PowerEdge:AMD Rome — 体系结构和初始 HPC 性能
Summary: 在当今的 HPC 世界中,介绍 AMD 最新一代 EPYC 处理器 代号命名为 Rome。
This article applies to
This article does not apply to
This article is not tied to any specific product.
Not all product versions are identified in this article.
Instructions
Garima Kochhar, Deepthi Cherlopalle, Joshua Weage。HPC 和 AI 创新实验室,2019 年 10 月
在当今的 HPC 世界中,无需介绍 AMD 最新一代EPY 处理器 代号命名为 Rome 。过去几个月里,我们一直在 HPC 和 AI 创新实验室
中评估基于 Rome 的系统,并且 Dell Technologies 最近宣布
推出支持该处理器架构的服务器。Rome 系列的第一篇博文讨论了 Rome 处理器架构、如何针对 HPC 性能进行调整,并展示了初步的微基准测试性能。后续的博客介绍了 CFD、CAE、分子动力学、天气模拟和其他应用领域的应用程序性能。
体系结构
Rome 是 AMD 的第二代 EPYC CPU,是对其第一代 Naples 处理器的更新换代。
Naples 和 Rome 之间最大的架构差异之一便是 Rome 的新 IO 芯片,此差异为 HPC 带来了显著优势。在 Rome 中,每个处理器都是一个多芯片封装,由多达九个小芯片组成,如图 1 所示。中央是一颗 14 纳米 IO 芯片,它集成了所有 IO 和内存功能 — 例如,内存控制器、插槽内 Infinity Fabric 链路和插槽间连接,以及 PCI-e。每个插槽中有八个内存控制器,支持八个内存通道,可运行速度为 3200 MT/s 的 DDR4 内存。单路服务器可支持多达 130 个 PCIe Gen4 通道。双路系统可支持多达 160 个 PCIe Gen4 通道。
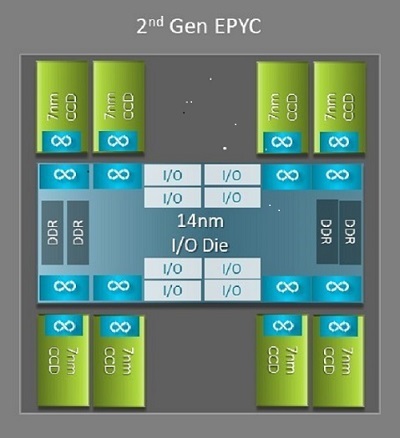
(图 1 Rome 多芯片封装,包含一颗中央 IO 芯片和多达八颗核心芯片)
环绕在中央 IO 芯片的是多达八颗 7 纳米核心小芯片。核心小芯片称为核心缓存芯片 (CCD)。每个 CCD 都具有多个基于 Zen2 微架构的 CPU 核心、L2 高速缓存和 32 MB L3 高速缓存。CCD 本身有两个核心缓存复合体 (CCX),每个 CCX 有多达四个核心和 16MB 的 L3 高速缓存。图 2 显示了 CCX。

(图 2 一个具有四个核心和 16MB 共享 L3 高速缓存的 CCX)
不同的 Rome CPU 型号 具有不同数量的核心,
但都有一个中央 IO 芯片。
最高端的是 64 核 CPU 型号,例如 EPYC 7702。Lstopo 输出向我们展示,此处理器每个插槽有 16 个 CCX,每个 CCX 有四个核心,如图 3 和图 4 所示,因此每个插槽产生 64 个核心。每个 CCX 的 16 MB L3(即,每个 CCD 为 32 MB L3)为此处理器提供了 256 MB L3 高速缓存。但是请注意,Rome 中的总 L3 缓存并非由所有核心共享。每个 CCX 中的 16 MB L3 高速缓存是独立的,并且仅由 CCX 中的核心共享,如图 2 所示。
