Výkon hlubokého učení u grafické karty T4 se srovnávacími testy MLPerf
Summary: Informace o architektuře Turing, která představuje nejnovější architekturu grafické karty NVIDIA po architektuře Volta a na které je založena nová karta T4. ...
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Článek napsali Rengan Xu, Frank Han a Quy Ta z oddělení HPC and AI Innovation Lab v březnu 2019
Cause
-
Resolution
Obsah:
Shrnutí
Architektura Turing je nejnovější architekturou grafické karty NVIDIA po architektuře Volta a je na ní založena nová karta T4. Byla navržena pro vysoce výkonné výpočetní prostředí (HPC), hluboké učení a odvozování, strojové učení, analýzu dat a grafiku. Na tomto blogu bude uveden výkon hlubokého učení grafických karet T4 na serveru Dell EMC PowerEdge R740 se sadou srovnávacích testů MLPerf. Výkon testů MLPerf u karty T4 bude také porovnán s kartou V100-PCIe na stejném serveru se stejným softwarem.
Přehled
Dell EMC PowerEdge R740 je rackový server 2U se 2 sockety. Systém obsahuje procesory Intel Skylake, až 24 modulů DIMM a až 3 grafické karty V100-PCIe s dvojnásobnou šířkou nebo 4 grafické karty T4 s jednoduchou šířkou ve slotech PCIe 3.0 x16. T4 je grafická karta, která využívá nejnovější architekturu Turing společnosti NVIDIA. Rozdíly ve specifikacích grafických karet T4 a V100-PCIe jsou uvedeny v tabulce 1. Test MLPerf byl vybrán pro vyhodnocení výkonu karty T4 v rámci hlubokého učení. MLPerf je nástroj pro srovnávací testy, který byl sestaven rozmanitou skupinou z akademické a průmyslové oblasti, do které patří například společnosti Google, Baidu, Intel, AMD, Harvard a Standford aj. Tento nástroj měří rychlost a výkon softwaru a hardwaru strojového učení. První vydanou verzí je v0.5, která zahrnuje implementace modelů v různých doménách strojového učení, včetně klasifikace obrazu, zjišťování a segmentace objektů, strojového překladu a strojového učení. Souhrn srovnávacích testů MLPerf používaných pro toto hodnocení je uveden v tabulce 2. Byla použita implementace ResNet-50 TensorFlow poskytnutá společností Google a implementace všech ostatních modelů poskytnutých společností NVIDIA. Všechny srovnávací testy byly spuštěny na holém fyzickém zařízení bez kontejneru. Tabulka 3 obsahuje seznam hardwaru a softwaru použitého k vyhodnocení. Výkon karty T4 ve srovnávacím testu MLPerf bude porovnán s kartou V100-PCIe.
| Tesla V100-PCIe | Tesla T4 | |
|---|---|---|
| Architektura | Volta | Turing |
| Jádra CUDA | 5120 | 2560 |
| Jádra Tensor | 640 | 320 |
| Výpočetní schopnost | 7.0 | 7.5 |
| Taktovací frekvence grafické karty | 1245 MHz | 585 MHz |
| Zvýšená taktovací frekvence | 1 380 MHz | 1 590 MHz |
| Typ paměti | HBM2 | GDDR6 |
| Velikost paměti | 16 GB/32 GB | 16 GB |
| Šířka pásma | 900 GB/s | 320 GB/s |
| Šířka slotu | Dva sloty | Jeden slot |
| Jednoduchá přesnost (FP32) | 14 TFLOPS | 8,1 TFLOPS |
| Kombinovaná přesnost (FP16/FP32) | 112 TFLOPS | 65 TFLOPS |
| Dvojitá přesnost (FP64) | 7 TFLOPS | 254,4 GFLOPS |
| TDP | 250 W | 70 W |
Tabulka 1: Srovnání karet T4 a V100-PCIe
| Klasifikace obrazu | Klasifikace objektů | Segmentace instancí objektů | Překlad (opakující se) | Překlad (neopakující se) | Doporučení | |
|---|---|---|---|---|---|---|
| Data | ImageNet | COCO | COCO | WMT E-G | WMT E-G | MovieLens-20M |
| Velikost dat | 144 GB | 20 GB | 20 GB | 37 GB | 1,3 GB | 306 MB |
