Avamar: Capacity Management Concepts and Training
Summary: This article is for Avamar user and operating system Capacity Management. The intended readers are Avamar administrators and those monitoring Avamar health, who require a working understanding of how to manage OS and User Capacity. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
For Capacity Management issues relating to Data Domain, see the "Reclaiming storage on a full Data Domain system" section in the Avamar and Data Domain System Integration Guide.
The guides relevant to your operating environment can be found here: How to locate Avamar documentation on the Dell Support site.
Objectives of this article:
-
Summarize the types of data which are stored in the /data* partitions.
-
Introduce the concept of "Operating System (OS) Capacity" and contrast this with the concept of "User Capacity" (sometimes called "
GSANCapacity.") -
Explain why Avamar should not be run close to the User Capacity limit.
-
List the factors which contribute to checkpoint overhead.
-
Describe how to monitor data partition utilization.
-
Describe the symptoms experienced if operating system capacity gets out of control.
-
List typical causes of the
MSG_ERR_DISKFULLmessage. -
Outline the recovery methods used where high operating system capacity is impacting normal system operation.
-
Describe the symptoms experienced if User Capacity exceeds the User capacity limit.
-
Discuss how to recover from a high User Capacity situation.
This article assumes that the reader is familiar with the "Managing Capacity" section in the Avamar Operational Best Practices Guide.
Again, the guides relevant to your operating environment can be found here: How to locate Avamar documentation on the Dell Support site.
Common issues which affect, or are symptoms of high OS Capacity are:
-
Checkpoint validation (
hfscheck) is failing. -
Garbage collection fails to run and reports
MSG_ERR_DISKFULL. -
Checkpoint creation failures.
Common symptoms which are closely associated with too high "User Capacity" are:
-
Backups are failing.
-
Incoming replication jobs are failing.
-
The Administrator interface shows the system in 'Admin' mode during the backup window.
Cause
This article provides the concepts around Avamar Capacity Management Concepts and Training.
Resolution
How is data stored on the Avamar grid?
Avamar capacity management concerns the data which is in the /data* partitions of all Avamar data nodes.
This consists of:
-
Deduplicated backup data
-
RAIN parity data
-
Checkpoint overhead data
Both RAIN parity and checkpoint data are layers of redundancy available to Avamar in addition to RAID and Replication.
Free space in the data partitions is also required in order for maintenance tasks such as garbage collection (GC) and asynchronous stripe crunching to run correctly.
Below is a graphical representation of the physical storage space available within the data partitions on the Avamar storage nodes.
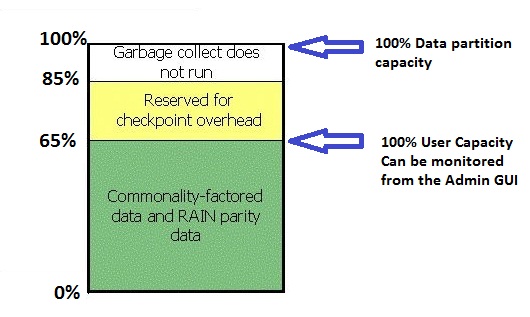
How is data stored in the data partitions?
In the above diagram, there is a simple representation of how the space is used in the data partitions.
The 100% value on the left is defined to be the total amount of physical space available to the operating system in the data partitions.
If any of the data partitions consume more than 89% of the total space, the garbage collection is unable to run.
-
The 100% User Capacity marker (read-only limit) indicates that up to 65% of the total space in the data partition is available for storage of deduplicated data.
-
The space below this 100% User Capacity marker is equivalent to the Server Utilization value which is visible in the Administrator UI.
If the amount of deduplicated data that is stored on any data partition on any node reaches 65%, then Avamar becomes read-only and refuses further backup data.
Based on the above, it can be understood that, from the Avamar Administrator UI, the user has visibility of space that backups have consumed but does not have visibility of space that is consumed in the operating system data partitions.
Why an Avamar system should not be run close to the "User Capacity" limit:
The relationship between high "User Capacity" and checkpoint overhead is such that as a system becomes increasingly full, even small increases in backup data can cause large increases in checkpoint overhead.