24 核 CPU(如 EPYC 7402)具有 128 MB L3 高速缓存。图 3 和 4 中的 Lstopo 输出展示出此型号每个 CCX 有三个核心,每个插槽有八个 CCX。
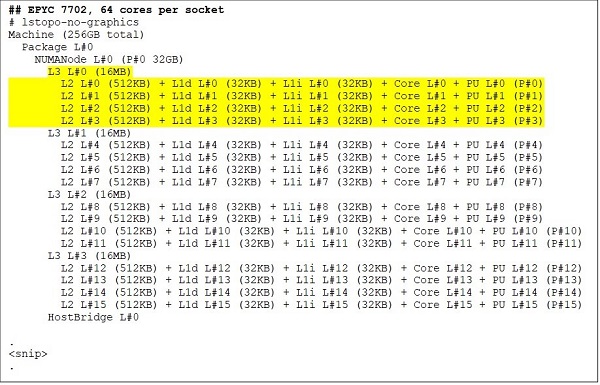
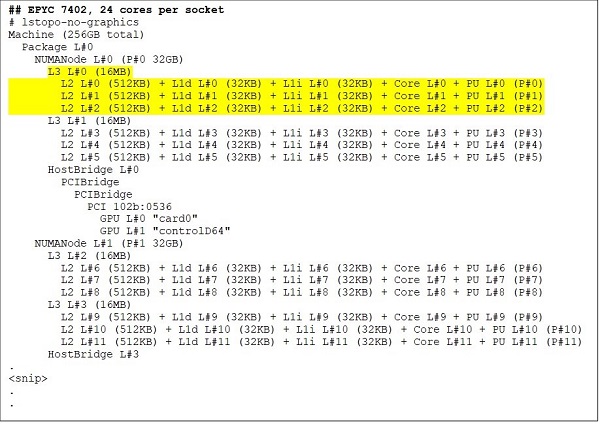
(图 3 & 4:64 核和 24 核 CPU 的 Lstopo 输出)
无论 CCD 的数量如何,每个 Rome 处理器在逻辑上都被分为四个象限,CCD 尽可能均匀地分布在这些象限中,每个象限有两个内存通道。中央 IO 芯片可以被视为在逻辑上支持插槽的四个象限。
基于 Rome 体系结构的 BIOS 选项
Rome 的中央 IO 芯片有助于降低内存延迟,使其表现优于 Naples。该功能还允许 CPU 配置为单个 NUMA 域,从而为插槽中的所有内核提供统一的内存访问。这将在下文进行说明。
Rome 处理器中的四个逻辑象限允许将 CPU 分区到不同的 NUMA 域中。此设置称为每个插槽的 NUMA 或 NPS。
- NPS1 意味着 Rome CPU 是一个单独的 NUMA 域,插槽中的所有核心和所有内存都归属此 NUMA 域。跨八个内存通道交叉存取。插槽上的所有 PCIe 设备都属于此单个 NUMA 域
- NPS2 会将 CPU 划分为两个 NUMA 域,每个 NUMA 域都有插槽上的一半核心和一半内存通道。跨每个 NUMA 域中的四个内存通道交叉存取内存
- NPS4 将 CPU 划分为四个 NUMA 域。在此模式下,每个象限都是一个 NUMA 域,并且内存会在每个象限中的两个内存通道之间进行交错。PCIe 设备在本地归属于插槽上的四个 NUMA 域之一,具体取决于设备的 PCIe 根位于 IO 芯片的哪个象限
- 并非所有 CPU 都支持所有 NPS 设置。
在可用的情况下,建议对 HPC 应用 NPS4,因为预计该模式能提供最佳内存带宽、最低的内存延迟,并且我们的应用程序也往往具备 NUMA 感知能力。NPS4 不可用时,我们建议使用 CPU 型号支持的最高 NPS—NPS2,甚至 NPS1。
鉴于基于 Rome 的平台提供了多种 NUMA 选项,PowerEdge BIOS 在 MADT 枚举下提供了两种不同的核心枚举方法。线性枚举按顺序对核心进行编号,在移动到下一个插槽之前,先填充一个 CCX、CCD、插槽。32c CPU 中,核心 0 至 31 位于第一个插槽,核心 32 至 63 位于第二个插槽。循环枚举跨 NUMA 区域对核心进行编号。在这种情况下,偶数核心位于第一个插槽上,奇数编号核心位于第二个插槽上。为简便起见,我们建议对 HPC 进行线性枚举。在 NPS4 中配置的双路 64c 服务器上的线性核心枚举示例,请参阅图 5。在下图中,每个由四个核心组成的方框表示一个 CCX,每组八个连续的核心表示一个 CCD。
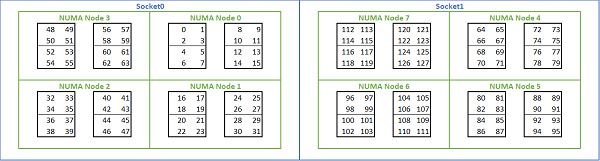
