Ytelse for dyp læring på T4 GPU-er med MLPerf-ytelsesprøver
Summary: Informasjon om Turing-arkitektur som er NVIDIAs nyeste GPU-arkitektur etter Volta-arkitekturen og den nye T4, er basert på Turing-arkitektur.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Artikkel skrevet av Rengan Xu, Frank Han og Quy Ta fra HPC and AI Innovation Lab i mars 2019
Cause
-
Resolution
Innholdsfortegnelse:
Sammendrag
Turing-arkitektur er NVIDIAs nyeste GPU-arkitektur etter Volta-arkitektur, og den nye T4 er basert på Turing-arkitektur. Den er utviklet for databehandling med høy ytelse (HPC), dyp læringsopplæring og inferens, maskinlæring, dataanalyse og grafikk. Denne bloggen vil kvantifisere ytelsen til dyp læring for T4 GPU-er på Dell EMC PowerEdge R740-server med MLPerf-ytelsestestingspakke. MLPerf-ytelse på T4 vil også bli sammenlignet med V100-PCIe på samme server med samme programvare.
Oversikt
Dell EMC PowerEdge R740 er en 2U-rackserver med to sokler. Systemet har Intel Skylake-prosessorer, opptil 24 DIMM-er og opptil 3 V100-PCIe med dobbel bredde eller 4 T4 GPU-er med enkel bredde i x16 PCIe 3.0-spor. T4 er GPU-en som bruker NVIDIAs nyeste Turing-arkitektur. Spesifikasjonsforskjellene for T4 og V100-PCIe GPU er oppført i tabell 1. MLPerf ble valgt til å evaluere ytelsen til T4 i dyp læring. MLPerf er et ytelsestestverktøy som ble satt sammen av en mangfoldig gruppe fra akasanering og industri, inkludert Google, Baidu, Intel, AMD, Harvard og Piper osv., for å måle hastigheten og ytelsen til maskinlæringsprogramvare og -maskinvare. Den opprinnelige utgitte versjonen er v0.5, og den dekker modellimplementeringer i forskjellige maskinlæringsdomener, inkludert bildeklassifisering, objektdeteksjon og segmentering, maskinoversetting og forsterkningslæring. Sammendraget av MLPerf-ytelsestestene som brukes for denne evalueringen, vises i tabell 2. ResNet-50 TensorFlow-implementeringen fra Googles innsending ble brukt, og alle andre modellers implementeringer fra NVIDIAs innsending ble brukt. Alle ytelsestestene ble kjørt på bart metall uten beholder. Tabell 3 viser maskinvaren og programvaren som brukes for evalueringen. T4-ytelse med MLPerf-ytelsestest sammenlignes med V100-PCIe.
| Tesla V100-PCIe | Tesla T4 | |
|---|---|---|
| Arkitektur | Volta | Turing |
| CUDA-kjerner | 5120 | 2560 |
| Tensor-kjerner | 640 | 320 |
| Beregningsfunksjonalitet | 7.0 | 7.5 |
| GPU-klokke | 1245 MHz | 585 MHz |
| Økningsklokke | 1380 MHz | 1590 MHz |
| Memory Type (Minnetype) | HBM2 | GDDR6 |
| Minnestørrelse | 16 GB /32 GB | 16GB |
| Båndbredde | 900 GB/s | 320 GB/s |
| Sporbredde | To spor | Enkeltspor |
| Enkel Precision (FP32) | 14 TFLOPS | 8,1 TFLOPS |
| Mixed-Precision (FP16/FP32) | 112 TFLOPS | 65 TFLOPS |
| Dobbel Precision (FP64) | 7 TFLOPS | 254,4 GFLOPS |
| TDP | 250 W | 70 W |
Tabell 1: Sammenligningen mellom T4 og V100-PCIe
| Bildeklassifisering | Objektklassifisering | Segmentering av objektforekomst | Oversettelse (gjentakende) | Tanslation (ikke regelmessig) | Anbefaling | |