A full discussion of why this is the case is beyond the scope of this article however the important thing to remember is: The closer an Avamar system is to 100% User Capacity, the less operating system capacity is available for checkpoint overhead.
On a full system, as per the diagram above, checkpoint overhead is limited to 20% of the total operating system space in the data partitions.
For an Avamar system to run reliably at high levels of "User Capacity," it must meet the following criteria:
-
The system must have a low rate of daily changed data (no higher than 1%.)
-
Capacity must be in a steady-state (as described in the "Managing Capacity" section of the Avamar Operational Best Practices Guide). The guides relevant to your operating environment can be found here: How to locate Avamar documentation on the Dell Support site.
-
Maintenance tasks should be completing successfully every day.
If any of these statements turn from true to false, checkpoint overhead can be expected to gradually rise or suddenly spike and cause serious operational issues.
Factors which contribute to checkpoint overhead:
The following factors can cause the checkpoint overhead to increase.
-
Asynchronous crunching of stripes (enabled by default)
-
The number of checkpoints stored on the system
-
Checkpoint validation is not completed successfully everyday.
-
How empty stripes are when the Avamar server reuses them (becomes more severe with higher server utilization)
-
The daily backup change rate
A system administrator has a certain degree of control over these factors. Configuration of asynchronous crunching is for support only, but Administrators may remove excess checkpoints, investigate checkpoint failures, and influence server utilization and daily data change rate.
How to monitor data partition utilization:
The correct way to monitor utilization of the OS data partition is to use the following Avamar command from the Avamar Utility Node:
avmaint nodelist | grep fs-percent
Example output:
fs-percent-full="7.8"
fs-percent-full="6.3"
fs-percent-full="6.4"
fs-percent-full="6.4"
fs-percent-full="7.6"
fs-percent-full="6.2"
fs-percent-full="6.1"
fs-percent-full="6.6"
fs-percent-full="7.8"
fs-percent-full="6.4"
fs-percent-full="6.5"
fs-percent-full="6.8"
-
-
This output gives a true reading of the operating system capacity utilization.
-
On a grid where data nodes use a file pool, the Linux
dfcommand is not meaningful because the stripes are preallocated in the file pool, and many of the stripes might not be in use.
-
What happens if Operating System capacity usage gets out of control?
From a user point of view, the first indication that data partition utilization is out of control occurs when it rises above 89%.
Garbage collection is no longer able to run and fails with an MSG_ERR_DISKFULL error message.
Here is where misunderstandings often occur: The user often interprets the MSG_ERR_DISKFULL message to mean that the system no longer has space for backups.
This interpretation is not correct, however, the user usually checks the server utilization value in the Avamar Administrator UI and find the value to be acceptable, for example 60%.
The user may attempt to delete backups from the Avamar UI's Backup management interface. Even if the User Capacity level were high, the deletion of backups would not alleviate the situation since garbage collection is unable to run and remove expired chunks of data from the system.
If a system is experiencing both a high operating system Capacity issue and high User Capacity, focus on resolving the high operating system Capacity issue first.
In cases of high operating system capacity utilization, the system may run short of space to create checkpoints.
What causes the MSG_ERR_DISKFULL message?
The most typical cause is too-high checkpoint overhead. Typical causes of high checkpoint overhead could be:
-
Checkpoint validation (
hfscheck) has failed repeatedly. -
An
hfscheckfailure has many possible root causes (abrupt cancellation, software failure, and so forth). -
The system is running too full and has a high daily data change rate.
-
The system needs more data nodes to handle the data change rate and store the data.
-
The system is configured to back up more data or clients than it was sized for.
-
Too many checkpoints are being stored (Avamar stores two checkpoints by default, one of which has been validated).
-
The system administrator created excess checkpoints.
-
Maintenance was recently carried out, but the default checkpoint retentions were not reinstated.
See the following article to help resolve the MSG_ERR_DISKFULL scenario: Avamar: Maintenance tasks fail with MSG_ERR_DISKFULL due to the Operating System capacity of one or more data partitions exceeding 89 percent
Actions to investigate and help alleviate high operating system capacity:
1. Determine when the last hfscheck finished. This can be done using either the Avamar Administrator or the command line on the Avamar Utility Node:
- In the Avamar Java Administrator UI:
- Go to Server > Checkpoint Management tab
- Check the most recent date and time that is listed in the Checkpoint Validation column. This should have occurred within the last 24 hours.