(图 5 双路系统上的线性核心枚举,每个插槽 64 个核心,八 CCD CPU 型号上的 NPS4 配置)
Rome 特定的另一个 BIOS 选项称为 Preferred IO Device。这是 InfiniBand 带宽和消息速率的重要调节旋钮。它允许平台为一个 IO 设备确定流量的优先级。单路和双路 Rome 平台上提供此选项,必须在 BIOS 菜单中选择平台中的 InfiniBand 设备作为首选设备,才能在所有 CPU 内核都处于活动状态时实现全消息速率。
与 Naples 类似,Rome 也支持超线程 或逻辑处理器。对于 HPC,我们将其保留为禁用状态,但某些应用程序可以从启用逻辑处理器中受益。查看我们后续有关分子动力学应用研究的博客。
与 Naples 类似,Rome 也支持 CCX as NUMA Domain。该选项将每个 CCX 公开为 NUMA 节点。在每个 CPU 有 16 个 CCX 的双路 CPU 系统上,此设置会公开 32 个 NUMA 域。在本示例中,每个插槽有八个 CCD,即 16 个 CCX。每个 CCX 都可以作为自己的 NUMA 域启用,从而在双路系统中为每个插槽提供 16 个 NUMA 节点和 32 个 NUMA 节点。对于 HPC,我们建议将 CCX 保留为 NUMA Domain,默认选项为“已禁用”。启用此选项有望帮助虚拟化环境。
与 Naples 类似,Rome 允许将系统设置为性能确定论或功率确定论模式。在性能确定论中,系统以 CPU 模型的预期频率运行,从而减少多个服务器之间的可变性。在功率确定论中,系统以 CPU 模型的最大可用 TDP 运行。这放大了制造过程中部件与部件之间的差异,使得某些服务器的运行速度比其他服务器更快。所有服务器都可能以 CPU 的最大额定功率运行,这使得功耗具有确定性,但也允许多个服务器之间存在一定的性能差异。
熟悉 PowerEdge 平台的用户都知道,BIOS 中有一个名为 System Profile 的元选项。选择 Performance-Optimized 系统配置文件可启用睿频加速模式、禁用 C 状态,并将确定性滑块设置为“Power Determinism”以优化性能。
性能结果 — STREAM、HPL、InfiniBand 微基准测试
考虑到许多读者可能会直接跳到本部分,因此我们便不再赘述,直接进入正题。
在 HPC 和 AI 创新实验室中,我们构建了一个基于 Rome 的群集。该群集拥有 64 台服务器,我们将其称为 Minerva。同构 Minerva 群集之外,我们还有一些其他 Rome CPU 示例可供评估。表 1 和表 2 介绍了我们的测试平台。
(表 1 本研究中评估的 Rome CPU 型号)
| CPU | 每个插槽的核心数 | 配置 | 基本时钟 | TDP |
|---|---|---|---|---|
| 7702 | 64c | 每个 CCX 有 4 个核心 | 2.0 GHz | 200W |
| 7502 | 32c | 每个 CCX 有 4 个核心 | 2.5 GHz | 180W |
| 7452 | 32c | 每个 CCX 有 4 个核心 | 2.35 GHz | 155W |