|---|---|---|---|---|---|---|
| Data | ImageNet | COCO | COCO | WMT E-G | WMT E-G | MovieLens-20M |
| Datastørrelse | 144 GB | 20 GB | 20 GB | 37 GB | 1,3 GB | 306 MB |
| Modell | ResNet-50 v1.5 | Én fase av SSD (SSD) | Maske-R-ANTIVIRUS | GNMT | Transformator | NCF |
| Rammeverk | TensorFlow | PyTorch | PyTorch | PyTorch | PyTorch | PyTorch |
Tabell 2: MLF Perf-ytelsestestene som brukes i evalueringen
| Plattform | PowerEdge R740 |
|---|---|
| CPU | 2 x Intel Xeon Gold 6136 ved 3,0 GHz (SkyLake) |
| Minne | 384 GB DDR4 ved 2666 MHz |
| Lagring | 782 TB Lustre |
| GPU | T4, V100-PCIe |
| Operativsystem og fastvare | |
| Operativsystem | Red Hat® Enterprise Linux® 7,5 x86_64 |
| Linux-kjerne | 3.10.0-693.el7.x86_64 |
| BIOS | 1.6.12 |
| Relatert til dyp læring | |
| CUDA-kompilator og GPU-driver | CUDA 10.0.130 (410,66) |
| CUDNN | 7.4.1 |
| NCCL | 2.3.7 |
| TensorFlow | kveldsbasert gpu-dev20190130 |
| PyTorch | 1.0.0 |
| MLPerf | V0.5 |
Tabell 3: Informasjon om maskinvarekonfigurasjon og programvare
Ytelsesevaluering
Figur 1 viser ytelsesresultatene til MLPerf på T4 og V100-PCIe på PowerEdge R740-serveren. Seks ytelsestest fra MLPerf er inkludert. For hver ytelsestest ble ende-til-ende-modellopplæringen utført for å nå nøyaktigheten til målmodellen definert av MLPerf-utvalget. Opplæringstiden i minutter ble registrert for hver ytelsestest. Følgende konklusjoner kan gjøres basert på disse resultatene:
-
ResNet-50 v1.5-, SSD- og Mask-R-MGM-modellene skaleres godt med et økende antall GPU-er. For ResNet-50 v1.5 er V100-PCIe 3,6 x raskere enn T4. For SSD er V100-PCI 3,3 x – 3,4 x raskere enn T4. V100-PCIe er 2,2 x – 2,7 x raskere enn T4 for Mask-R-PST. Med samme antall GPU-er tar hver modell nesten like mange epoks for å konvergere for T4 og V100-PCIe.
-
For GNMT-modellen ble den super lineære hastigheten observert når flere T4 GPU-er ble brukt. Sammenlignet med én T4, er hastighetsoppgangen 3,1 x med to T4, og 10,4 x med fire T4. Grunnen til dette er at modellkonvergensen påvirkes av det tilfeldige seedet som brukes til opplæring av initialisering av datafjerning og initialisering av nevrale nettverksvekter. Uansett hvor mange GPU-er som brukes, kan modellen, med ulike tilfeldige oppsparinger, trenge et annet antall epoks for konvergering. I dette forsøket tok modellen henholdsvis 12, 7, 5 og 4 epoks for å konvergere med henholdsvis 1, 2, 3 og 4 T4. Modellen brukte henholdsvis 16, 12 og 9 epoks til å konvergere med henholdsvis 1, 2 og 3 V100-PCIe. Siden antallet epoks er betydelig forskjellig selv med samme antall T4- og V100 GPU-er, kan ikke ytelsen sammenlignes direkte. I dette scenariet er gjennomstrømmingsmålingen en rimelig sammenligning, siden den ikke avhenger av det tilfeldige seedet. Figur 2 viser sammenligning av gjennomstrømningen for både T4 og V100-PCIe. Med samme antall GPU-er er V100-PCIe 2,5 x – 3,6 x raskere enn T4.
