,653,728 bytes) 2017-06-09 23:01:01 avtar Info <6426>: Done loading cache files
2) 建立 VSS 快照 (在 Windows 上):
2017-06-09 23:04:32 avtar Info <19008>: Obtaining available VSS providers 2017-06-09 23:04:32 avtar Info <8776>: Freezing volumes now... 2017-06-09 23:04:32 avtar Info <8780>: Creating the shadow copy set (DoSnapshotSet) ... 2017-06-09 23:14:33 avtar Info <8781>: Shadow copy set successfully created. 2017-06-09 23:14:34 avtar Info <6074>: VSS snapshot set creation successful
3) 遍曆數據集定義的所有檔 對於源數據集
中的所有檔,avtar 採用完整路徑並將其與類似 stat 的元數據相結合,以計算哈希以唯一標識檔。
如需更多詳細資訊,請參閱 Avamar:當 avtar 在檔案掃描階段讀取檔案時會發生什麼情況。
4) 將計算的哈希與本地用戶端緩存中的哈希進行比較 Avtar 在文件緩存
中查找檔的哈希。它會檢查它是否為新項目,或自上次備份後是否經過修改。
如果文件緩存查找成功,則檔存在且保持不變。
如果查找失敗,則檔是新的或已更改。必須讀取和處理
。如需更多資訊,請參閱 Avamar 用戶端 - 在 avtar 認為檔案已被修改之前,必須變更哪些內容?
5) 處理新檔案與修改檔案 對於任何新檔案或修改檔案
,avtar 必須:
- 閱讀整個檔案
- 將其分解成可變大小的塊
- 壓縮每個區塊
- 計算每個區塊的哈希
Avtar 會透過網路將任何遺失雜湊的資料傳送至 Avamar 伺服器,以檢查其是否存在。這些要求
稱為「存在」。7) 資料會寫入 Avamar Server (如適用,亦可寫入 Data Domain)。
如需更詳細的工作流程,請參閱隨附 的Avtarprocess.pdf。
從效能角度看 Avamar 備份的概觀:
在上述階段中,我們將其拆分為對備份性能影響最大的「階段」:
階段 0。建立 VSS 快照。
卷影複製服務 (VSS) 創建源數據集中指定的卷的快照。應用程式可以在備份運行時繼續寫入卷。
Avamar 會備份磁碟區的唯讀「凍結」快照,而非可寫入的磁碟區。這可確保要備份的數據集一致。
VSS 快照需要幾秒鐘才能完成。如果用戶端遇到 VSS 問題,此程序會延遲或阻止備份繼續進行。
第 1 階段。檔案掃描階段。avtar 程序會統計目標資料集中
的所有檔案對於具有數百萬個文件的用戶端,此階段可能是最耗時的。
資料庫數據包含的較大的檔很少,因此檔掃描階段需要很少的時間。資料庫用戶端通常會在階段 #2 期間消耗其時間。
若為配備 RAID 5 組態旋轉磁碟的用戶端,檔案掃描效能通常為每小時 ~100 萬個檔案。這從每小時 300,000 到 300 萬不等。這取決於 客戶機環境和要備份的數據的特性。
從 7.3 版開始,備份至 Data Domain 的 Linux 用戶端可以利用 Linux 快速增量 (LFI) 功能。這樣可避免每次執行備份時掃描整個資料集。
關鍵資源: 存儲備份數據的磁碟的隨機搜索性能。
第 2 階段。Avtar 會讀取變更的檔案,然後對資料進行區塊、壓縮和雜湊處理。