| 7402 | 24c | 每个 CCX 有 3 个核心 | 2.8 GHz | 180W |
(表 2 测试平台)
| 组件 | 详细信息 |
|---|---|
| 服务器 | PowerEdge C6525 |
| 处理器 | 如表 1 双插槽所示 |
| 内存 | 256 GB,16 根 16 GB 3200 MT/s DDR4 内存条 |
| 互连 | ConnectX-6 Mellanox Infini Band HDR100 |
| 操作系统 | Red Hat Enterprise Linux 7.6 |
| 内核 | 3.10.0.957.27.2.e17.x86_64 |
| 磁盘 | 240 GB SATA SSD M.2 模块 |
STREAM
Rome 上的内存带宽测试如图 6 所示。这些测试在 NPS4 模式下运行。我们使用表 1 中列出的四种 CPU 型号,并在服务器中使用所有核心的情况下,在我们的双路 PowerEdge C6525 服务器上测得了约 270-300 GB/s 的内存带宽。每个 CCX 仅使用一个核心时,系统内存带宽比所有核心测得的带宽高~9-17%。
通常情况下,HPC 工作负载完全占用系统中的所有核心,或者 HPC 中心以高吞吐量模式运行,每个服务器上都有多个作业。因此,全核心内存带宽能够更准确地表示系统的内存带宽和每核心内存带宽能力。
图 6 还绘制了上一代 EPYC Naples 平台上测量的内存带宽。该平台还支持每个插槽八个内存通道,但运行速度为 2667 MT/s。与 Naples 相比,Rome 平台的总内存带宽提高了 5%到 19%,这主要归功于其更快的 3200 MT/s 内存速度。即使在每个插槽 64 个核心的情况下,Rome 系统也可提供高达每个核心 2 Gb/s 的性能。
提醒:在多台基于 Rome 且配置完全相同的服务器上测得的 STREAM Triad 结果性能差异为 5-10%,以下结果应假定为该范围的最高值。
与不同的 NPS 配置进行比较,NPS4 的内存带宽比 NPS1 高~13%,如图 7 所示。
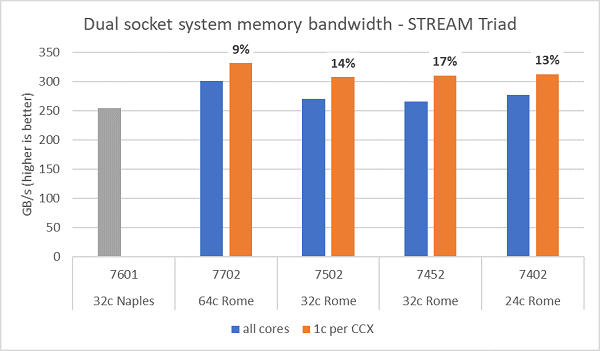
(图 6 双路 NPS4 STREAM Triad 内存带宽)
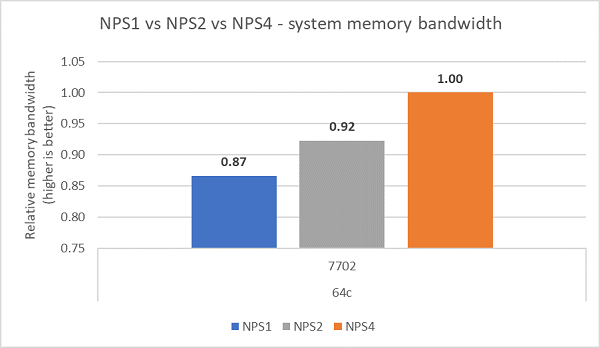
(图 7 NPS1、NPS2 以及 NPS 4 的内存带宽对比)
InfiniBand 带宽和消息速率
图 8 绘制了用于单向和双向测试的单核 InfiniBand 带宽。测试平台使用以 100 Gbps 运行的 HDR100,并且该图表显示了这些测试的预期线速性能。

图 8 InfiniBand 带宽(单核))

(图 9 InfiniBand 消息速率(所有核心))
接下来,对两台受测服务器的每个插槽上的所有核心进行了消息速率测试。在 BIOS 中启用了“Preferred IO”并且 ConnectX-6 HDR100 适配器配置为首选设备时,全核心消息速率高于未启用“Preferred IO”的情况,如图 9 所示。这说明了此 BIOS 选项在针对 HPC 进行调整时的重要性,尤其是对多节点应用程序可扩展性的重要性。
HPL