-- Or --
- Using the Avamar Utility Node command line:
- Run the command:
cplist.
- Run the command:
Below is an example of from the CLI output:
admin@utilitynode:~/>: cplist
cp.20110114111419 Fri Jan 14 11:14:19 2011 valid rol --- nodes 3/3 stripes 1131
cp.20110114194457 Fri Jan 14 19:44:57 2011 valid --- --- nodes 3/3 stripes 1131
-
-
-
-
The most recent validated checkpoint that is listed here is dated January 14, 11:14.
-
It is identified by the flag directly after the 'valid' marker.
-
Depending on the types of checkpoint validations set on the system, the flag could be
rolorhfs. -
This is an example of a
rol(rolling)hfscheck.
-
-
-
If the results show that the latest validated checkpoint is older than 24 hours, find out why. This could either be because the HFScheck did not run or because it failed.
2. Confirm if HFScheck ran or if it failed:
On the Avamar Utility Node, run the status.dpn command and find the line which starts with "Last hfscheck".
For Example:
Last hfscheck: finished Sat Jan 15, 11:07:17 2011 after 06m 41s >> checked 528 of 528 stripes (OK)
Take note of when it finished and what the status was (in the line above the status is shown as 'OK').
Note: The sched.sh script can also be used to identify when an
HFScheck last ran and whether it was successful.
If hfscheck jobs have been failing, this should be investigated immediately.
If hfscheck has not run lately, verify that the maintenance scheduler is enabled by running the command "dpnctl status maint" on the Avamar Utility Node: .
admin@utilitynode:~/>: dpnctl status maint
Identity added: /home/admin/.ssh/dpnid (/home/admin/.ssh/admin_key)
dpnctl: INFO: Maintenance windows scheduler status: enabled.
- If the maintenance windows scheduler is down, disabled, or suspended, enable it with the command:
dpnctl start maint - Optionally take a new checkpoint and run
hfscheck, or wait for the next scheduled maintenance window to complete.
Once an hfscheck has completed successfully (after addressing any issues or restarting the maintenance scheduler), the oldest checkpoint will be 'rolled off', and the operating system capacity should reduce considerably.
- If the operating system capacity is still too high, and garbage collection continues to fail with the
MSG_ERR_DISKFULLmessage, then seek assistance from the Dell Technical Support team. - Otherwise, if operating system capacity is low enough to allow garbage collection to complete, then work on lowering "User Capacity" and bring the "server utilization" figure down.
Actions to alleviate high User Capacity:
Unlike operating system Capacity, User Capacity levels are more easily and directly influenced by the Avamar system administrator.
1. Ensure that garbage collection is running every day and that it does not get interrupted by backups.
This is the most crucial point as even an adequately sized system quickly experiences high User Capacity if garbage collection does not run regularly or reliably.
As shown earlier, confirm that the maintenance window is enabled and use the capacity.sh and sched.sh scripts to verify that garbage collection is running, that it is removing data.
Prior to Avamar v7.x, backups could not run during the garbage collection "restriction" window.
The Hash Referenced Bit Maps feature introduced with Avamar v7.x feature allows backups to occur during the GC maintenance activity. This feature requires that these "maps" must have at least 5 minutes of "quiet" time per day during which no backups are run so that they can reset.
Content about this feature can be accessed using the link to the article Avamar: From Avamar v7, Garbage Collection reports "skipped-hashes" that cannot be cleaned up due to "Hash Referenced Bit Maps" when the data is in use.
2. Stop adding new clients to the grid.
Once an Avamar grid is approaching capacity, stop adding new clients immediately to prevent the situation from worsening.
If there is another Avamar grid which is running at a lower level of server utilization, consider adding new clients to that grid instead of the server which is becoming full.
3. Learn which clients are consuming the most storage space.
To address a capacity issue, identify which clients are responsible for adding the most data to the Avamar system.
The capacity.sh script (run from the Avamar Utility Node command line) can also be used to identify which clients which have the highest change rate.