| Model | ResNet-50 v1.5 | Single-Stage Detector (SSD) | Mask-R-CNN | GNMT | Transformer | NCF |
| Rámec | TensorFlow | PyTorch | PyTorch | PyTorch | PyTorch | PyTorch |
Tabulka 2: Srovnávací testy MLF Perf použité k vyhodnocení
| Platforma | PowerEdge R740 |
|---|---|
| CPU | 2x Intel Xeon Gold 6136 při frekvenci 3 GHz (SkyLake) |
| Paměť | 384 GB DDR4 s rychlostí 2 666 MHz |
| Úložiště | 782 TB Luster |
| GPU | T4, V100-PCIe |
| Operační systém a firmware | |
| Operační systém | Red Hat® Enterprise Linux® 7.5 x86_64 |
| Jádro systému Linux | 3.10.0-693.el7.x86_64 |
| BIOS | 1.6.12 |
| Související s hlubokým učením | |
| Kompilátor CUDA a ovladač grafické karty | CUDA 10.0.130 (410.66) |
| CUDNN | 7.4.1 |
| NCCL | 2.3.7 |
| TensorFlow | nightly-gpu-dev20190130 |
| PyTorch | 1.0.0 |
| MLPerf | V0.5 |
Tabulka 3: Podrobnosti o konfiguraci hardwaru a softwaru
Vyhodnocení výkonu
Obrázek 1: znázorňuje výsledky výkonu karty T4 a V100-PCIe v testu MLPerf na serveru PowerEdge R740. Obsahuje šest srovnávacích testů z nástroje MLPerf. U každého srovnávacího test bylo provedeno komplexní učení, aby bylo dosaženo cílové přesnosti definované výborem MLPerf. U každého srovnávacího testu byl zaznamenán čas učení v minutách. Na základě těchto výsledků lze učinit následující závěry:
-
Modely ResNet-50 v1.5, SSD a Mask-R-CNN se dobře škálují se zvyšujícím počtem grafických karet. V případě modelu ResNet-50 v1.5 je karta V100-PCIe 3,6x rychlejší než karta T4. V případě modelu SSD je karta V100-PCI 3,3–3,4x rychlejší než karta T4. V případě modelu Mask-R-CNN je karta V100-PCIe 2,2–2,7x rychlejší než karta T4. Se stejným počtem grafických karet T4 a V100-PCIe vyžaduje konvergování u každého modelu téměř stejný počet cyklů.
-
V případě modelu GNMT došlo k superlineárnímu zrychlení, když bylo použito více grafických karet T4. Ve srovnání s jednou kartou T4 je rychlost 3,1x větší v případě dvou karet T4 a 10,4x větší v případě čtyř karet T4. Je to proto, že konvergenci modelu ovlivňuje náhodný prvek Seed, který se používá k míchání dat při učení a inicializaci zatížení neuronových sítí. Bez ohledu na to, kolik grafických karet se používá, v případě různých náhodných prvků Seed může model ke konvergování potřebovat různý počet cyklů. V tomto experimentu model ke konvergování 1, 2, 3 a 4 karet T4 potřeboval 12, 7, 5 a 4 cykly. Ke konvergování 1, 2 a 3 karet V100-PCIe potřeboval model 16, 12 a 9 cyklů. Vzhledem k tomu, že se počet cyklů výrazně liší i v případě stejného počtu grafických karet T4 a V100, výkon nelze přímo porovnat. V tomto scénáři k vhodnému porovnání slouží metrika propustnosti, protože ta nezávisí na náhodných prvcích Seed. Obrázek 2 znázorňuje porovnání propustnosti karet T4 a V100-PCIe. Se stejným počtem grafických karet je karta V100-PCIe 2,5–3,6x rychlejší než karta T4.
-
Model NCF a Transformer se potýkají se stejným problémem jako model GNMT. U modelu NCF je velikost datové sady malá a konvergování netrvá dlouho, proto tento problém není ve výsledku zřejmý. Model Transformer má při použití jedné grafické karty stejný problém, jelikož konvergování s jednou kartou T4 vyžadovalo 12 cyklů, ale konvergování s jednou kartou V100-PCIe vyžadovalo 8 cyklů. Při použití dvou nebo více grafických karet model potřeboval na konvergování 4 cykly, bez ohledu na to, kolik se použilo grafických karet nebo jaké typy karet. V těchto případech je karta V100-PCIe 2,6–2,8x rychlejší než karta T4.
