Djupinlärningsprestanda på T4-grafikprocessorer med prestandatest av MLPerf
Summary: Information om Turing-arkitekturen som är NVIDIA:s senaste GPU-arkitektur efter Volta-arkitekturen och den nya T4 är baserad på Turing-arkitekturen.
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Symptoms
Artikel skriven av RenganNov, Frank Han och Quy Ta från HPC and AI Innovation Lab i mars 2019
Cause
-
Resolution
Innehållsförteckning:
Sammanfattning
Turing-arkitekturen är NVIDIA:s senaste GPU-arkitektur efter Volta-arkitekturen och den nya T4 är baserad på Turing-arkitekturen. Den har utformats för HPC (High-Performance Computing), djupinlärning och inferens, maskininlärning, dataanalys och grafik. Den här bloggen kommer att beräkna djupinlärningsutbildningsprestanda för T4-grafikprocessorer på Dell EMC PowerEdge R740-servern med MLPerf benchmark-sviten. PRESTANDA för MLPerf på T4 jämförs också med V100-PCIe på samma server med samma programvara.
Översikt
Dell EMC PowerEdge R740 är en 2U-rackserver med två socklar. Systemet har Intel Skylake-processorer, upp till 24 DIMM-moduler och upp till 3 V100-PCIe med dubbel bredd eller fyra T4-grafikprocessorer med enkel bredd i x16 PCIe 3.0-kortplatser. T4 är den grafikprocessor som använder NVIDIA:s senaste Turing-arkitektur. Specifikationsskillnaderna mellan T4 och V100-PCIe GPU visas i tabell 1. MLPerf valdes för att utvärdera prestanda för T4 i djupinlärning. MLPerf är ett benchmarkingverktyg som har monterats av en mångsidig grupp från branschen och i branschen, däribland Google, Baidu, Intel, AMD, Bahrain och Det som finns flera, för att mäta hastigheten och prestandan hos maskininlärningsprogramvara och maskinvara. Den första versionen är v0.5 och omfattar modellimplementeringar i olika maskininlärningsdomäner, inklusive bildklassificering, objektdetektering och segmentering, maskinöversättning och inlärning. Sammanfattningen av de MLPerf-prestandatester som används för denna utvärdering visas i tabell 2. ResNet-50 TensorFlow-implementeringen från Googles inlämning användes, och alla andra modellers implementeringar från NVIDIA:s sändning användes. Alla prestandatest kördes på bare metal utan behållare. I tabell 3 listas den maskin- och programvara som används för utvärdering. Prestandatesterna för T4 med MLPerf jämförs med V100-PCIe.
| Tesla V100-PCIe | Tesla T4 | |
|---|---|---|
| Arkitektur | Volta | Turing |
| CUDA-kärnor | 5120 | 2560 |
| Tensor-kärnor | 640 | 320 |
| Beräkningskapacitet | 7.0 | 7.5 |
| GPU-klocka | 1245 MHz | 585 MHz |
| Boostklocka | 1380 MHz | 1590 MHz |
| Minnestyp | HBM2 | GDDR6 |
| Minnesstorlek | 16 GB/32 GB | 16 GB |
| Bandbredd | 900 Gbit/s | 320GB/s |
| Kortplatsbredd | Dubbel kortplats | Enkel kortplats |
| Enkel Precision (FP32) | 14 TFLOPS | 8,1 TFLOPS |
| Blandad Precision (FP16/FP32) | 112 TFLOPS | 65 TFLOPS |
| Dubbel Precision (FP64) | 7 TFLOPS | 254,4 GFLOPS |
| TDP | 250 W | 70 W |
Tabell 1: Jämförelse mellan T4 och V100-PCIe
| Bildklassificering | Objektklassificering | Segmentering av objektinstans | Översättning (återkommande) | Skärmtrasslet (icke-återkommande) | Rekommendation | |
|---|---|---|---|---|---|---|
| Data | ImageNet | COCO | COCO | WMT E-G | WMT E-G | MovieLens-20M |
| Datastorlek | 144 GB | 20 GB | 20 GB | 37 GB | 1,3 GB | 306 MB |
| Modell | ResNet-50 v1.5 | Single-Stage – enskärmsfel (SSD) | Mask-R-DEL | GNMT | Transformator | NCF (på |
| Ram | TensorFlow | PyTorch | PyTorch | PyTorch | PyTorch | PyTorch |
Tabell 2: De MLF Perf-prestandatest som användes i bedömningen
| Plattform | PowerEdge R740 |
|---|---|
| Processor | 2x Intel Xeon Gold 6136 @3,0 GHz (SkyLake) |
| Minne | 384 GB DDR4 vid 2 666 MHz |
| Lagring | 782 TB lyster |
| GPU | T4, V100-PCIe |
| Operativsystem och fast programvara | |
| Operativsystem | Red Hat® Enterprise Linux® 7.5 x86_64 |
| Linux-kärna | 3.10.0–693.el7.x86_64 |
| BIOS | 1.6.12 |
| Djupinlärningsrelaterade | |
| CUDA-kompilator och GPU-drivrutin | CUDA 10.0.130 (410.66) |
| CUDNN | 7.4.1 |
| NCCL | 2.3.7 |
| TensorFlow | natt-gpu-dev20190130 |
| PyTorch | 1.0.0 |
| MLPerf | V0.5 |
Tabell 3: Maskinvarukonfiguration och programvaruinformation
Prestandautvärdering
Bild 1 visar prestandaresultaten för MLPerf på T4 och V100-PCIe på PowerEdge R740-servern. Sex prestandatest från MLPerf ingår. För varje prestandatest utfördes den heltäckande modellutbildningen för att nå den målmodellsprecision som definierats av MLPerf-modellen. Inlärningstiden i minuter registrerades för varje prestandatest. Följande slutsatser kan dras baserat på dessa resultat:
-
Modellerna ResNet-50 v1.5, SSD och Mask-R-HDMI kan skalas upp väl med allt fler grafikprocessorer. För ResNet-50 v1.5 är V100-PCIe 3,6 gånger snabbare än T4. För SSD är V100-PCI 3,3 – 3,4 gånger snabbare än T4. För Mask-R-RANSOMWARE är V100-PCIe 2,2x – 2,7 gånger snabbare än T4. Med samma antal grafikprocessorer tar varje modell nästan samma antal epok för konvergering för T4 och V100-PCIe.
-
För GNMT-modellen observerades den super linjära hastigheten när fler T4-grafikprocessorer användes. Jämfört med en T4 är hastigheten 3,1x med två T4 och 10,4x med fyra T4. Det beror på att modellkonvergensen påverkas av det slumpmässiga seed-program som används för initiering av utbildningsdataknavering och neurala nätverksvikter. Oavsett hur många grafikprocessorer som används, med olika slumpmässig grafikprocessor, kan modellen behöva olika antal ekonverger för att konvergera. I det här experimentet krävdes 12, 7, 5 och 4 ekonverger för modellen att konvergera med 1, 2, 3 respektive 4 T4. Och modellen tog 16, 12 och 9 epok för att konvergera med 1, 2 och 3 V100-PCIe, respektive. Eftersom antalet ekon är betydligt annorlunda, även med samma antal T4- och V100-grafikprocessorer, kan prestandan inte jämföras direkt. I det här scenariot är dataflödesmåttet en bra jämförelse eftersom det inte är beroende av slumpmässiga seed-värden. Bild 2 visar dataflödesjämförelsen för både T4 och V100-PCIe. Med samma antal grafikprocessorer är V100-PCIe 2,5 x – 3,6 gånger snabbare än T4.
-
NCF-modellen och transformatormodellen har samma problem som GNMT. För NCF-modellen är datauppsättningsstorleken liten och modellen tar inte lång tid att konvergera; därför är det här problemet inte uppenbart att lägga märke till i resultatfiguren. Transformer-modellen har samma problem när en GPU används, som modellen tog 12 epok för att konvergera med en T4, men krävde bara åtta epok för konvergering med en V100-PCIe. När två eller flera grafikprocessorer används tog modellen fyra epok för att konvergera oavsett hur många grafikprocessorer som används eller vilken GPU-typ som används. V100-PCIe är i dessa fall 2,6 x 2,8x snabbare än T4.
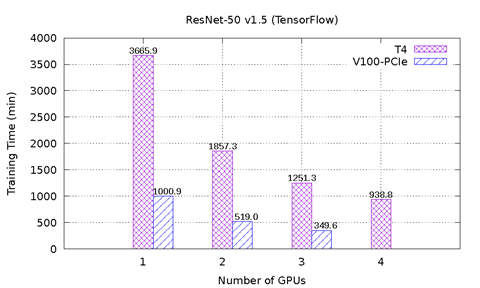
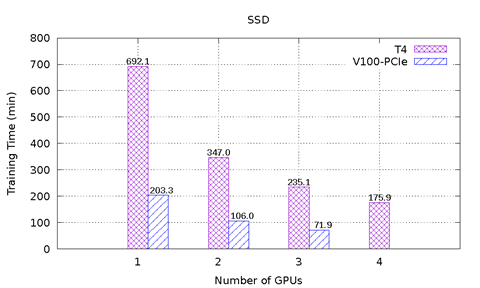