See Avamar: How to manage capacity with the capacity.sh script for more infomraiotn about how to use the capacity.sh script.
It is often found that the 'hungriest' clients are those which back up SQL databases or email servers so pay particular attention to these.
4. Reassess retention policies.
After identifying high change rate clients, reassess retention policies to see if any can be lowered in order to reduce storage requirements to an acceptable level.
Note: It is recommended that retention policies be set to at least 14 days.
If the system is old enough to have started expiring the longest retained backups, then after reducing retention policies, expect to see an increase in the amount of data removed each day by garbage collection. Monitor this trend with capacity.sh.
If the Avamar system is not yet old enough to have started expiring backups, then the retention policies may require altering so that the oldest backups now start to expire.
If it is not possible to reduce retention policies due to regulatory requirements, consider expanding the Avamar system or migrating clients to another, less used, Avamar.
5. Migrate clients to an alternative Avamar system.
If another Avamar system is available, consider the possibility of migrating large or high change rate clients from higher to lower used systems by using the Avamar Client Manager interface.
Note:
- The new Avamar server requires sufficient storage for the Avamar clients to be migrated.
- Keep clients with similar type of data on the same Avamar system to take advantage of deduplication efficiencies.
- This strategy is best used where the Avamar systems are on the same local area network.
6. Delete old backups.
If the User Capacity level is severe (>90%), expiring old backups through the Backup Management interface may be required or with the modify-snapups tool.
Dell users can access the content using the link to the article Avamar: Capacity Management - How to delete or expire backups in bulk with the "modify-snapups" tool
Deleting backups does not immediately lower the server utilization level. What it does is allow garbage collection to start removing the data the next time garbage collection runs. Deleting old backups is a short-term workaround. The backups are replaced over the coming days. If backups are deleted, it is essential to also tune retention policies.
7. Monitor data change using capacity.sh.
After backups have been deleted and retention policies changed, closely monitor the amount of data changed on the system using the capacity.sh script. The "removed" data value should increase and the "Net Change" value should become negative. Eventually, as the excess data is cleared off the system, the "Removed" value starts to return to more normal levels. Continue to monitor the "Removed" value.
If the net change value does not become negative, check the GC log to see how long garbage collection is running for and how much work it is achieving within the maintenance window.
See Avamar: How to manage capacity with the capacity.sh script for more information about how to use the capacity.sh script.
8. Expand the Avamar system:
Often high utilization on the Avamar grid is due to natural and expected data growth. More space must be made available to continue production backups.
How this can be done depends on the type of Avamar grid.
-
Single node grids and the Avamar Virtual Edition (AVE):
- These cannot be expanded. Commission a second, larger Avamar system, and request Dell Professional Services to perform a system migration from the smaller to the larger system.
- Professional Services can be engaged through the Dell Account Manager.
- The new system may be a single node, AVE, or a multinode system, if it provides more storage space than the source.
- These cannot be expanded. Commission a second, larger Avamar system, and request Dell Professional Services to perform a system migration from the smaller to the larger system.
-
Multinode grids:
- These systems can be expanded to up to 16 data nodes.
- Contact the Dell Account Manager for details (Regular support channels do not perform node additions so a Service Request should not be opened to request this work.)
- These systems can be expanded to up to 16 data nodes.
-
Integrate Data Domain:
-
Integrating a Data Domain system as a backend storage device is a useful way to expand the capacity available to clients which back up to Avamar.
-
Discuss options with your Dell Account Manager.
-
-
Additional Information
Useful Tools
status.dpncapacity.shAvalancheDPN Summary Reportreplcnt.sh- Avamar Client Manager
Best Practices:
-
Try to prevent the Avamar Server utilization (User Capacity) value rising higher than 80%.
-
Lower User Capacity provides resilience against unexpected changes in the amount of data added and can protect against the system becoming unusable if unexpected failures or short-term issues with maintenance tasks.
-
An Avamar system running above 80% User Capacity requires more diligent monitoring by the system administrator to ensure that maintenance tasks complete successfully and that the system does not become read-only.
Affected Products
Avamar, Avamar ServerArticle Properties
Article Number: 000079977
Article Type: Solution
Last Modified: 09 Jun 2026
Version: 21
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.