Rome 微架构每周期可执行 16 次 DP FLOP 运算,性能是每周期执行 8 次 FLOP 运算的 Naples 的两倍。这使得 Rome 在理论峰值 FLOPS 上达到了 Naples 的 4 倍。这一提升由两部分构成:2 倍来自增强的浮点计算能力,另外 2 倍来自核心数量翻倍(64 核对32 核)。图 10 显示了我们测试的四个 Rome CPU 型号的 HPL 测得结果,以及之前从基于 Naples 的系统中获得的结果。Rome 的 HPL 效率以图表的条形上方的百分比值表示,TDP 较低的 CPU 型号其 HPL 效率较高。
测试是在“Power Determinism”模式下运行的,并且在 64 台配置完全相同的服务器上测得的性能差异约为 5%,因此这里的结果处于该性能范围内。
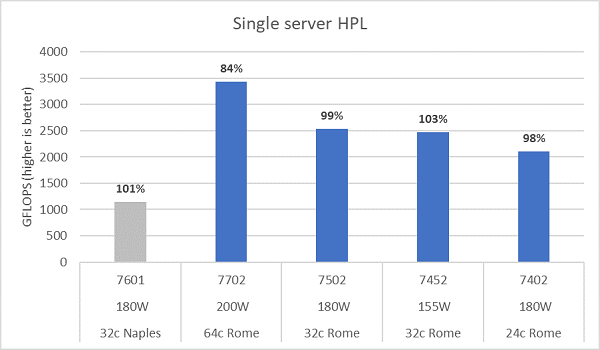
(图 10 NPS4 中的单服务器 HPL)
接下来执行了多节点 HPL 测试,这些结果如图 11 所示。在 64 节点规模下,EPYC 7452 的 HPL 效率仍保持在 90% 以上,但效率从 102% 下降到 97% 再上升到 99%,因此还需要进一步评估。
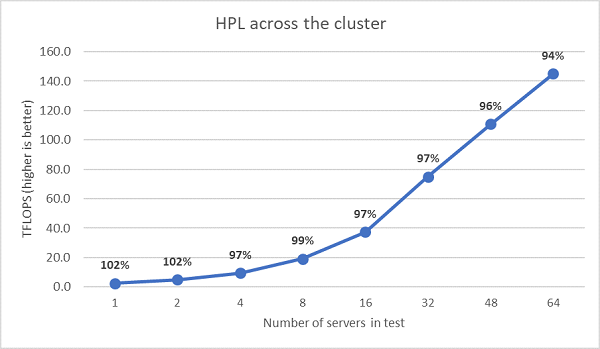
(图 11 多节点 HPL,双路 EPYC 7452 通过 HDR100 InfiniBand)
总结与展望:
在基于 Rome 的服务器上进行的初始性能研究显示了我们的第一组 HPC 基准测试的预期性能。在配置以获得最佳性能时,BIOS 调整非常重要。我们的 BIOS HPC 工作负载配置文件中提供了调整选项,可以在出厂时配置或使用 Dell EMC 系统管理实用程序进行设置。
HPC 和 AI 创新实验室 拥有一个基于 Rome 的全新 PowerEdge 群集 Minerva,该群集包含 64 台服务器。请关注后续博客,我们将详细介绍我们新群集 Minerva 的应用性能研究。
Affected Products
Mellanox Family of Adapters, PowerEdge C6525, PowerEdge C6615, PowerEdge R6515, PowerEdge R6525, PowerEdge R6615, PowerEdge R6625, PowerEdge R6715, PowerEdge R6725, PowerEdge R7515, PowerEdge R7525, PowerEdge R7615, PowerEdge R7625, PowerEdge R7715
, PowerEdge R7725, PowerEdge R7725xd
...
Article Properties
Article Number: 000137696
Article Type: How To
Last Modified: 16 Oct 2025
Version: 11
Find answers to your questions from other Dell users
Support Services
Check if your device is covered by Support Services.