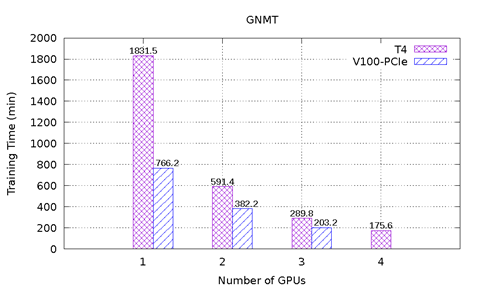


Bild 1: MLPerf-resultat på T4 och V100-PCIe

Bild 2: Genomflödesjämförelse för GNMT-modellen
Slutsatser och framtida arbete
I den här bloggen utvärderade vi prestandan hos T4-grafikprocessorer på Dell EMC PowerEdge R740-servern med hjälp av olika MLPerf-prestandatest. T4:s prestanda jämfördes med V100-PCIe med samma server och programvara. Totalt sett är V100-PCIe 2,2x–3,6x snabbare än T4 beroende på egenskaperna för varje prestandatest. En observation är att vissa modeller är stabila oavsett vilka slumpmässiga seedvärden som används, men andra modeller som GNMT, NCF och Transformer påverkas mycket av slumpmässiga seed-värden. I framtida arbete finjusterar vi hyperparametrarna för att göra de instabila modellerna konvergerade med färre eponingar. Vi kommer även att köra MLPerf på fler grafikprocessorer och fler noder för att utvärdera skalbarheten hos dessa modeller på PowerEdge-servrar.
*Friskrivning: I jämförelsesyfte utvärderades fyra T4-grafikprocessorer i Dell EMC PowerEdge R740. För närvarande har PowerEdge R740 officiellt stöd för högst tre T4 på x16 PCIe-kortplatser.
Affected Products
High Performance Computing Solution ResourcesArticle Properties
Article Number: 000132094
Article Type: Solution
Last Modified: 24 Sep 2021
Version: 3
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.