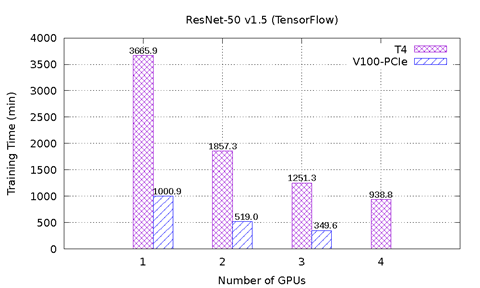
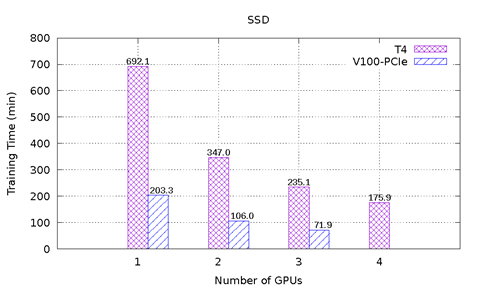
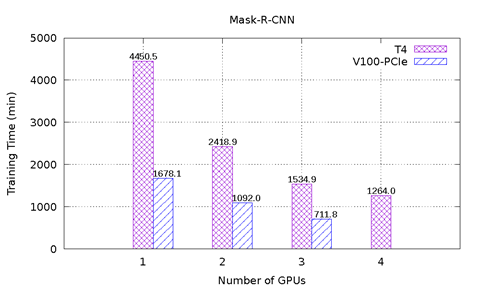
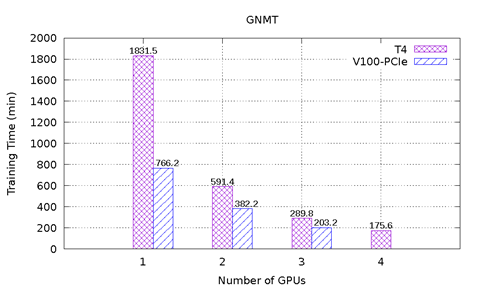

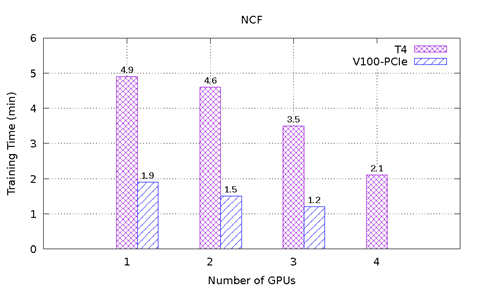
Obrázek 1: Výsledky karet T4 a V100-PCIe v nástroji MLPerf

Obrázek 2: Porovnání propustnosti v případě modelu GNMT
Závěry a budoucí práce
Na tomto blogu jsme vyhodnotili výkon grafických karet T4 v serveru Dell EMC PowerEdge R740 pomocí různých srovnávacích testů MLPerf. Výkon karty T4 byl porovnán s kartou V100-PCIe za použití stejného serveru a softwaru. V závislosti na charakteristice jednotlivých srovnávacích testů je karta V100-PCIe celkově 2,2–3,6x rychlejší než karta T4. Jedním poznatkem je, že některé modely jsou stabilní, bez ohledu na to, jaké hodnoty náhodných prvků Seed jsou použity, ale další modely, včetně GNMT, NCF a Transformer, jsou náhodnými prvky Seed výrazně ovlivňovány. V budoucnu doladíme hyperparametry, aby nestabilní modely mohly provádět konvergování za pomoci méně cyklů. Nástroj MLPerf také spustíme u více grafických karet a dalších uzlů, abychom vyhodnotili škálovatelnost těchto modelů na serverech PowerEdge.
* Zřeknutí se odpovědnosti: Pro účely srovnávání byly použity čtyři grafické karty T4 v serveru Dell EMC PowerEdge R740. V současné době server PowerEdge R740 oficiálně podporuje maximálně tři karty T4 ve slotech PCIe x16.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000132094
Article Type: Solution
Last Modified: 24 Sep 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.