-
NCF-modellen og Transformer-modellen har samme problem som GNMT. For NCF-modellen er datasettstørrelsen liten, og modellen bruker ikke lang tid på å konvergere; dette problemet er derfor ikke åpenbart å legge merke til i resultatfiguren. Transformer-modellen har det samme problemet når én GPU brukes, ettersom modellen brukte 12 epoks for å konvergere med én T4, men det tok bare åtte ganger å konvergere med én V100-PCIe. Når to eller flere GPU-er brukes, tok modellen fire ganger for å konvergere uansett hvor mange GPU-er som brukes, eller hvilken GPU-type som brukes. V100-PCIe er 2,6 x – 2,8 x raskere enn T4 i slike tilfeller.
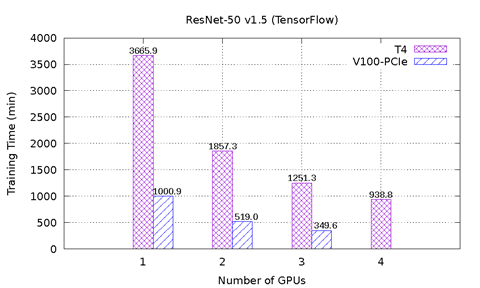
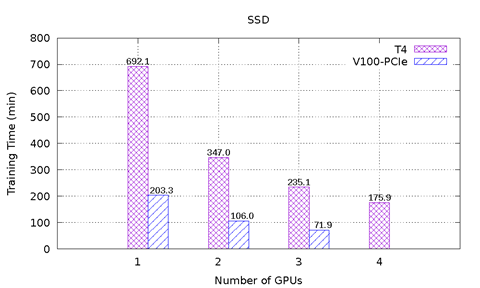
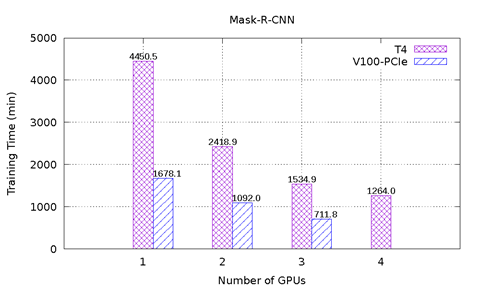

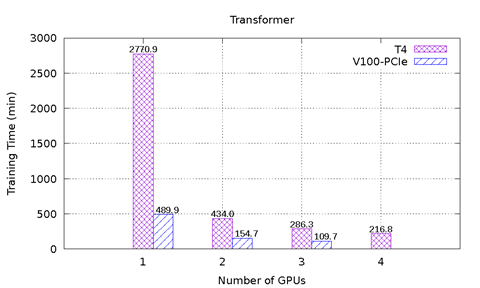

Figur 1: MLPerf-resultater på T4 og V100-PCIe

Figur 2: Sammenligning av gjennomstrømming for GNMT-modell
Konklusjoner og fremtidig arbeid
I denne bloggen evaluerte vi ytelsen til T4 GPU-er på Dell EMC PowerEdge R740-serveren ved hjelp av ulike MLPerf-ytelsestest. T4-ytelsen ble sammenlignet med V100-PCIe ved bruk av samme server og programvare. Totalt sett er V100-PCIe 2,2 x – 3,6 x raskere enn T4, avhengig av egenskapene til hver ytelsestest. Én observasjon er at noen modeller er stabile uansett hvilke tilfeldige seedverdier som brukes, men andre modeller, inkludert GNMT, NCF og Transformer, påvirkes sterkt av tilfeldige seedverdier. I fremtidig arbeid vil vi finjustere hyperparametrene for å få de ustabile modellene til å konvergere med mindre epoks. Vi vil også kjøre MLPerf på flere GPU-er og flere noder for å evaluere skalerbarheten til disse modellene på PowerEdge-servere.
*Ansvarsfraskrivelse: I forbindelse med ytelsestesting ble fire T4-GPU-er i Dell EMC PowerEdge R740 evaluert. Offisielt støtter PowerEdge R740 for øyeblikket maksimalt tre T4-er i x16 PCIe-spor.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000132094
Article Type: Solution
Last Modified: 24 Sep 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.