在此階段進行大量計算。對於每個修改的檔或新檔,avtar 會將其分解成小塊。它壓縮每個塊並計算哈希作為「指紋」以識別塊。
典型的文件處理性能約為每小時 100 GB,但最高可差到每小時 300 GB。這取決於環境。
關鍵資源:用戶端磁碟和 CPU
對於在將資料傳送至 Avamar 伺服器時沒有瓶頸的 LAN 備份,階段 #1 和 #2 花費的時間最多。
在下圖中,請考慮圖形條形中的面積對應於備份所需的時間。更改的檔可能會大大增加所需的時間,尤其是在這些檔很大的情況下。
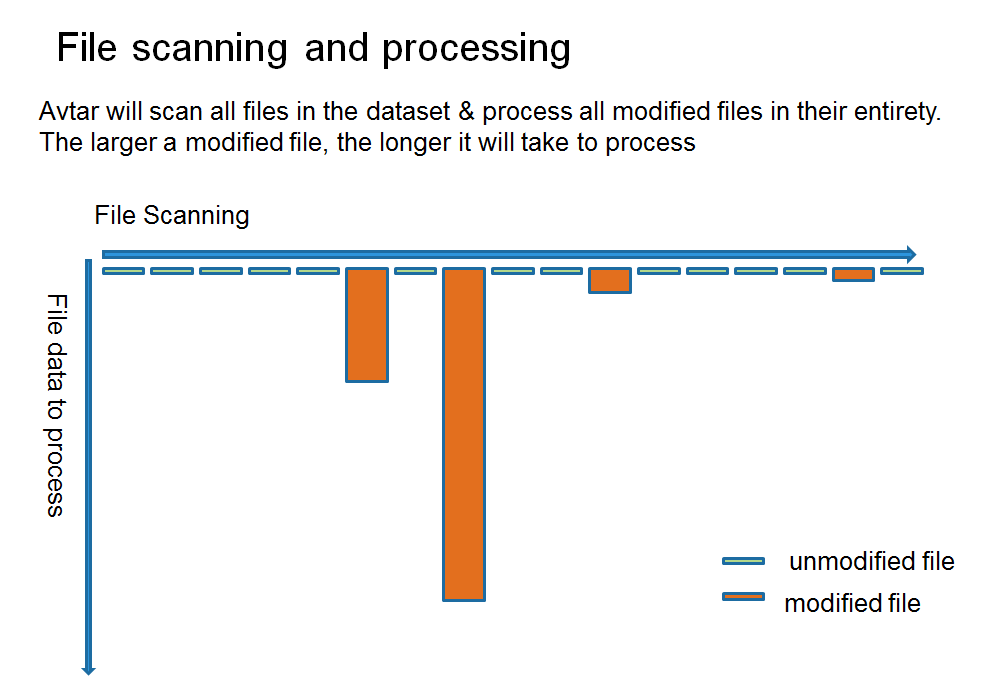
對於文件系統數據集,預計每天會有 ~0-3% 的檔更改。
Avtar 必須通過執行兩個 I/O 操作來“stat()”更改的每個檔,一個用於檢查文件屬性,另一個用於安全屬性。
為了達到檔案系統備份 1 ~100 萬個檔案/小時的效能指標掃描速率效能, avtar 每小時需要約 200 萬個搜尋作業,或每秒 600 個搜尋作業。
例如:如果備份的變更率為 3%,則 100 個檔案中有 97 個檔案需要兩個磁碟搜尋作業,才能識別其是否有變更。其餘三個確實更改了,必須進行掃描、分塊、壓縮和哈希處理。
這僅考慮文件掃描階段,不考慮處理任何已修改檔所需的 I/O 資源。
已修改檔案中的資料越多,完成備份所需的工作就越多。
第 3 階段。檢查 Avamar Server
上是否存在雜湊階段 #1 和 #2 生成指向備份元素的哈希。這些元素可以是獨特的檔案區塊、檔案系統或整個備份。
雜湊會寫入用戶端快取檔案,並與 Avamar 伺服器上的雜湊進行比較,以檢查是否必須新增任何新資料。無論 Avamar 伺服器或 Data Domain 是目標儲存裝置,皆是如此。
Avamar 用戶端和伺服器之間的雜湊比較通常很快。如果 Avamar 伺服器是,他們不應成為備份的瓶頸;
- 健康
- 在一般負載水準下
- 與用戶端位於相同的 LAN 區段
由於哈希的大小僅為 20 位元組,因此此階段受網路延遲的影響大於網路頻寬。當雜湊到達 Avamar 伺服器時,資料節點磁碟子系統的一般負載和隨機搜尋效能,決定了擷取並與用戶端傳送的雜湊比較的速度。
關鍵資源:網路回應時間和 Avamar 資料節點隨機搜尋效能。
實體 Avamar 的隨機搜尋效能會隨著資料節點的數量和大小而擴充。與單節點系統相比,AVE 系統的性能較差。
階段 4.透過網路將新區塊傳送至 Avamar 伺服器或 Data Domain
當用戶端向伺服器發送一個新的唯一區塊(最大 64 KB)時,性能主要取決於網路頻寬。這主要影響基於WAN的用戶端,這些用戶端每天生成大量更改的數據。它還可能影響那些在擁塞的網路鏈路上運行的使用者。
以下示意圖顯示用戶端將資料傳送至 Avamar 系統和 Avamar - Data Domain 整合式系統的資料流程。
關鍵資源:用戶端和伺服器
之間的網路頻寬第 5 階段。寫入 Avamar Server 或 Data Domain
的資料備份資料必須寫入 Avamar 伺服器或 Data Domain 系統。
關鍵資源:Avamar 伺服器磁碟寫入效能和一般載入。
Affected Products
Avamar ClientArticle Properties
Article Number: 000019552
Article Type: How To
Last Modified: 17 Apr 2026
Version: 7
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.